はじめに
このコースでは、高位合成を活用したアクセラレータ開発に関して、その考え方やフローを、事例を交えながら解説していきます。今回は、浮動小数点行列の積を計算するシストリックアレイの実装を紹介します。
まずは行列積についておさらいします。行列 A、B を1024行、1024列の行列とします。
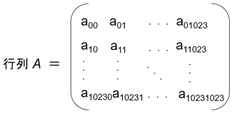
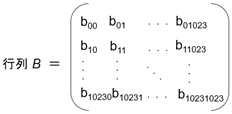
行列 A、B の行列積を C とします。C も1024行、1024列の行列です。C のそれぞれの要素は A の行ベクトルと B の列ベクトルの内積となり、次の式で表されます。
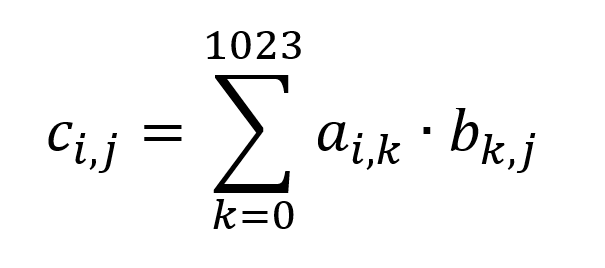
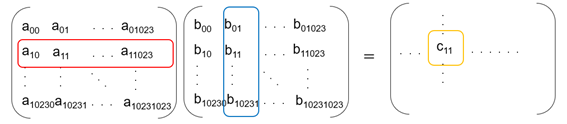
行列 C の 成分 c11 を例に図示すると、c11 は赤線で囲った行ベクトルと青線で囲った列ベクトルの内積となります。
行列 C のひとつの成分を計算するのに1024回の積和演算 (MAC / multiply-accumulate) が必要となりますので、すべての要素を計算するには、1024 * 1024^2 = 1,073,741,824回 (ざっと10億回) の積和演算が必要となります。およそ10G MACの計算量とも表現できます。
行列積を効率的に実行する演算器の構成方法のひとつにシストリックアレイがあります。シストリックアレイは、同一の動きをする多数の Processing Element (以下、PE) を同期動作させ、パイプライン処理と並列処理を組み合わせた構造をもつ大規模並列処理用のコンピュータアーキテクチャです。ここでは簡単にするために各 PE で1行1列分を処理する二次元構造にします。
実装の準備
実現性を検討するにあたってターゲット FPGA のリソースを確認します。
今回は ZCU102 ボードで動作させることを目標とします。ZCU102 ボードに搭載されている ZU9EG のロジックサイズ、BRAM 容量、DSP スライス数を、ザイリンクスのホームページからダウンロードできるプロダクトセレクションガイドで確認します。
| LUT | 274K |
| BRAM | 32.1Mb (4MB) |
| DSP スライス | 2,520 |
行列 A, B それぞれを BRAM に格納して演算し、結果の行列 C を BRAM に格納すると仮定した場合に必要となる BRAM 容量は、(1024 * 1024 * 4) * 3 = 12MB となり、ZU9EG が持つ BRAM よりもずっと大きいことがわかります。
従って行列 A、B は FPGA の外、ZCU102 に搭載されている DDR DRAM (以下、DDR) に配置し、演算時に DDR からリード、ライトすることにします。
DSP スライスは2520個を搭載しているので、充分な数がありそうです。
シストリックアレイの構成
全体構造
次の図に示すように、行列 A と行列 B からはそれぞれ4要素を同時に DDR からリードし FIFO を経由してシストリックアレイに渡します。行列 A からは行の成分、行列 B からは列の成分を DDR からリードしますが、ここでは CPU であらかじめ行列 B が転置されているとして連続アドレッシングでデータリードしています。
各 PE の演算結果は FIFO に格納され、DDR にライトされます。
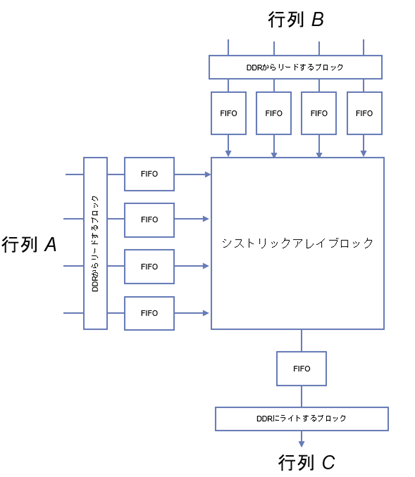
シストリックアレイブロックの構造
次の図はシストリックアレイブロックの内部構造です。
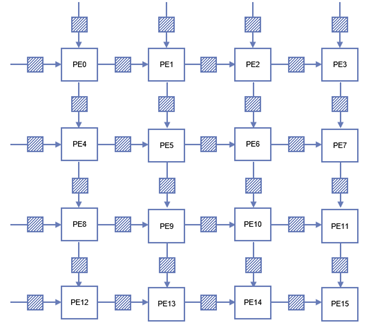
縦横それぞれ4つずつ、合計16の PE を配置した二次元シストリックアレイ構造にします。PE 間は FIFO で接続し、1クロック毎に次段の PE にリードしたデータを渡すことを期待しています。
例えば、 PE0 に入ってきた行列 A のデータは、次のクロックで PE1 に、その次のクロックで PE2 とカスケードされ、PE0 に入ってきた行列 B のデータは、次のクロックで PE4 に、その次のクロックで PE8 へカスケードされます。図中の斜線のブロックは FIFO を示します。
PE の構造
次の図は PE ブロックの内部構造です。
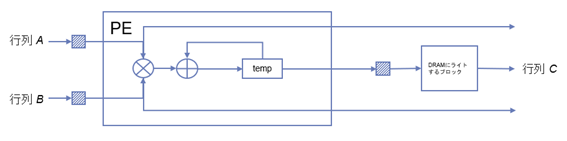
前段の FIFO から行列 A、行列 B のデータをリードして積を計算し直前の結果に累積するパイプラインとなっています。行列 C の要素が求まるたびに結果を FIFO にライトします。FIFO から行列 A と行列 B のデータがリードできない場合は、パイプライン全体がストールします。
動作と合成結果
動作
