はじめに
BRAM アプリケーションとして FIFO を扱ってきましたが、今回は読み出しレイテンシを0にするにはどうしたらいいか、を扱います。加えて、FIFO から離れますが、Read Modify Write を BRAM で実行したい場合について考察します。
読み出しレイテンシ0の FIFO
読み出しレイテンシ0の定義
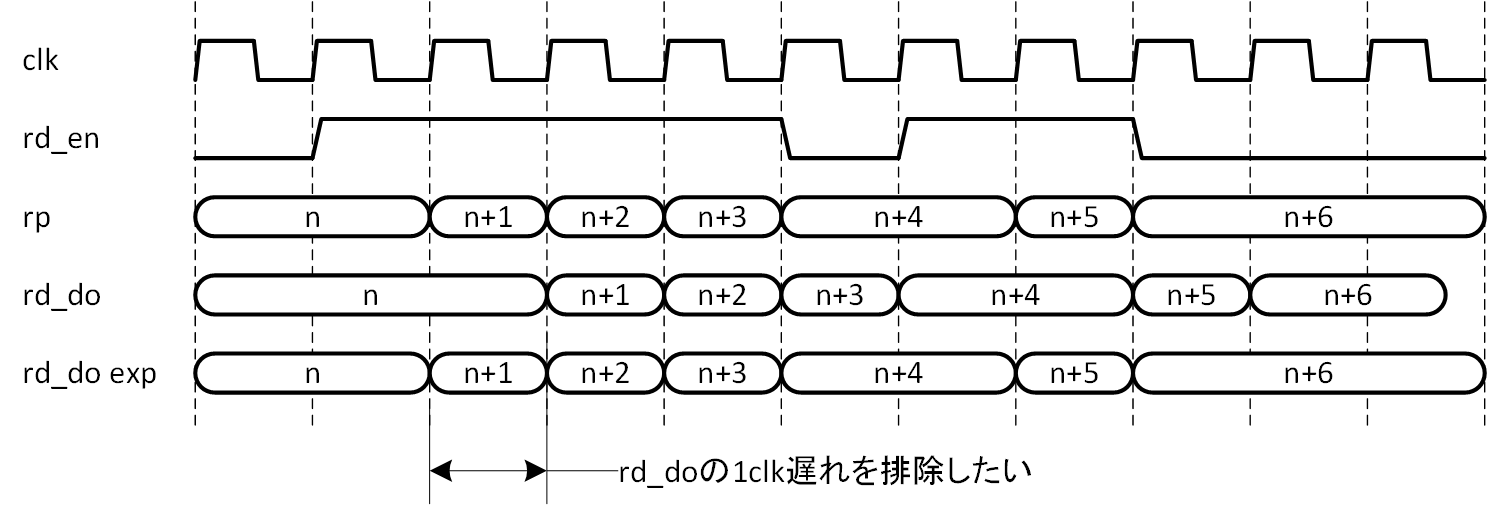
読み出しレイテンシ0を誤解されないために、ここで扱うその定義について明確にしておきましょう。図5-1を見てください。BRAM としての出力段をラッチモードとした場合の読み出しイネーブル (rd_en) からデータ出力 (rd_do) のタイミングを示しています。読み出しアドレスは rp で示していますが、第1回で説明した通り、読み出しアドレスは一度 レジスタに取り込んでからメモリアレーに渡されますので、ここで1クロックのレイテンシが発生します。これに対し、今回期待する読み出しレイテンシ0のデータ出力は、図中では rd_do exp として示しています。rd_do に対し1クロック早くデータ出力が得られていることがわかります。このタイミングを読み出しレイテンシ0と定義します。
なぜそのタイミングで欲しいのか
どうしてそのようなタイミングでのデータ出力を FIFO に期待するのか、について説明しておきましょう。少し経験のある設計者であれば、一度は経験のあることではないか思いますし、賛同も得られるかと考えます。
図5-2に Xilinx の UG1037:AXI リファレンスガイドの Figure 4-10 を写し取りました。このタイミングチャートは UG1037 では AXI4 Stream における ready/valid ハンドシェイクを説明するものです。
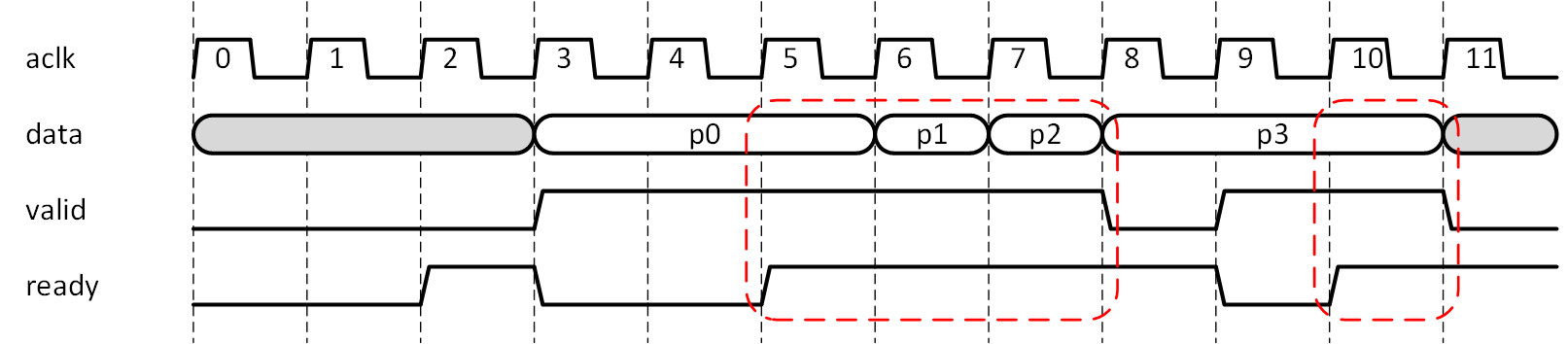
2つの系間でデータなどを授受する場合に、ready/valid ハンドシェイクは簡素かつ有用な方法としてしばしば用いられます。考え方は簡単で、データの受け側が ready をアサートしているタイミングでデータ送り側が valid をアサートしたら、データの授受が成立したことになり、そのクロックサイクルにおけるデータが有効となる、という考え方で、アドレスやデータの授受に見ることができます。これまでの説明に何度も出てきました、FIFO の rd_rdy とデータ受け側の wr_rdy が成立した時にデータの授受が行われる、というのも考え方としては同じ類のものです。図5-2において赤枠で囲ったクロックサイクルで、データの授受が成立しています。データ送り側がデータを出力したうえで valid をアサートし、データ受け側の ready がアサートされるのを待ち、データの授受が成立したところで次のデータに移行する、といったイメージで図は描かれています。ready、valid が共にアサートされ続ければ、連続するクロックサイクルでデータの授受が可能です。
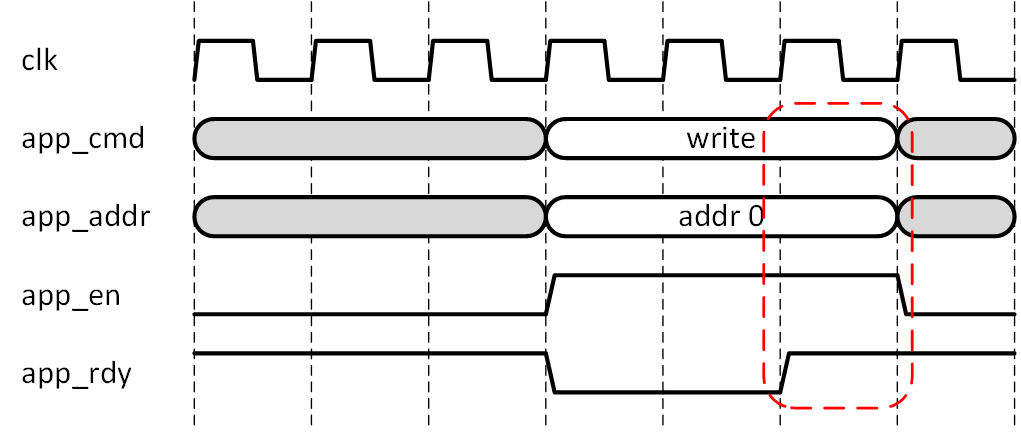
他にも PG150 の Figure 4-2にある例を図5-3に示します。これは DDR3、4メモリインターフェース IP におけるユーザーインターフェースの例で、コマンドとアドレスが IP に渡されています。app_en を valid と読み替えれば全く同じものであることがわかります。
このように、汎用のプロトコルを含めいたるところで ready/valid ハンドシェイクは使用されていますし、Xilinx の IP を用いようとするならばお世話になること必至です。
ここで、FIFO 内に後段へ渡すためのデータが準備され、ready に合わせてデータを渡したいケースを考えてみます。データを供給する前段は独自のシーケンスでデータを生成するが、後段には別のシーケンスがあり直接は渡せない、というケースはよくあることで、FIFO をシーケンスの緩衝材として使用します。あるいは、前段と後段でクロックが異なるケースでも FIFO は利用されます。そのような場合において、FIFO の読み出し側と後段を ready/valid ハンドシェイクで接続するというケースを考えるということです。
FIFO の rd_rdy はデータ準備 OK ということですから、rd_rdy がアサートされている→データは FIFO 出力段に見えていると解釈できますので、rd_rdy を valid とみなすことができます。従って、rd_rdy (=valid) と後段からの ready の AND により FIFO を読み出せば (rd_en とする) 、データの授受は成立するわけです。そうした意味では、FIFO の読み出しは ready/valid ハンドシェイクと相性が良い、と考えることができます。
ここで、図5-2に図5-1のデータ出力タイミングを重ねてみることにします。図5-4に示します。
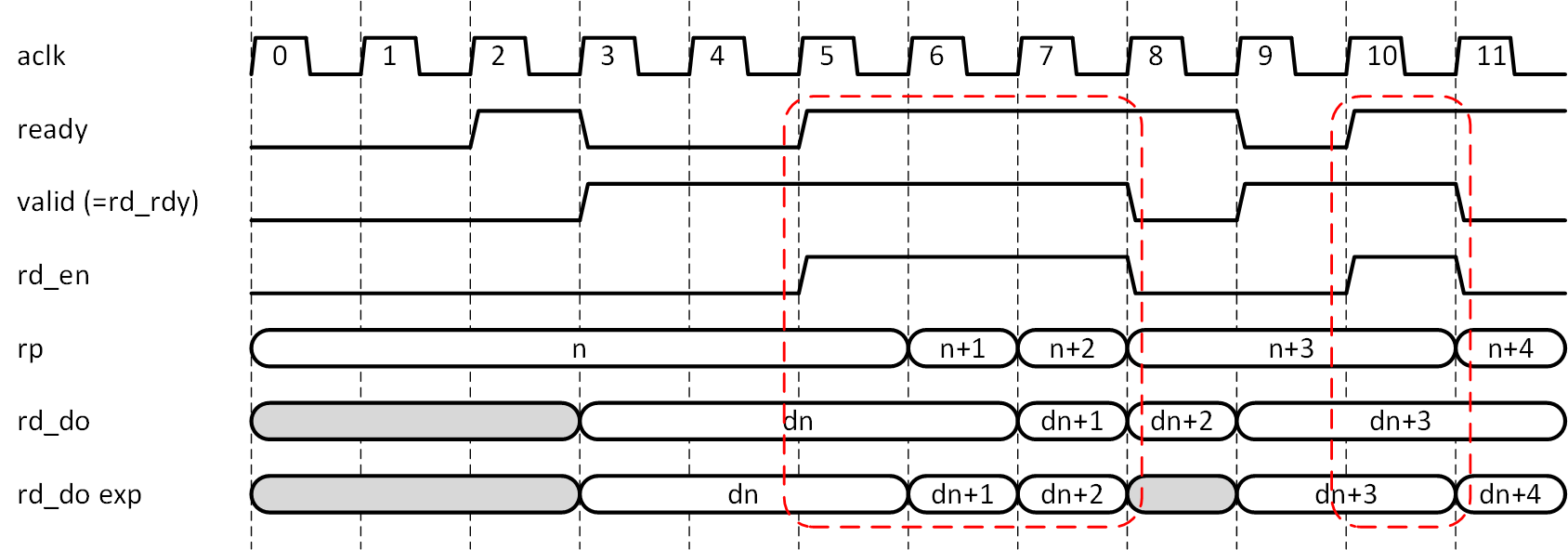
これを見る限り、図5-1で示した読み出しレイテンシ1によって、シェイクハンドはうまくいっていないことがわかります。クロックサイクルの5,6では rd_do に同じデータが2回現れますし、クロックサイクル8に現れた dn+2 に至ってはシェイクハンドが成立したサイクルの外にあって有効なデータとして扱われていません。要するに、データの出現が1クロック遅いのです。これに対し rd_do exp は、欲しいデータが欲しいタイミングで得られているのが確認できます。これこそが読み出しレイテンシ0の FIFO が欲しい理由になります。クロックサイクルをできる限り有効に使うには、ready がアサートされたらすかさずシェイクハンドを成立させたいですから、ready に追従できる FIFO 読み出しである必要があります。
