
このコースもいよいよ最終回となりました。最後は、宇宙物理アプリケーションの支配的な処理である ART 法を加速する FPGA アクセラレータの性能が FPGA の台数に応じてどのようにスケーリングしていくかを評価していきます。
性能評価
評価環境
本論文では、FPGA アクセラレータの実行性能を GPU の実行性能と比較しながら性能評価を行っています。そのためのプラットフォームとして、計算科学研究センター (以下、当センター) で稼働している以下の 2 つの HPC システムを使用しています。
Cygnus スーパーコンピュータ

Cygnus は、日本電気株式会社 (NEC) により、当センターに2019年3月末に導入されたスーパーコンピュータです。計算科学研究センター (CCS) では、長年に渡りスパコンの研究開発を続けており、Cygnus は CCS 独自開発の第10世代スーパーコンピュータとなります (CCS 歴代のスパコンに興味がある方はこちらを参照してください)。
この記事で紹介されているように、Cygnus はマルチ・ヘテロジニアスなシステムであり 81 ノードから構成されています。そのうち、32 ノードは Albireo ノードと呼ばれ、CPU、GPU、そして FPGA を搭載しているノードです。Albireo ノードの構成および使用したソフトウェアを以下の表に示します。
| CPU | Intel Xeon Gold 6126 × 2 |
| CPU Memory | DDR4 192 GB (96 GB / CPU) |
| InfiniBand | Mellanox ConnectX-6 HDR100 × 4 |
| Host OS | CentOS 7.6 |
| Host Compiler | gcc 4.8.5 |
| MPI | OpenMPI 4.0.3 |
| OpenCL SDK | Intel FPGA SDK for OpenCL 19.4.0.64 |
| FPGA | Bittware 520N (1SG280HN2F43E2VG) |
| FPGA Memory | DDR4 2400 MHz 32 GB (8 GB × 4) |
| Comm. Port | QSFP28 × 4 |
| GPU | NVIDIA V100 × 4 |
| CUDA | 10.1.2 |
Pre-PACS version X (PPX) 実験クラスタ

Pre-PACS version X (PPX) は当センターが開発を計画している PACS シリーズ・スーパーコンピュータ次世代機の実験クラスタシステムです。その用途から、様々な仕様のノードが混在していますが、評価では Intel Stratix 10 FPGAを搭載したノードを最大4台使用しています。4 枚の FPGA ボードは 100 Gbps 通信が行える光ケーブルで接続されており、2 x 2 の 2D トーラスネットワークを構成しています。ノードの構成および使用したソフトウェアを以下の表の通りです。
| CPU | Intel Xeon E5-2690 v4 × 2 |
| CPU Memory | DDR4 2400 MHz 64 GB (8 GB × 8) |
| InfiniBand | Mellanox ConnectX-4 EDR |
| Host OS | CentOS 7.3 |
| Host Compiler | gcc 4.8.5 |
| MPI | OpenMPI 3.0.1 |
| OpenCL SDK | Intel FPGA SDK for OpenCL 19.4.0.64 |
| FPGA | Bittware 520N (1SG280HN2F43E2VG) |
| FPGA Memory | DDR4 2400 MHz 32 GB (8 GB × 4) |