FIFO にデータが格納されたら、その次のクロックサイクルで、行列 A のデータを PE0、PE4、PE8、PE12 がリードし、行列 B のデータを PE0、PE1、PE2、PE3 がリードします。これと同時に各 PE では後段の PE へデータを渡すために FIFO にライトします。例えば、PE0 は PE1 に行列 A の要素を、PE4 に行列 B の要素をそれぞれ図中の右、下の FIFO にライトします。
次のクロックでは、行列 A と行列 B の最初の成分がそろった PE0 は演算を開始します。それ以外の PE は FIFO に演算に必要なデータが揃うまでストールします。
各 PE は 1024 回の積和演算が終了するたびに結果を FIFO にライトします。
FIFO にライトされた結果を DDR にライトします。
合成結果
合成結果を確認すると PE の II (Initiation Interval) が3クロックサイクルになっていることがわかります。合成後の HDL コードでは浮動小数点演算部分は LogiCORE IP Floating Point Operator (FPO) がインスタンシエートされていますが、その時にターゲット周波数を満たすためにパイプライン化されます。このパイプライン段数はターゲット周波数によって変わりますが、ここでは3サイクルになっています。
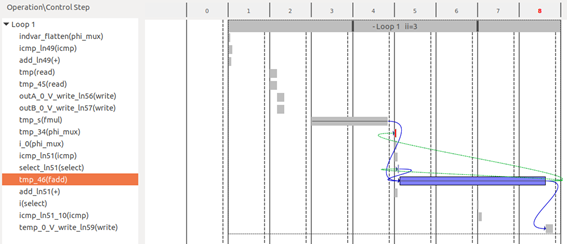
II=1 を疑似的に達成するために、浮動小数点演算を並列化することを考えます。合成結果は II=3 でしたので、並列度は3より大きな4として実装しなおします。PE のコードを次の様に書き直しました。
const int MEM_SIZE = 1024;
void pe(
hls::stream<float> &inA,
hls::stream<float> &inB,
hls::stream<float> &outA,
hls::stream<float> &outB,
hls::stream<float> &outC
) {
float tempC[4];
#pragma HLS ARRAY_PARTITION variable=tempC complete dim=1
for (int i = 0; i < MEM_SIZE*MEM_SIZE/16; i++)
{
for (int k = 0; k < 4; k++)
{
#pragma HLS UNROLL
tempC[k] = 0.0f;
}
for (int j = 0; j < MEM_SIZE/4; j++)
{
#pragma HLS PIPELINE
for (int k = 0; k < 4; k++)
{
float tempA = inA.read();
float tempB = inB.read();
outA.write(tempA);
outB.write(tempB);
tempC[k] = tempA * tempB;
}
}
tempC[0] += tempC[1];
tempC[2] += tempC[3];
tempC[0] += tempC[2];
outC.write(tempC[0]);
}
}1024^3 回の積和演算を16並列で実行するアーキテクチャなので、期待される計算サイクル数は 1024^3 / 16 = 67,108,864 です。
コードを修正した後の高位合成レポートを確認すると、67,108,882 サイクルのデータフローとなっていました。
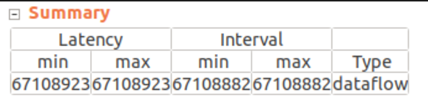
処理前後の DDR からのリード、ライト処理サイクルや各 PE へのデータ到着までの待ちサイクルを考慮すると、すべてのクロックサイクルにおいて16並列演算は実現できませんが、ほぼ 100% の効率で PE が動作しており、期待した実装になっていると考えてよさそうです。
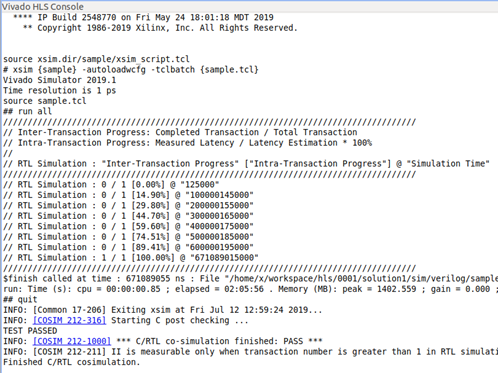
Co-Simulation を実行すると、期待値と結果の一致と 100MHz での処理時間が 671,089,055ns であることが確認できます。
まとめ
以上の説明では、HLS での Co-Simulation までの結果を記しましたが、実際には Vitis を用いて Alveo U200 と ZCU102 で同じソースコードの実機動作確認をしています。
シストリックアレイの FPGA への実装に関してはインターネット上に様々な方法が紹介されています。今回の方法は、転置は CPU で処理し、行列 A、行列 B はそれぞれの行、列を別のバスインターフェースから4並列でリードする前提で実装していますが、ご興味ある方は自分の考えた実装方法で FPGA の可能性を探ってみてはいかがでしょうか。
ザイリンクス株式会社 丸山利広
参考文献
谷萩隆嗣『高速アルゴリズムと並列信号処理』コロナ社、2000