原理を知るため RTL で作る
では、どのようにして読み出しレイテンシ0の FIFO を実現するかを、考えてみましょう。考え方を知るために RTL で表現してみることにします。データ出力は、メモリアレーからの非同期出力とはせず、レジスタ経由 (registered out) とします。一応、論理合成可能なものを前提としますが、構成が複雑になることを避けるため、書き込み側と読み出し側のクロックは共通 (同期型) とします。
図5-5に、読み出しレイテンシ0の FIFO を実現するブロック図を示します。第2回で説明した同期型 FIFO をベースとし、変更を加える形で表現しました。
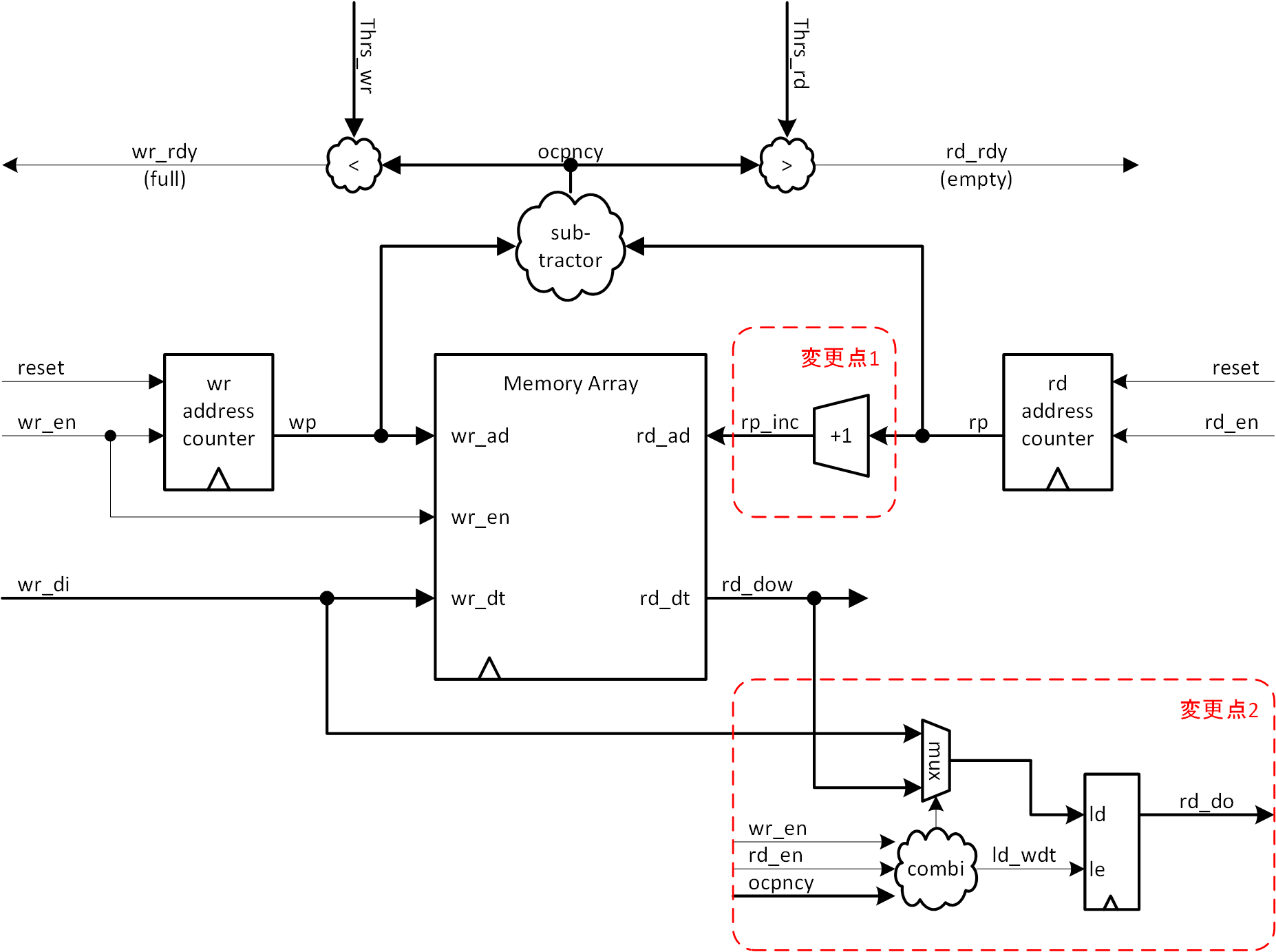
図5-5 FIFO 読み出しレイテンシ0ブロック図
変更点は以下の2点です。図5-5では赤枠で囲って示しています。
変更点1:読み出しデータ出力のアドレスに対する遅延 (1クロック遅れ) を解消する
変更点2:FIFO が空の時はメモリアレーを介さず直に読み出しできるようにする
変更点1については、変更点の主役になります。メモリアレーを非同期メモリとし読み出したデータを直に FIFO 出力とすれば、アドレスのインクリメントにレイテンシ0で追従できますので、目的は達せられてしまうのですが、それではあまりにつまらないので、registered out としたうえで、どうするかを考えます (もちろん、クロック周波数がさほど高くなければ、非同期メモリでも十分に使えます) 。実現法は単純で、読み出しアドレス (rp) が現在指しているアドレスに対し、常に1アドレス先を読み出すということです。そのために rp に対しインクリメンタを介したうえで読み出しアドレス (rp_inc) として使います (rp 生成時に使用するカウンタにはインクリメンタが含まれているのですが、わかりやすくするため別にインクリメンタを用意しました) 。ただし、読み出した先読みデータはすぐに出力レジスタにはロードせず、1データの読み出しが完了して出力レジスタ上のデータが使用済みとなってからロードします。その様子を図5-6に示します。既にお気付きかもしれませんが、この動作をさせるためには、メモリアレーは非同期メモリである必要があります。ですので、図5-5でのメモリアレーは「BRAM」と表現せず「Memory Array」としてあります。
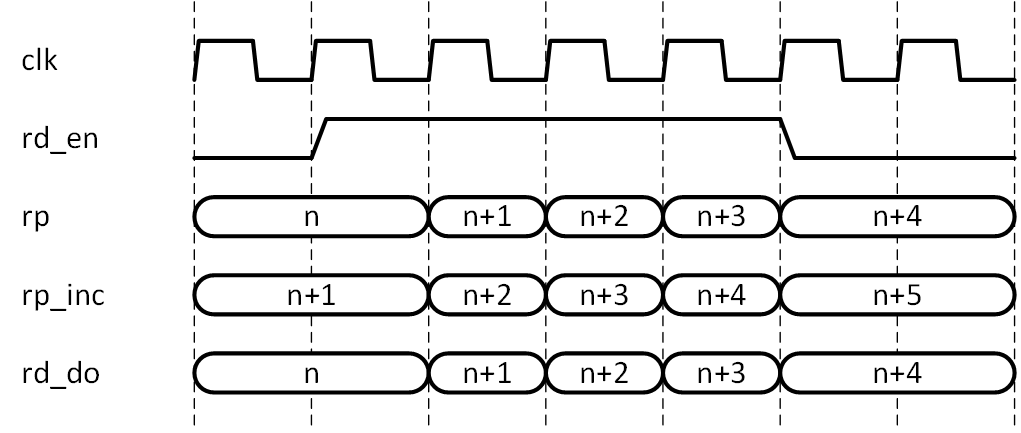
図5-6 メモリアドレスのインクリメントによる先読み
変更点2は、2つの事情から必要な機能になります。まず、変更点1によって常に1アドレス先読みをしていますので、最初に書き込むデータをアドレス0のメモリ上に書いてしまうと、読み出しアドレスは最初からアドレス1を指しているので、そのデータを読むことができないという点です。また、やはり変更点1によって、出力レジスタへのデータのロードは、読み出しによって出力レジスタ上のデータが使用済みとなってからと決めましたので、まだ読み出していない最初の読み出しデータを出力レジスタにロードするトリガがないということです。これを解決するために、最初の書き込みデータ、あるいは FIFO が空の時の書き込みデータは、直接出力レジスタにロードする、という機能を追加します。これは FIFO36E2 が持っている FWFT モードと同じ機能になります。出力レジスタへの直書き込みは、以下の2つケースで必要になります。
- FIFO が空の時の書き込みの場合
- FIFO に1つのデータしかないときに、書き込みと読み出しが同時に発生した場合
それ以外のケースでの書き込みは、すべてメモリアレーに対して行われます。図5-5で出力レジスタへの書き込みを行う ld_wdt は、組み合わせ回路 (combi と表示) で、wr_en、rd_en、アドレス差分 (ocpncy) から判定を行い生成され、同時に書き込みデータの選択を行います。なお、出力レジスタへの直書き込みが発生した際に、メモリアレーに対する書き込みはどうするか (書き込んでも使わないのであれば、書かなくてもいいのではないか) についてですが、特に書き込みを禁止するなどはしていません。より回路を複雑化することになりますし、その場合に書き込み/読み出しアドレスのインクリメントをどうするかなど、条件付けも面倒になりますので、ここはシンプルに考えています。
以上の2点以外に変更点はありません。要約すれば、アドレス先読みと FWFT モードを追加するということになります。この変更により読み出しがうまく機能することを、タイミングチャート上で確認してみましょう。図5-7を見てください。
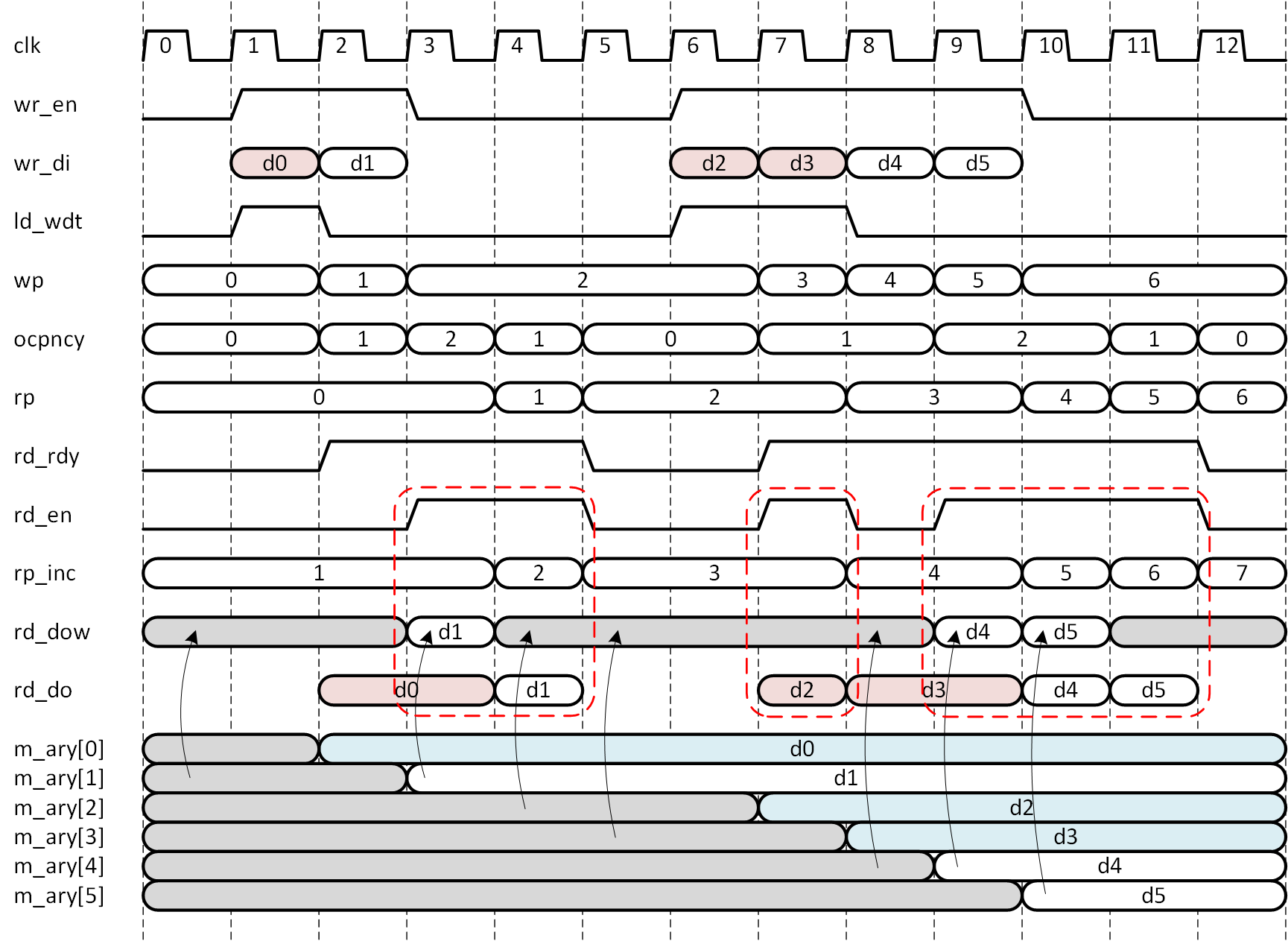
図5-7 作成した FIFOの 機能確認
クロックサイクル1では FIFO が空 (ocpncy==0) の状態で書き込みが発生しますので、出力レジスタに書き込みデータ d0 が直書きされます。図中では直書きされるデータを赤く塗りつぶして表示しました。サイクル2では FIFO が空でなく (ocpncy > 0)、wr_en == 1、rd_en == 0 ですので、d1 はメモリアレーに書き込まれます。この時点で rd_rdy == 1になっていますので、サイクル3,4で読み出しを行います。サイクル3では出力レジスタに d0 が書き込み済みですので、これを読み出します。サイクル3では読み出しアドレス (rp_inc = 1) に従ってメモリアレーから d1 が読み出されていますので、サイクル4で d1 が出力レジスタにロードされます。メモリアレーに何が書かれているかは、タイミングチャート下段に m_ary[0]~[5] までを示してあり、値が確定していないアドレスでは灰色に塗りつぶしてあります。サイクル3,4で読み出しが実行され、FIFO は一度空になります。