| Comm. Port | QSFP28 × 4 |
2 つのシステムを使用する理由
2 つのシステムを使う理由は、GPU の性能評価には Cygnus に搭載されている NVIDIA V100 を、FPGA の性能評価には PPX に搭載されている Bittware 520N を用いるためです。ですが、ノードの構成表を見ると「Cygnus スーパーコンピュータにも Bittware 520N が搭載されているのに、なぜわざわざ別のシステムを使わなければいけないのだろう?」と疑問に感じると思います。
Cygnus と PPX は同じ FPGA ボードを搭載しているにもかかわらず、FPGA の性能評価に Cygnus を用いない理由は、マルチ FPGA での ART 法の実行には CIRCUS の通信を利用するためです。
CIRCUS は通信機能を含んだ改造 BSP を用いるため、FPGA の書き換えおよび計算ノードの再起動が必要となります。しかしながら、Cygnus は本番運用に供されているシステムですので、ノードの再起動には制限が伴います (CIRCUS は研究のための試作段階のプロダクトであることもあり、気軽にシステムコマンドを叩いて再起動、ということはできないです)。また、Cygnus と PPX は同じFPGA ボードを用いており、計算を行うのは FPGA のみ (CPU は FPGA の制御に専念する) であることから、Cygnus 上で実行する場合と性能に大きな違いはないはずです。
これらの状況を踏まえて、FPGA の性能評価には PPX を用いることにしました。ちなみに FPGA の性能評価 でも MPI を用いているのは、各ノードに搭載されている FPGA 上で動作する OpenCL カーネルを、それぞれの CPU から起動するためです。
FPGA リソース消費量・動作周波数
| ALM | レジスタ | M20K | MLAB | Fmax [MHz] |
| 695,204 (74.5%) | 1,324,993 (35.5%) | 5,053 (43.1%) | 1,916 (33.3%) | 206.67 |
FPGA 実装のリソース消費量と OpenCL カーネルの動作周波数は上の表に示す通りです。ここで、ALM (Adaptive Logic Module) は Lookup Table (LUT) と Register から構成される論理回路ブロック、M20K は FPGA 内蔵 BRAM ブロック、DSP (Digital Signal Processor) は浮動小数点数演算や整数乗算を行うブロックであり、FPGA はこれらの回路ブロックをアレイ状に配置し、相互接続することによって構成されています (FPGA アーキテクチャを詳細に知りたい方はこちらを手に取ってみることをオススメします)。ちなみに、MLAB はメモリ・ロジック・アレイ・ブロックのことで、Xilinx FPGA の分散 RAM と同様に論理回路ブロックの LUT を利用したメモリモードです。
FPGA 版の性能評価には、Fitter が扱う乱数の Seed を何通りか試したものの中で最も動作周波数が高いものを採用しています。Seed とは、Fitter の配置ツールが初期配置コンフィグレーションとして使用するパラメータのことで、aoc -seed=X で指定することができます (こちらのブログに Seed についての説明があります)。Seed の値によって、動作周波数に 10 ~ 15 % の差が生じる場合があるので、OpenCL を用いてFPGA プログラムを記述する際は複数の Seed で合成を試してみる事が重要です (FPGA の非常に長いコンパイル時間を少しでも短くするために、ハイエンドな CPU とメインメモリを搭載した計算機にコンパイルジョブを投げましょう)。