サイクル6では FIFO が空 (ocpncy == 0) の状態で書き込みが発生しますので、出力レジスタに書き込みデータ d2 が直書きされます。サイクル7では d3 を書き込みますが、この時点で rd_rdy == 1になっていますので、同時に読み出しを行います。すると、ocpncy == 1、wr_en == 1、rd_en == 1 ですので、d3 も出力レジスタに直書きされます。
サイクル8では読み出しを休止していますので、d4 はメモリアレーに書き込まれ、サイクル9では ocpncy > 1となりますので、wr_en == 1、rd_en == 1 であっても d5 はメモリアレーに書き込まれます。
このようにして、書き込みデータが出力レジスタに直書きされるか否かが選択され、同時に読み出しアドレス (rp_inc) の状態に従ってメモリアレーの非同期出力 (rd_dow) に現れる値が選択されます。その様子はタイミングチャート下段に、m_ary[0]~[5] からの矢印で示しています。これらが、適当なタイミングで出力レジスタにロードされ、目的の機能が達成されます。図中の赤枠で囲った部分は読み出しサイクルで、順次読み出しサイクル内で d0~d5 が読み出されていることが確認できます。また、m_ary[0]~[5] に書き込まれたデータでも、出力レジスタに直書きされたものは、参照されていないことも確認してください。参照されなかったデータは青で塗りつぶして表示しています。 このようにして、読み出しレイテンシ0の FIFO は、工夫次第で実現できることが確認されました。RTL サンプルを list5-1 (ss_fifo_syncb.v) に示します。
module ss_fifo_syncb (
wr_rdy , // buffer write ready
rd_rdy , // buffer read ready
rd_do , // read data out
wr_di , // write data in
wr_en , // write enable
rd_en , // read enable
clk , // clock
rst ); // sync reset ( h active )
parameter Bw_d = 8 ;
parameter Bw_a = 10 ;
parameter Depth = ( 1 << Bw_a ) ;
parameter Thrs_w = Depth/4*3 ; // for write ready
parameter Thrs_r = Depth/4*1 ; // for read ready
input [Bw_d-1:00] wr_di ; // write data in
input wr_en ; // write enable
input rd_en ; // read enable
input clk ; // clock
input rst ; // sync reset ( h active )
output wr_rdy ; // buffer write ready
output rd_rdy ; // buffer read ready
output [Bw_d-1:00] rd_do ; // read data out
// wires & regs
reg [Bw_a:00] wp ;
reg [Bw_a:00] rp ;
wire [Bw_a-1:00] rp_inc = rp[Bw_a-1:00] + 1'b1 ;
wire [Bw_a:00] ocpncy ;
(* ram_style = "block" *)
reg [Bw_d-1:00] m_ary [0:Depth-1] ; // memory array
reg [Bw_d-1:00] rd_do ;
// write pointer
always @( posedge clk ) begin
if ( rst ) wp <= {(Bw_a+1){1'b0}} ;
else if ( wr_en ) wp <= wp + 1'b1 ;
end
// read pointer
always @( posedge clk ) begin
if ( rst ) rp <= {(Bw_a+1){1'h0}} ;
else if ( rd_en ) rp <= rp + 1'b1 ;
end
// occupancy
assign ocpncy = wp - rp ;
assign wr_rdy = ~ocpncy[Bw_a] & ( ocpncy[Bw_a-1:00] <= Thrs_w ) ;
assign rd_rdy = ~ocpncy[Bw_a] & ( ocpncy[Bw_a-1:00] >= Thrs_r ) ;
// memory wr
always @( posedge clk ) begin
if ( wr_en ) m_ary[wp[Bw_a-1:00]] <= wr_di ;
end
// memory rd
wire ld_wdt = wr_en & ~rd_en & ( ocpncy=={{Bw_a{1'b0}},1'b0} )
| wr_en & rd_en & ( ocpncy=={{Bw_a{1'b0}},1'b1} ) ;
always @( posedge clk ) begin
if ( ld_wdt ) rd_do <= wr_di ;
else if ( rd_en ) rd_do <= m_ary[rp_inc] ;
end
endmoduleこれは論理合成も可能ですが、ここで残念なことをお伝えしなければなりません。このRTL では BRAM が推定されないということです。実際に Vivado でこの RTL を論理合成すると以下の Warning が得られます。BRAM では実現できないので、LUTRAM (Distributed RAM:非同期 RAM が実現できる) を割り当てたいと言っています。
[Synth 8-6849] Infeasible attribute ram_style = “block” set for RAM “ss_fifo_syncb/m_ary_reg”,trying to implement using LUTRAM
BRAM にならない理由は、以下の2つが推測されます (あくまで筆者の推測です) 。
- 基本的に BRAM としてはラッチモードによる記述なので、出力レジスタに期待する機能が複雑化したことで、ラッチに割り当てることができなくなった
- いかにも非同期メモリであるかのような機能記述なので、素直に LUTRAM に割り当てた
理由の本当のところはわかりませんが、例えば第1回の list1-1の記述から BRAMを推定してくれるなら、今回の list5-1も何とかならないのだろうか、と1ユーザーとして筆者は考えてしまいます。やはり、機能的に無理があるのでしょう。
さて、この RTL を説明する中で、FWFT モードと同じ機能を使いました。であれば、ビルトイン FIFO (FIFO36E2) を使用して同じ機能を実現できないのだろうか、と考えたくなります。次節ではそれについて考えてみましょう。
ビルトイン FIFO での実現法
FIFO36E2 に以下の属性を設定し、シミュレーションをしてみました。
- CLOCK_DOMAINS “COMMON”
- FIRST_WORD_FALL_THROUGH “TRUE”
- REGISTER_MODE “UNREGISTERED”
シミュレーション結果は、図5-8の通りになりました。結論から言えば、期待した通りの動作になりました。レイテンシ0で読み出しができています。以下のシミュレーション結果は、FIFO36E2 にラッパーを被せて筆者が使いやすいようにしていますので、ポート名が一部変更されていますが、多分読み替えは容易かと思います。
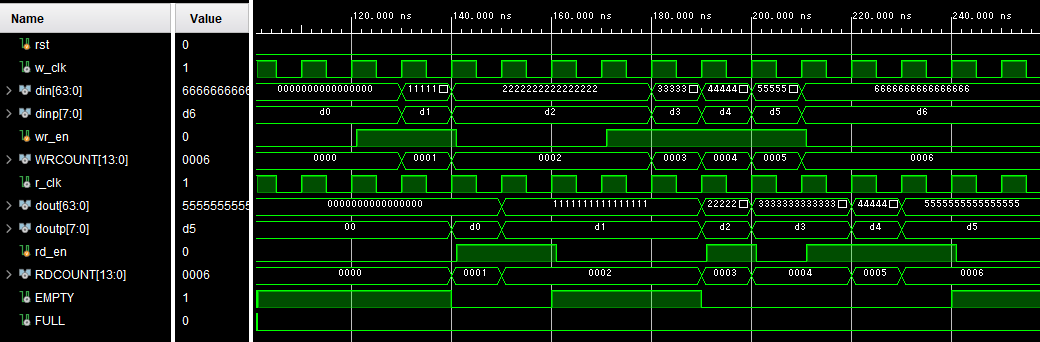
図5-8 FIFO36E2 による読み出しレイテンシ0 FIFO
出力段にデータが準備されたのに合わせてEMPTYがデアサートされていますので、ユーザーとしては !EMPTY (=rd_rdy) に合わせて rd_en をアサートすれば、レイテンシ0で読み出し可能ということです。注目すべきは、RDCOUNT (属性 RDCOUNT_TYPE = “RAW_PNTR” としています) です。これは FIFO36E2 内部のアドレスカウンタの値ですが、やはり出力段にデータが準備されたのに合わせてインクリメントされています。従って、読み出しを行ったことで新しいデータが出力段にロードされるとインクリメントが実行され、次のロードのために1つ先のアドレスを指して待機しています。ちょうど筆者が作成した設計例と同様、1アドレス先読みするイメージです。違いは、筆者の設計例はアドレスカウンタに対しさらにインクリメンタを介してアドレスを生成していますが、こちらはカウンタ自体で先読みさせているように見えます。その意味ではよりシンプルと言えます。これらの機能が FIFO36E2 内のリソースで調達可能で、タイミング収束でも安定していると考えれば、使わない手はないかもしれません。
以上は、筆者の調査した範囲での話ですので、実際に使用する際は検証を十分に行ってください。UG573 の FWFT モードに関する記述が、もう少し充実していると、安心して使えるのですが。
Read Modify Write を BRAM で
Read Modify Write という言葉は、一度は聞いたことがあるのではないかと思います。メモリ上のデータを読み出し、それに何らかの変更を加えて、元のアドレスに書き戻す操作を言います。
例えば、ヒストグラムを作成する機能が欲しい場合、メモリを使用すると簡単に実現できます。メモリを初期化 (すべてのデータを0にする) しておき、入力データが a であれば、アドレス a のデータを読み出し、その値をインクリメントし、アドレス a に書き戻す、という操作を入力データに対し順次施せば、メモリ上にヒストグラムが完成します。
ここでは、ヒストグラム作成を題材として、BRAM を用いた Read Modify Write の実現方法と高速化について考えてみましょう。
基本原理
原理図を図5-9に示します。ここではあくまで原理を示し、レイテンシなどのタイミングにかかわる考慮はされていません。
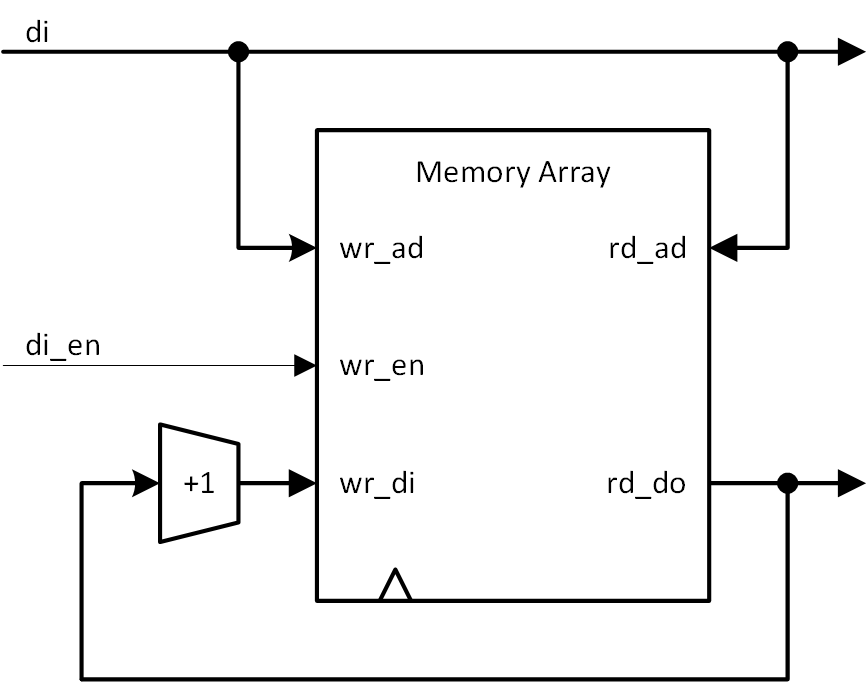
図5-9 ヒストグラム作成原理
原理といってもたいしたものではありません。入力するデータをアドレスとして BRAM上のデータを読み出し、これをインクリメントして同じアドレスに書き戻すだけです。従って、メモリに対する読み出しアドレス、書き込みアドレスは、いずれも入力データになります。この操作によって、データが指し示すアドレスの値がインクリメントされることは、そのデータが発生した回数を数える ( インクリメントする ) ことを意味します。すでに述べましたが、その操作に先立ってメモリ上のすべての値は0に初期化しておく必要があります。