FPGA リソース消費量は 8PE + CIRCUS 通信 (OpenCL カーネル と BSP) に割り当てたものです。表に示しているように、最も使われているリソース種別は ALM で、全体の 74.5 %のリソースを消費しています。一方、M20K や DSP にはまだ余裕があるので、より高い性能を達成できる数の PE を搭載するためには、ALM の使用量を M20K や DSP の使用量とバランスがとれるように実装を見直す必要があることが分かりました。
ノード数に応じた ART 法の演算性能
それでは、ART 法の演算性能が複数の FPGA を利用することによって、どの程度向上するかを見ていきましょう。性能評価には ARGOT コードから ART 法に関する部分を抜き出して制作したベンチマークプログラムを用いました。ART 法の計算のみを行うものであるため、ベンチマークプログラムの初期値は一様乱数で生成しています。
論文では、1 ノードあたり 1 つのアクセラレータ (Cygnus では GPU、PPX では FPGA) を使用し、最大4ノードで評価を行いました。ただし、FPGA 実装は扱える問題サイズが固定 (323) であるという制限があるので、GPU および FPGA 1 台あたり 323 の問題サイズで固定して、weak scaling の条件で ART 法の 1 ステップの計算時間を測定しました。weak scaling とは、ノード当たりの問題サイズを固定にしてシステムの並列度を上げた場合、システム全体がどの程度の計算能力を達成するかを測る指標のことです。weak scaling の条件では、全体の問題サイズがノード数に比例して大きくなるため、先ほどの指標は「一定時間でいかに大規模な問題を解くかを測る指標」と言い換えることができ、システム全体の処理時間が 1 ノードのみで実行した時間と同じであることが、この条件における理想的な並列処理となります。
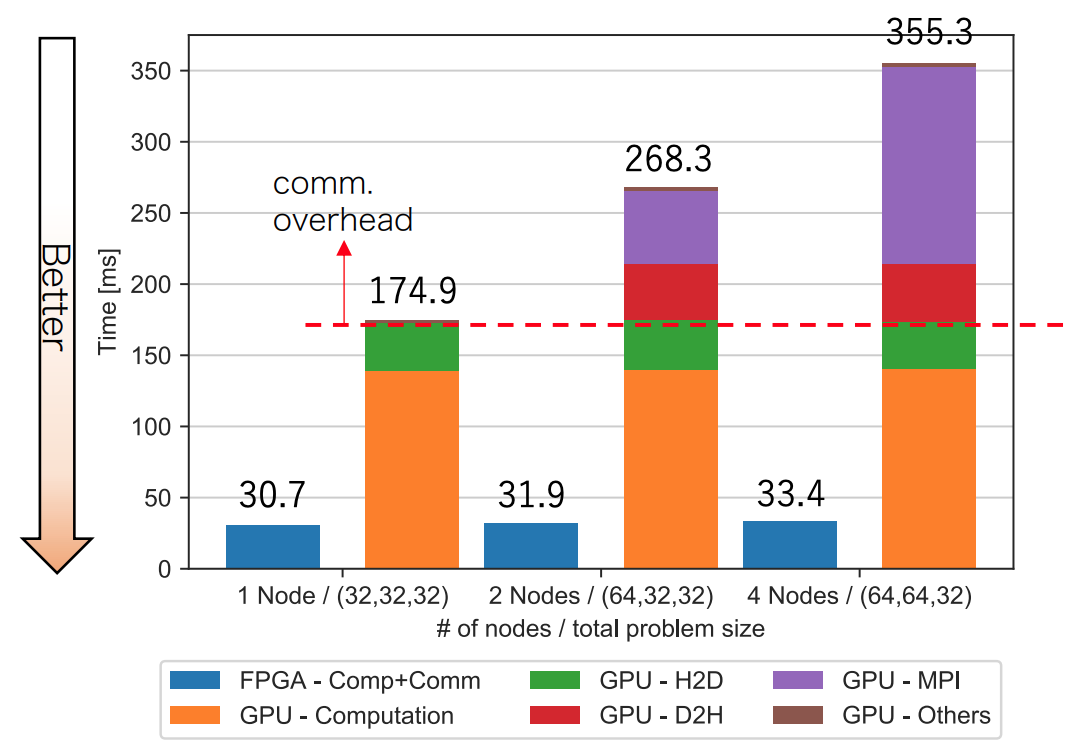
論文より引用
この結果は ART 法の 1 ステップの計算を 10 回実行し、最も処理時間が短いものを採用しており、データコピーによる初期値の配置と結果の取得にかかる時間は含まれていません。
GPU 実装では cudaEvent と gettimeofday 関数を用いて、Device to Host (D2H) 転送、Host to Device (H2D) 転送、計算、MPI ライブラリを用いた通信時間、その他に要する処理時間を計測しました。GPU 実装は、MPI 通信をホスト側から制御しているため、計算ループ毎に D2H、H2D 転送が必要になります。そして、MPI 通信が不要な時 (1 ノード) であっても、メッシュの境界条件を CPU から GPU に与える実装となっているため、H2D 転送は必要であることに注意して下さい。
FPGA での結果は、OpenCL カーネルの起動 (clEnqueueNDRangeKernel) から終了 (clFinish) までの時間を gettimeofday 関数を用いて測定したものです。GPU 実装と異なり、FPGA 実装は通信を含めすすべて FPGA で完結しており、また、パイプライン化によって通信時間を全体の実行時間から切り離すことができないため、全体の処理時間の内訳を示すことはできません。CIRCUS は FPGA 間の通信と各 FPGA 内の計算のためのパイプラインを構築し、この演算と通信を融合したパイプラインこそが、GPU に比べて遥かに性能が高くなる要因となります。そして 1 ノードの場合でも GPU 実装とは異なり、メッシュの境界条件の計算を含む全ての計算を FPGA 内で行うため、H2D 転送は発生しません。