では、タイミング的要素も加味した上で考えてみます。メモリアレーとしては BRAM を使用しますので、とりあえず BRAM の出力はラッチモードとし、出力レイテンシ (読み出しアドレス入力から読み出しデータまでのレイテンシ) を1としておきます。タイミングチャートを図5-10に示します。
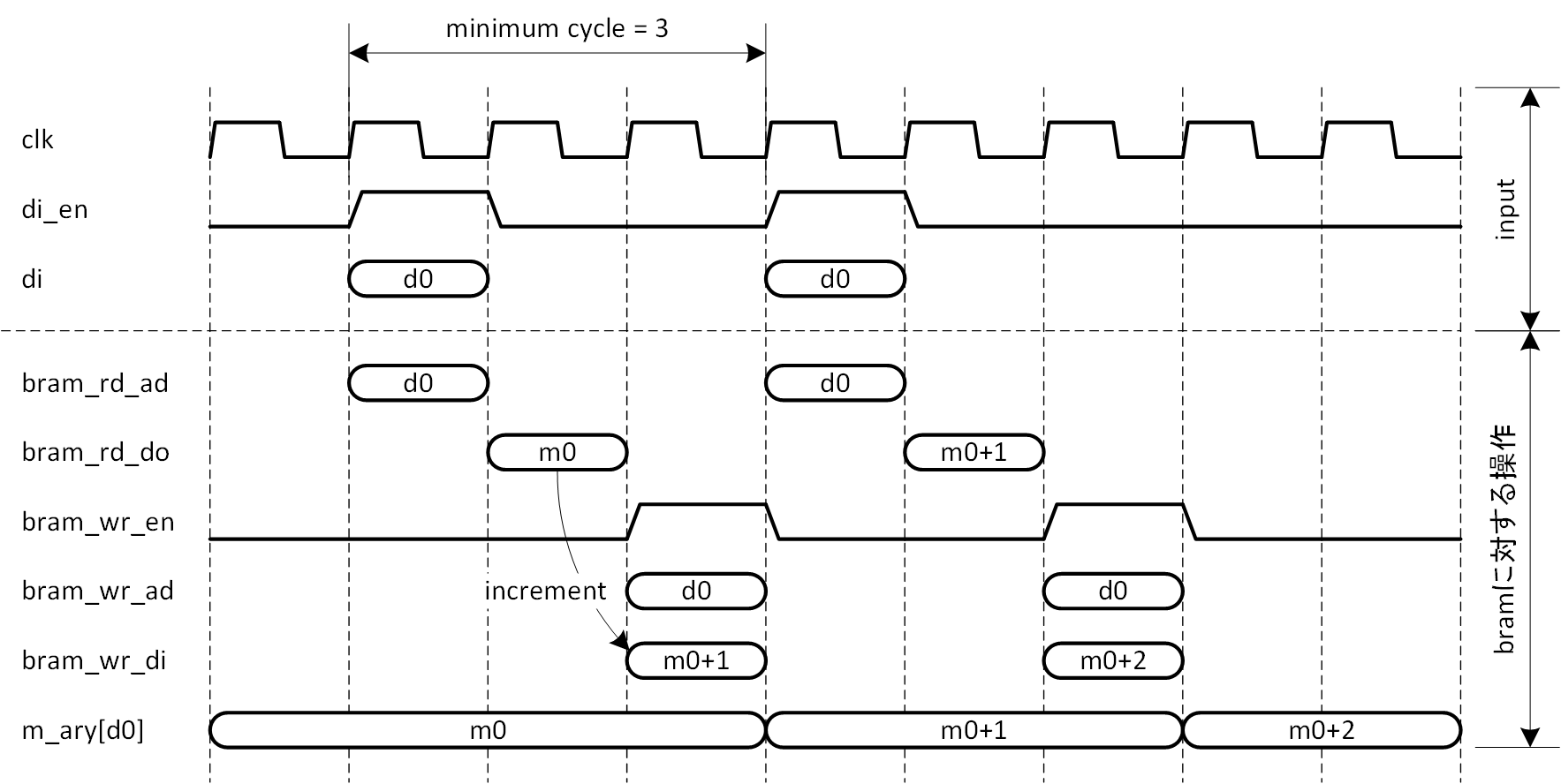
図5-10 BRAM によるヒストグラム作成タイミングチャート
データ入力を d0 とし、2回連続でd0が入力された場合を示しています。BRAM の読み出しアドレス (bram_rd_ad) に d0 が加えられ、メモリから読み出しデータ (m0) が得られるまでに1クロックのレイテンシが必要です。この m0 をインクリメント (m0+1) しますが、パイプラインレジスタの意味で1クロックレイテンシを加えることにします。m0+1 を書き込みデータとし、d0 を書き込みアドレスとして、BRAM に書き戻します。書き込んだデータがメモリアレーに反映されるまで (書き込んだデータが読み出せる状態になるまで) 、さらに1クロックがかかります。こうして一連の操作が完了するまでに、3クロックのレイテンシが必要になります。インクリメント操作のパイプラインレジスタを排除しても、最低2クロックは必要です。
1つのデータ入力に対して読み出し1回と書き込み1回しか発生しませんので、仮に連続する入力データが必ず異なるという条件が与えられるならば、それぞれの入力データに対する操作は互いに干渉しませんので、読み出しと書き込みはパイプライン化できる操作になり、データ入力は連続して可能となります。しかし、図5-10のように連続する入力データが等しい場合、BRAM の同じアドレスに対し連続するインクリメント操作が必要になり、その場合には先行する入力データ分のインクリメントが完了してから次の入力データによるインクリメントを行う必要があります。ここで前述の処理レイテンシが障害となって、連続したデータ入力ができなくなるわけです。図5-10はそれを表しています。 連続する入力データが等しくないことを期待するのは、ヒストグラム生成においては無理があります。入力データが特定の値に偏って生起するという場合には、特にそうでしょう。といって、処理効率を考えた場合、毎クロックサイクルでデータを入力したいというのは、要求仕様として当たり前のことかと思います。例えば、処理レイテンシ分の BRAM を並列に用意し、後続のデータは処理中の BRAM を避けて別の BRAM 上で処理し、全ての処理が終わったところで並列する BRAM の同一アドレスの値を加算する、といったことでも実現は可能ですが、リソースの無駄感は否めません。ここでは1つの BRAM で実現することを考えます。
設計仕様を決める
設計の仕様を整理しておきましょう。
- BRAM の書き込み、読み出しクロックは共通とする
- 入力データの値にかかわらず、毎クロックサイクルのデータ入力が可能
- ヒストグラム作成機能の他に、メモリ初期化機能、ヒストグラム読み出し機能が必要
- メモリデータのインクリメント処理にはパイプラインレジスタを入れる
- BRAM 出力はラッチモードでなくレジスタモードを使用する
1項目目は説明を単純にするための条件です。後半の2項目については必須とは言えないのですが、メモリ読み出し→インクリメント→メモリ書き込み、の3ステップのレイテンシが問題となっているので、より厳しい条件として処理レイテンシが増える方向に選択しました。逆にタイミング制約上は有利となるはずです。
BRAM の書き込み、読み出し条件の確認
基本条件として、書き込みに1クロック、読み出しに2クロック (レジスタモードゆえ) のレイテンシが必要、とします。タイミングチャートを図5-11に示します。m_ary[a0] はアドレス a0 が指し示すメモリセルの値です (注:あくまで原理的なタイミングを表しています) 。
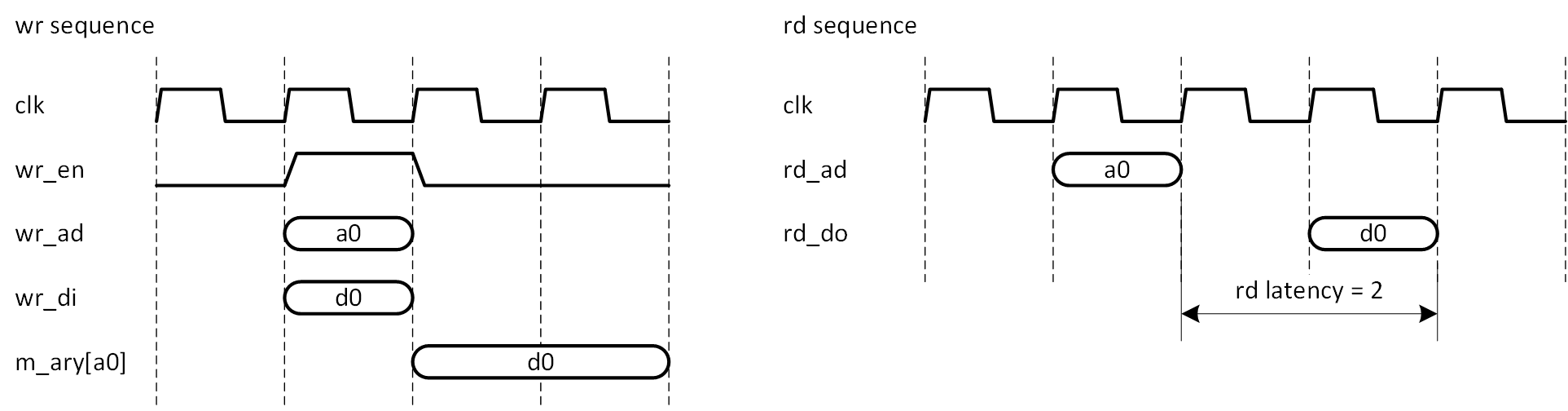
図5-11 BRAM の基本タイミング
これを実現する BRAM のモデルを図5-12に示します。左側は期待する動作イメージで、BRAM ではアドレスはレジスタに取り込まれてからメモリアレーに供給されるので、レジスタモードで使用するならばこのイメージのはずです。右側には RTL での記述イメージを示します。UG901 で提供されている ug901-vivado-synthesis-examples における rams_pipeline.v を参考にレジスタモードを表現しています。
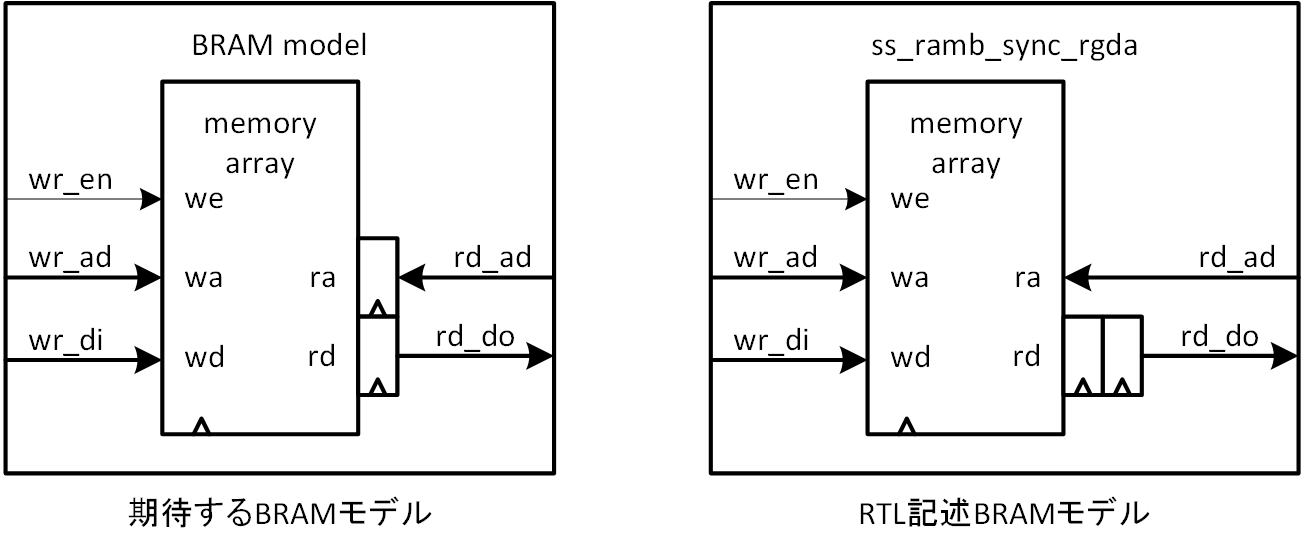
図5-12 BRAM モデルイメージ
これに基づいた RTL による BRAM モデルを、list5-2 (ss_ramb_sync_rgda.v) に示します。Vivado による論理合成で、BRAM がレジスタモードで推定され、BRAM 以外のリソースとして CLB が使用されていないことは確認済みです。もしラッチモードが推定された場合は、以下のメッセージが出ますので確認してください。
[Synth 8-7053] The timing for the instance m_ary_reg_bram_0 (implemented as a Block RAM) might be sub-optimal as no optional output register could be merged into the ram block. Providing additional output register may help in improving timing.
module ss_ramb_sync_rgda (
wr_en , // i wr enable
wr_ad , // i wr address
wr_di , // i wr data
rd_ad , // i rd address
rd_do , // o rd data
clk ); // i clock
parameter Bw_d = 32 ;
parameter Bw_a = 10 ;
input wr_en ; // i wr enable
input [Bw_a-1:00] wr_ad ; // i wr address
input [Bw_d-1:00] wr_di ; // i wr data
input [Bw_a-1:00] rd_ad ; // i rd address
output [Bw_d-1:00] rd_do ; // o rd data
input clk ; // i clock
// wires & regs
reg [Bw_d-1:00] rd_dor1; // reg data 1
reg [Bw_d-1:00] rd_dor2; // reg data 2
assign rd_do = rd_dor2 ;
(* ram_style = "block" *)
reg [Bw_d-1:00] m_ary [0:2**Bw_a-1] ; // memory array
// reg wr side
always @( posedge clk ) begin
if ( wr_en ) m_ary[wr_ad] <= wr_di ;
end
// reg rd side
always @( posedge clk ) begin
rd_dor1 <= m_ary[rd_ad] ;
rd_dor2 <= rd_dor1 ;
end
endmodule以上により BRAM モデルは確定したものとし、BRAM としてはこれより変更しないものとします。従って、読み出し側は2クロックレイテンシ、書き込み側は1クロックレイテンシとなり、書き込み側には入力レジスタがない状態となっています。
BRAM 周辺の設計
BRAM は確定できましたが、肝心の部分「どうやって連続する同一アドレスへのメモリ読み出し→インクリメント→メモリ書き込み (Read Modify Write) を実現するか」が解決していません。ようやく本来の目的にたどり着いたわけですが、ここで問題を整理しておきましょう。読み出しレイテンシは2クロック、インクリメント処理レイテンシが1クロック、書き込みレイテンシは1クロックですから、トータル4クロックのレイテンシとなるわけですが、この4クロックのレイテンシをなかったように見せかけられれば良いわけで、これができれば、通常の書き込みと何ら変わらないことになります。このなくしたいレイテンシ4という数字がキーワードです。
考え方としては、「必ず一度メモリに書き込んだデータを起点にしてインクリメントを行う」としてしまうがゆえに、レイテンシが問題として立ちはだかっていると考えてみます。つまり、「同一アドレスへの Read Modify Write が連続するのであれば、まとめて書き込み前に Modify して、連続した分を1回で書き込んではどうか」と考えてみるわけです。すでに処理レイテンシとして4クロック必要ということは明言してありますので、連続して同一アドレスにインクリメント操作を実行するには、4回分のインクリメントを1クロックサイクルで実行できれば良いことは明らかです。もちろん最初の4サイクルが指し示すアドレスがすべて同じであった場合の話で、異なるアドレスを指しているのであれば、そうする必要はありません。
例を2つ示して説明しましょう。図5-13には5クロックサイクル連続で同一アドレスをインクリメントしたい場合を示します。
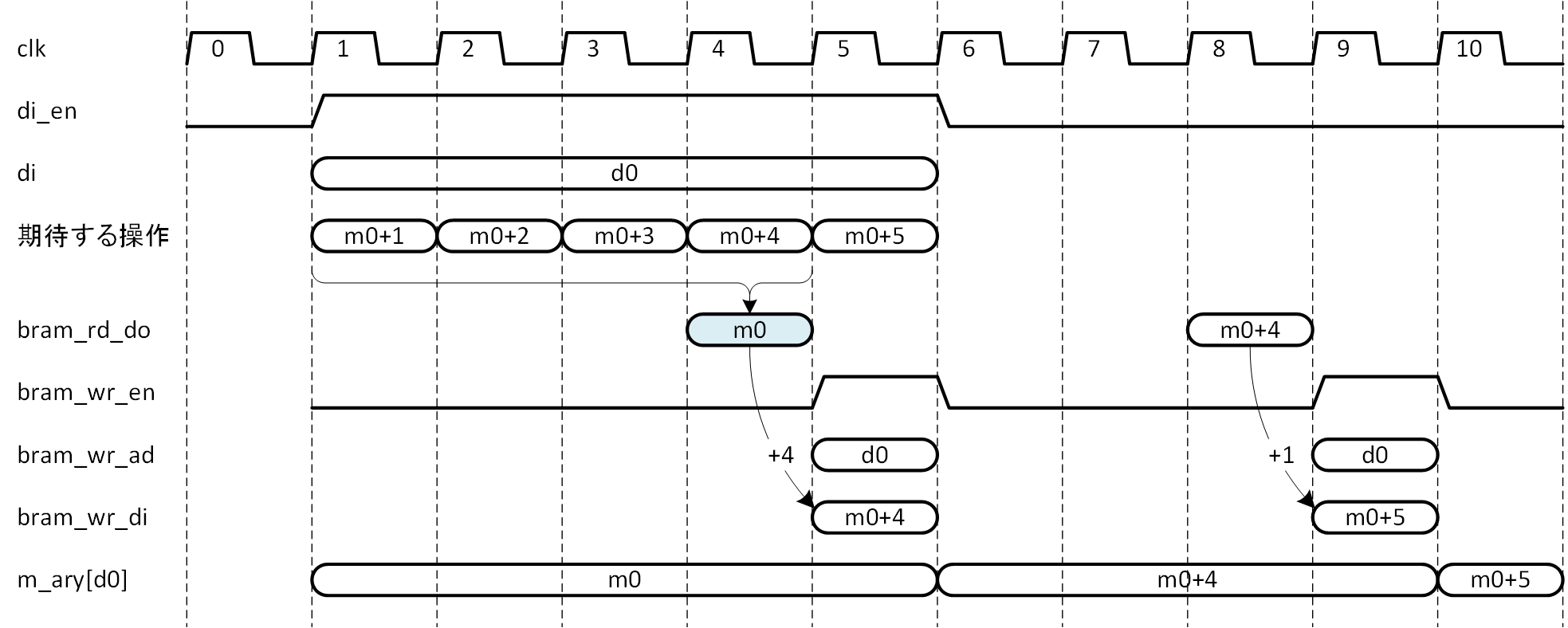
図5-13 連続 Read Modify Write 例1
クロックサイクル1で初めてアドレス d0 に対するインクリメントのリクエストが発生し、5サイクル連続しています。先の前提に従い、5回連続の同一アドレスインクリメントのうち最初の4回分はまとめて処理可能とし、残りを1回分として別に処理することにします。
4サイクル分のアドレスの中に先頭のアドレス d0 と等しいものがいくつあるかを判断するには、4アドレスが入力され既知である必要がありますので、サイクル4まで待たなくてはなりません。この際、サイクル4でメモリ読み出しデータが得られれば、4サイクル分のインクリメントをそのデータに反映することができますので、最も効率が良いと言えます (読み出しデータ m0 を青で塗りつぶして表示しています) 。読み出しレイテンシは2なので、サイクル4での読み出しデータ取得に違和感があるかもしれませんが、シーケンスの組み立ては後程示しますので、サイクル4で読み出しデータが得られる前提で説明を進めます。
この例では、先頭4サイクルがすべてアドレスd0ですので、この4回分をまとめて処理 (+4) してやることにします。読み出しデータに対し m0+4 を演算し、パイプラインレジスタを介して次のサイクル5でメモリ書き込みを行います。後追いで発生したサイクル2~4による d0 へのインクリメントはサイクル4でまとめて処理済みですので、これらによるインクリメントは重複してインクリメントされないよう取り消しておかなければなりません。詳細は後述します。
図5-14は、2つのアドレスに交互に2回ずつインクリメントしたい場合です。見やすくするために、2つのアドレスに対する処理を異なる色で塗りつぶしています。
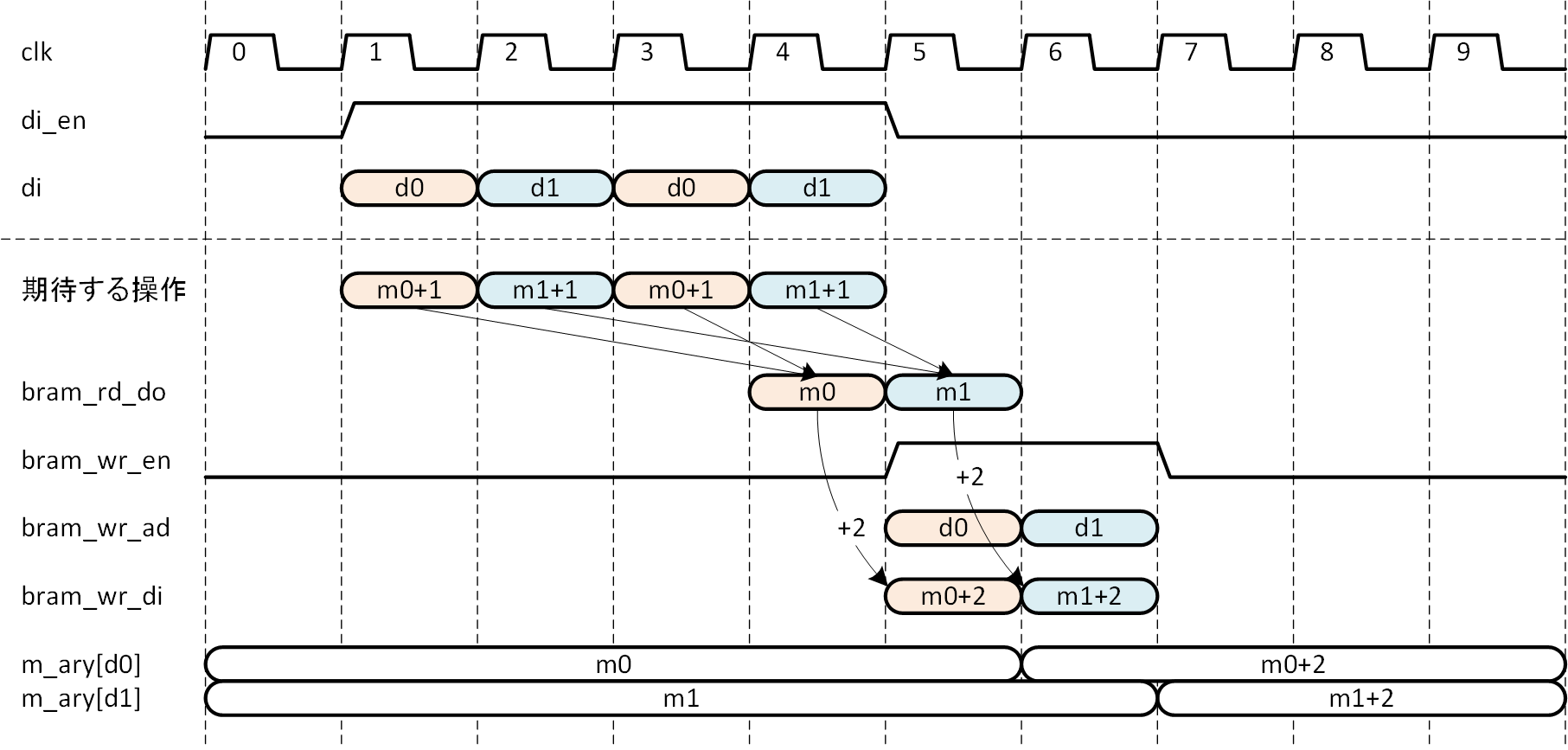
図5-14 連続 Read Modify Write 例2
例1の場合と同じで、クロックサイクル1で初めてアドレス d0 に対するインクリメント要求が発生しますので、これに対しサイクル4でメモリデータ m0 を得たとします。この時点でアドレス d0 に対するインクリメント要求はサイクル1と3で発生した2回のみです。ですので、サイクル4では m0+2 を演算し、次のサイクル4でメモリ書き込みを行います。サイクル2ではアドレス d1 に対するインクリメント要求が発生し、サイクル5でメモリデータm1を得ていますが、この時点でアドレス d1 に対するインクリメント要求はサイクル2と4で発生した2回ですから、サイクル5で m1+2 を演算し、次のサイクル6でメモリ書き込みを行います。サイクル3、4で発生した2つのアドレスに対するインクリメント要求は、それぞれ先行するインクリメント要求での処理で済んでいますので、これによるインクリメント要求は重複を避けるため、取り消しておかなければなりません。
シーケンスの組み立て
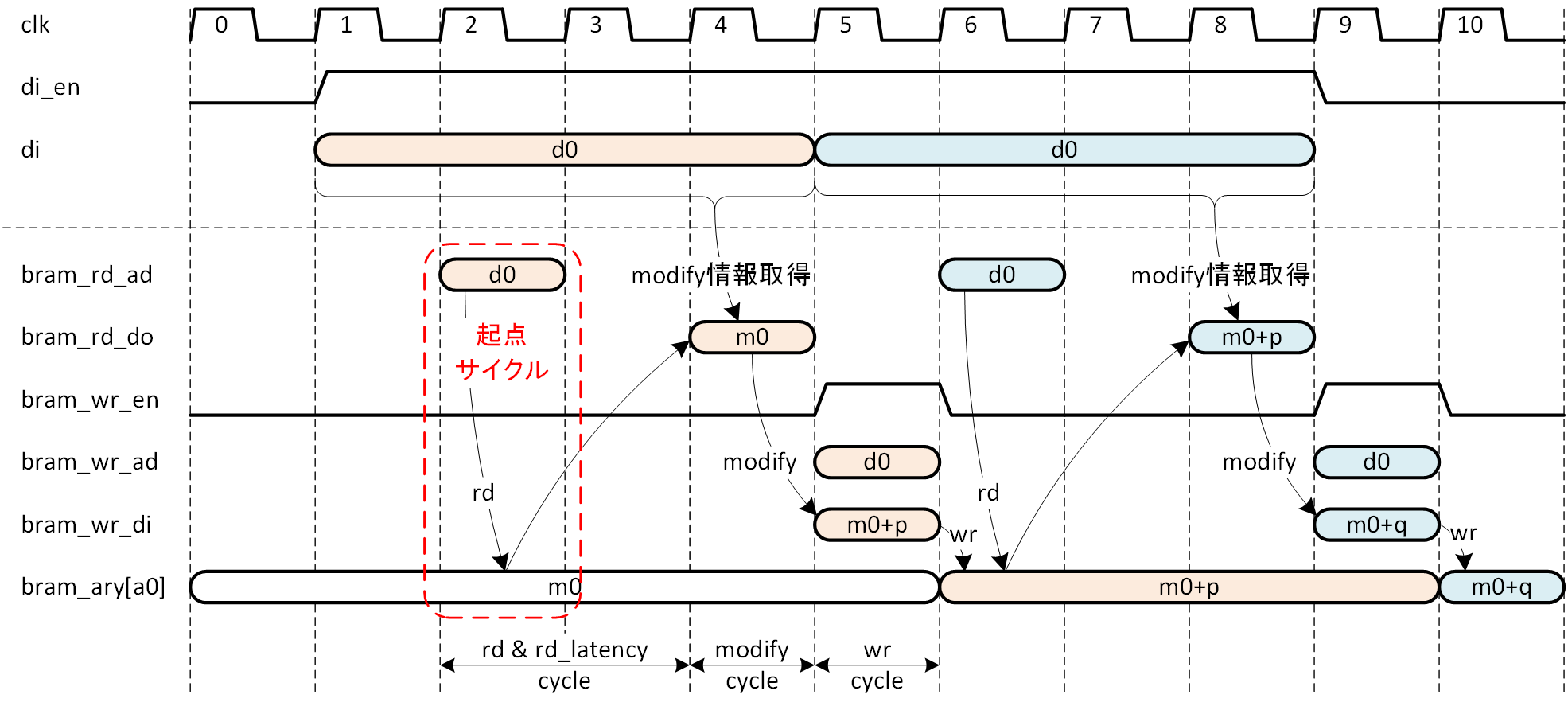
図5-15 シーケンスの組み立て