FPGA と GPU の性能を比較すると、1 ノードでは 4.54 倍、2 ノードで 8.41 倍、4 ノードで 10.6 倍の性能差となっていることが分かります。GPU の実行時間と異なり、FPGA の実行時間はノード数を増やしてもほぼ一定であり、これはマルチ FPGA による並列処理が、上述した weak scaling 条件における理想的な並列処理に極めて近いレベルであることを示しています。
先述したとおり、FPGA 実装は通信も演算もパイプライン構造で一体化しているため、通信時間のみを抜き出して測定することが出来ませんが、ノード数の増加による実行時間の増加量を通信のオーバーヘッドとして定義し、評価を行うことはできます。以下に weak scaling の条件における並列効率を示します (1 ノードでの実行時間を T1、N ノードでの実行時間を TN としたとき、N ノードにおける並列効率は T1 / TN となります)。
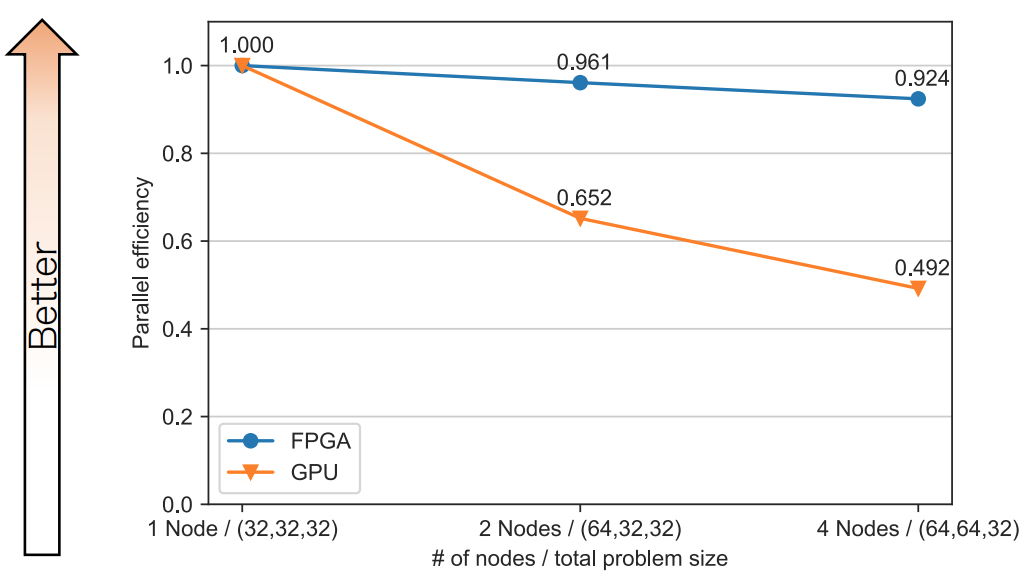
論文より引用
この結果は、CIRCUS が提供する FPGA 間通信によるものだと考えています。CIRCUS は、FPGAに直接接続されたインターフェースを使用しているため、オーバーヘッドの少ない高速 FPGA 間通信ネットワークを構築することができます。また先述したとおり、CIRCUS は通信パイプラインと組み合わせた通信パイプラインを構築するため、通信と計算を自然にオーバーラップさせることができます。その性質によって、マルチ FPGA での並列処理は GPU と比較し、高い効率を達成することが可能となります。
補足
GPU および FPGA 1 台あたり 323 の問題サイズで評価していますが、これまでの研究から、FPGA はパイプライン並列と空間並列の併用しているため 323 の問題サイズでも十分な性能が得られる一方で、GPU にとっては 1 枚あたり 323 という問題サイズは小さすぎることから、GPU に搭載される CUDA コア数に対して十分な演算の並列度が得られないことが分かっています。1 GPU に割り当てる問題サイズを 323 より大きくすると 1.5 ∼ 2.0 倍の性能向上が得られることが期待され (実際に、1283 では 1.6 倍の性能向上を達成しています)、また、ART 法の通信コストは O(N2) である (レイは面から入射する平行光であるため) のに対し、計算コストは O(N3)である (入射角度の総数を定数とした場合) ため、GPUでの並列効率は向上することが予測されます。
しかし、問題サイズを大きくして GPU に有利な状況になったとしても、FPGA の演算スループットは 323 の問題サイズとほぼ変化しないことがこれまでの研究から予測されるので、上記の事項を考慮したとしても FPGA の優位性は維持できると当センターでは判断しています。この仮説を定量的に実証するために、FPGA の外部メモリを併用して、より大規模な問題を解けるようにアクセラレータを拡張することが今後の課題となります。
まとめ
今回の記事では、宇宙物理アプリケーションを題材にし、それを複数の FPGA を活用し、高速化に成功したという研究成果について紹介しました。これで本コースの連載は終了です。
HPC の分野で FPGA をちゃんと使うためには、色々と考えなければならないことが多いですが、その分やりがいも感じられると筆者は思います。現在、紹介したこの研究を踏まえて、様々な研究成果を創出している最中ですので、もし、その情報について興味をお持ち頂いた方は、計算科学研究センターの広報に随時お問い合わせ下さい。
ここまでお読み下さった方々に厚く御礼を申し上げます。ありがとうございました。
筑波大学 計算科学研究センター 小林諒平