シーケンスを組み立てます。図5-15にその様子を示しますが、2セットのシーケンスが示されていて、セットごとに塗りつぶしの色を分けてあります。起点とするサイクルは、Read Modify Write と言うくらいですから、メモリの読み出しアドレスを出すサイクルとします。図5-15ではクロックサイクル2がそれにあたり、読み出しアドレスは d0、起点サイクルとして赤枠で示しています。メモリ読み出しレイテンシは2ですから、読み出しデータはサイクル4になり、読み出した値を m0 としています。この値に必要なインクリメントを行いますが、インクリメント値を決めるにあたって参照される入力データはインクリメント4回分ですから、サイクル4を含む4データであるサイクル1~4の入力データが参照されます。この4サイクルの中から d0 と同じ値を持つ分だけインクリメントされます。インクリメント結果がサイクル5で示され (書き戻し値の確定) 、書き戻しが行われます。
書き戻された結果がメモリアレーに反映され、その値を読むためにアドレスを出せるのは、サイクル6以降になります。図5-15のサイクル6で、bram_ary[d0] が m0+p となっていることを確認しましょう。従って、次に続く入力データがやはり d0 であった場合には、その d0 をアドレスとして発行できるのがサイクル6以降ということです。図5-15では、サイクル6で d0 を読み出しアドレスとして発行しています。最初に読み出しアドレスとして d0 を出したのがサイクル2で、次がサイクル6ですから、その差分は処理レイテンシ4と一致します。
図5-15を見る限り、最初に読み出しアドレスとして d0 が確定するのはサイクル1なのですが、実際にアドレスに反映するのはサイクル2です。ここが先に説明した「違和感」の原因です。インクリメント情報を取得する4入力データのサイクルと、メモリに書き戻した値を次のインクリメントに反映させることを両立するため、幾分いびつなシーケンスになっていると理解してください。基本的には起点サイクルを中心に、パイプラインが構成されているのです。
シーケンス上で、インクリメントを判定する4サイクル、メモリ読み出しアドレスサイクル、インクリメント処理サイクル、メモリ書き戻しサイクル、全てが図5-15のシーケンスに組み立てられましたので、これに基づいてインクリメント処理を実行する構造を設計します。
インクリメント処理の構造
ここまでの説明を聞いていると、何やらとても複雑な処理が必要な印象を受けると思いますが、案外そうでもありません。図5-16を使って説明しましょう。
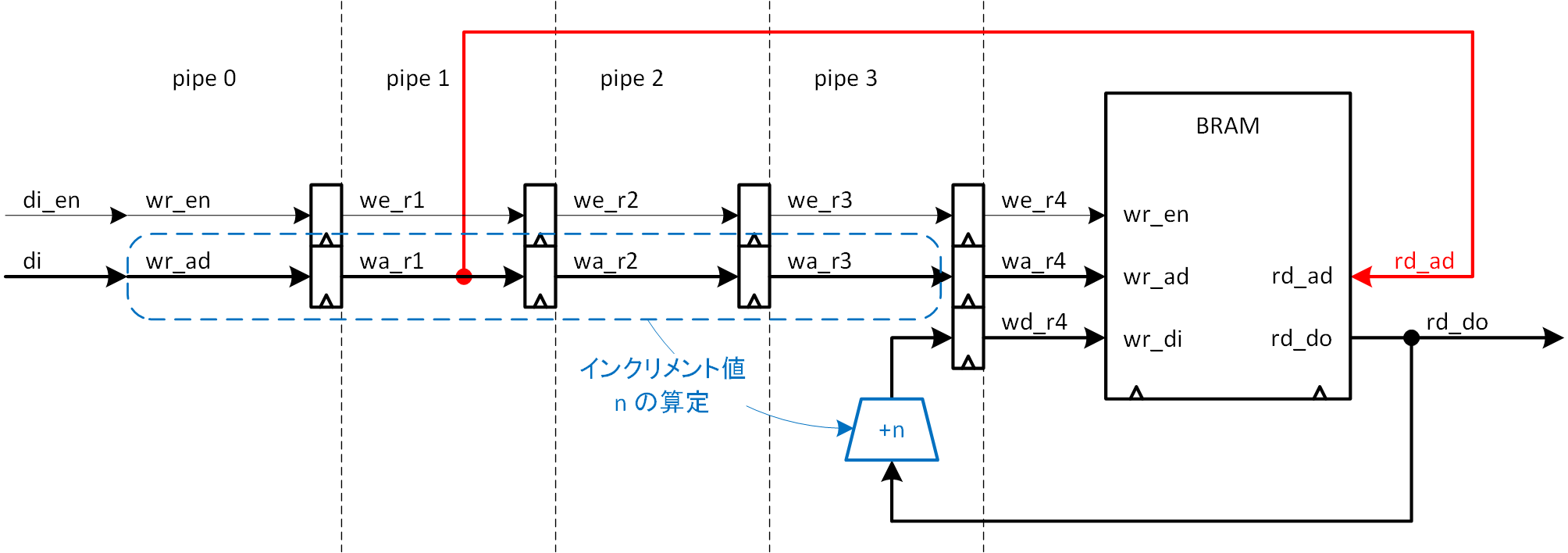
図5-16 インクリメントの基本構造
図5-15において、メモリに対して書き込みを行う5サイクル目はメモリ内部の処理ですので、その前までの4サイクル分が BRAM 外部の処理担当分です。ここに4段のパイプラインを構成します。読み出しレイテンシ2サイクル、インクリメント1サイクル、書き込み1サイクルを前提とし、読み出しアドレスから読み出しデータのインクリメントに合わせて書き込みアドレスを供給するとすれば、この構造は必須の構造となることがわかります。これを基準にまとめ書きインクリメントを実現します。パイプラインには pipe0~3 の番号を付けてあります。また、説明の都合上、di→wr_ad、di_en→wr_en と名前を付けなおしています。
既に説明の通り、シーケンスの起点を BRAM への読み出しアドレスサイクルに取っていますが (図5-16で赤で示したrd_ad) 、組み立てたシーケンスに従えば、データ入力 (di) から1クロックサイクル遅れてのサイクルに割り当てられていますので、pipe1 から取ることにします。読み出しデータは2クロック後となりますので、pipe3 に値を返すことになります。
返された値に対し、いくつインクリメントするかを判断するのは、pipe0~3 にあるアドレス (wr_ad、wa_r1~3) で、pipe3 に到達した wa_r3 と等しいかどうかで判断され、+n (最大 +4) されることになります。この処理は図5-16では青で示してあります。
次に、まとめ書きによって先行インクリメントされた分を2度カウントしないように、どのように取り消すかを考えます。例えば、wr_ad が有効 (wr_en==1) かつ wa_r3 と同じ (pipe3 と pipe0 の比較) であって we_r3==1 であれば、wr_ad によるインクリメント分は pipe3 で先行してインクリメントされますので、このインクリメント分は pipe3 に至った際にはインクリメントされてはなりません。この処理済みインクリメントを表すフラグとして、wr_en、we_r1~3 を使用します。先の例で wr_ad と wa_r3 が同じで、pipe3 で先行インクリメントされたとすれば、wr_en=0 として使用済みであることを示しておきます。次のクロックサイクルでは、wr_en は we_r1 に伝達されますが、ここで wa_r1 と wa_r3 が等しかったとすれば、pipe1 のインクリメント分を先行で処理したいところですが、we_r1==0 ですのでインクリメントの対象にはなりません。pipe3 と pipe1~2 の比較においても同様です。
従って、先に説明したインクリメント +n (+1~+4) 条件に修正を加え、以下の通りとします。4つの条件により独立に判断されたインクリメント値を合算して、pipe3 でインクリメントします。
- we_r3==1 && wr_en==1 && wa_r3==wr_ad で +1
- we_r3==1 && we_r1==1 && wa_r3==wa_r1 で +1
- we_r3==1 && we_r2==1 && wa_r3==wa_r2 で +1
- we_r3==1 で +1
図5-17に、以上の追加された機能を合わせて、ヒストグラム生成器をブロック図で示します。BRAM の初期化ポートと結果読み出しポートも追加してあります。
図中で、”compare pipe** pipe3″ と示してあるのは、pipe3 のアドレス (wa_r3) と他の pipe のアドレスを比較を行う部分で、機能的には等価です。アドレス比較の結果に従い、インクリメントの値 (+0 or+1) を決定し、それに応じて wr_en、we_r1~2 に処理済みの内容を反映します。3つある比較機能は互いに干渉しないので、構成としてはシンプルです。pipe3 でそれらをまとめてインクリメントするのは、すでに説明の通りです。
初期化ポートについては、内部にシーケンサを持たせても良いのですが、結果読み出しに何らかのバスが接続されるイメージがありましたので、初期化も外部制御としました。初期化の値をアドレス毎に変えることができますので、それも時には便利だと思います (特にデバッグの際など)。
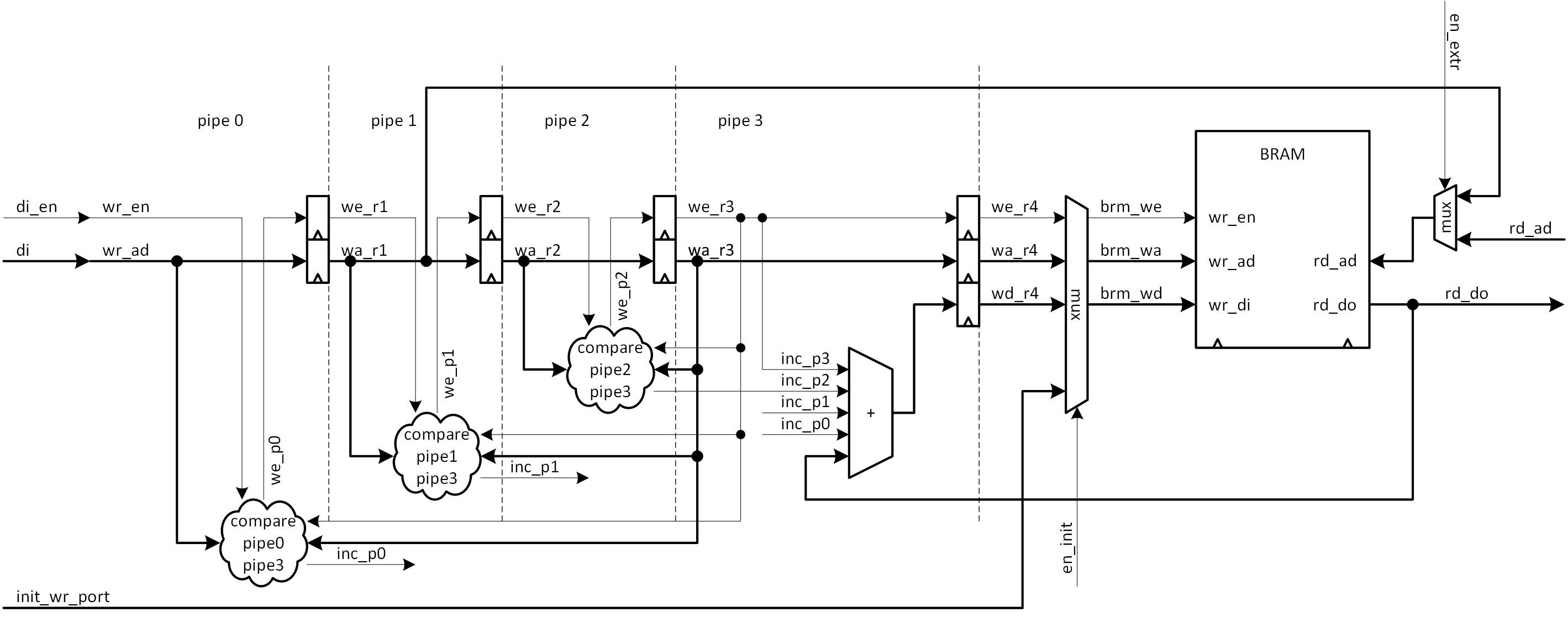
図5-17 連続データ入力ヒストグラム生成器
list5-3 には ss_histograma.v として RTL を示します。
発展的に考えれば、インクリメント演算を別の演算に置き換えれば、ヒストグラムに限定されない機能での Read Modify Write が実現できます。ただし、書き込みの度に演算機能を変更するなどの自由度はありませんので、あしからず。
module ss_histograma (
rd_ad , // i rd address
rd_do , // o rd data out
di_en , // i data enable
di , // i data in
ini_we , // i initial wr enable
ini_wa , // i initial wr address
ini_wd , // i initial wr data
mode , // i mode 0:rd_mod_wr 1:rd
clk ); // i clock
parameter Bw_d = 32 ;
parameter Bw_a = 10 ;
input di_en ; // i data enable
input [Bw_a-1:0] di ; // i data in
input [Bw_a-1:0] rd_ad ; // i rd address
output [Bw_d-1:0] rd_do ; // o rd data out
input ini_we ; // i initial wr enable
input [Bw_a-1:0] ini_wa ; // i initial wr address
input [Bw_d-1:0] ini_wd ; // i initial wr data
input [1:0] mode ; // i mode 0:rd_mod_wr 1:rd 2:init mcel
input clk ; // i clock
// wires & regs
wire en_init= mode[1] ; // renamed
wire en_extr= mode[0] ; // renamed
wire wr_en = di_en ; // renamed
wire [Bw_a-1:0] wr_ad = di ; // renamed
reg we_r1 ,we_r2 ,we_r3 ,we_r4 ; // wr enable
reg [Bw_a-1:0] wa_r1 ,wa_r2 ,wa_r3 ,wa_r4 ; // wr address
reg [Bw_d-1:0] wd_r4 ; // wr data
wire brm_we ; // bram wr enable
wire [Bw_a-1:0] brm_wa ; // bram wr address
wire [Bw_d-1:0] brm_wd ; // bram wr data
wire [Bw_a-1:0] brm_ra ; // bram rd address
wire [Bw_d-1:0] brm_rd ; // bram rd data
// wr control
wire eqwa30 = ( wa_r3 == wr_ad ) ;
wire eqwa31 = ( wa_r3 == wa_r1 ) ;
wire eqwa32 = ( wa_r3 == wa_r2 ) ;
wire inc_p0 = we_r3 & wr_en & eqwa30 ;
wire inc_p1 = we_r3 & we_r1 & eqwa31 ;
wire inc_p2 = we_r3 & we_r2 & eqwa32 ;
wire inc_p3 = we_r3 ;
wire we_p0 = wr_en & ~inc_p0 ;
wire we_p1 = we_r1 & ~inc_p1 ;
wire we_p2 = we_r2 & ~inc_p2 ;
wire [Bw_d-1:00] sum = brm_rd + inc_p0 + inc_p1 + inc_p2 + inc_p3 ;
// pipe0->pipe1
always @( posedge clk ) begin
we_r1 <= we_p0 ;
wa_r1 <= wr_ad ;
end
// pipe1->pipe2
always @( posedge clk ) begin
we_r2 <= we_p1 ;
wa_r2 <= wa_r1 ;
end
// pipe2->pipe3
always @( posedge clk ) begin
we_r3 <= we_p2 ;
wa_r3 <= wa_r2 ;
end
// pipe3->pipe4
always @( posedge clk ) begin
we_r4 <= we_r3 ;
wa_r4 <= wa_r3 ;
wd_r4 <= sum ;
end
// pipe3->bram wr port
assign brm_we = ( en_init )? ini_we :we_r4 ;
assign brm_wa = ( en_init )? ini_wa :wa_r4 ;
assign brm_wd = ( en_init )? ini_wd :wd_r4 ;
// bram rd port
assign brm_ra = ( en_extr )? rd_ad :wa_r1 ;
// bram instance
ss_ramb_sync_rgda
# (
.Bw_d (Bw_d ),
.Bw_a (Bw_a ))
ubram (
.wr_en (brm_we ), // i wr enable
.wr_ad (brm_wa ), // i wr address
.wr_di (brm_wd ), // i wr data
.rd_ad (brm_ra ), // i rd address
.rd_do (brm_rd ), // o rd data
.clk (clk )); // i clock
// output
assign rd_do = brm_rd ;
endmoduleおわりに
5回にわたって BRAM の基本的な説明から始まり、FIFO をアプリケーションの例として BRAM への適用について考えてきました。ジェネリック表現としての RTL があったり、Xilinx 提供の IP での実現があったりし、後半は筆者の設計ノートの様相を呈してしまいました。
自身で設計した RTL と IP、どちらが望ましいかは一概に決められるものではありません。その時々の要求によって、設計者が判断を迫られる問題だと思います。IP を用いることでリソースやタイミング制約上で有利となるのであれば、それを採用することは正当だと思いますし、IP で実現できないことは、設計者の努力で実現手段を確立するのがエンジニアの楽しみではないかと考えます。たくさん考えましょう!
今回の記事を書くにあたり、改めて BRAM について勉強をし直しました。BRAM を使い始めてずいぶん経ちますし、それなりにわかっているつもりでしたが、調べてみると多くの発見があり、筆者としても多くの知見を得ることができました。その際には、Xilinx や Avnet のサポートの方々に大変お世話になりました。また、東京工業大学の吉瀬先生には、記事の掲載にあたって随分とお手数をお掛けしました。この場を借りて御礼申し上げます。ありがとうございました。
エンジニア 鈴木昌治
参考文献
UG573 (v1.11) 2020年8月18日「 UltraScale アーキテクチャ メモリリソース ユーザー ガイド」
UG1037 (v4.0) July 15, 2017 「Vivado Design Suite AXI Reference Guide」
PG150 (v1.4) January 21, 2021 「UltraScale Architecture-Based FPGAs Memory IP LogiCORE IP Product Guide」