すべての現象は他のものに依存して名前を与えられたことによって生じ、存在している
ダライ・ラマ十四世 「空の智慧、科学のこころ (集英社新書)」より
(共著 : 茂木健一郎)
高位合成と C ベース設計 ~ はじめに
皆さん、はじめまして。Xilinx で FPGA を含む HW/SW の高位設計およびツールフローを担当している、黒田と申します。今回 Xilinx からの第3期ブログ連載 (全5回) の3回分を使い、対象がエンベデッドか?/サーバーか?にかかわらず、高位合成 (High-Level Synthesis : HLS) と Alveo カードを利用するアクセラレータ開発の心構え (というとエラそうで恐縮ですが…) について、お話をさせていただく予定です。
執筆に当たっては、メインの読者モデル/カテゴリとして、次のお2人を想定しています。
- FPGA を含むアクセラレータ設計について、興味を持たれる 「学生の方」
- 開発全体の設計生産性と組織体制について、問題意識を持たれる 「企業の方」
筆者の個人的な思いとしては、ACRi がその両者を結びつけるマッチメーカーになればいいな、という期待があるのですが、そのような読者モデルの皆さんと是非、3回の連載を通してこのブログの目的として共有したいのが、次の3つの 「問題意識」です。
- HLS と C ベース設計にまつわる (一部の) 間違ったイメージを払拭したい
- ヘテロデバイスの時代に求められるスキルや、組織の在り方について考えたい
- 1と2も踏まえ、現実目線で最良な設計手法/ツールフローに取り組みたい
読み進めるに当たっては、(目的を見失わないようコンパクトに全体を俯瞰する狙いから) 論理回路の RTL 設計や EDA ツールを使った FPGA 実装といった経験を当然のように前提とするような語り口にはなっていますが、そこは読者モデルの1人である学生を想定して参考資料を示しますので、補いながら気長に読み進んでいただければと思います。
論理回路の基礎や RTL 設計の入門として、分かり易くコンパクトにまとめられた連載 (全5回) があります。論理合成~配置配線ツールである Vivado のチュートリアルまで含む、とてもお得な内容です。ハードウェア設計の話が全くの初めてでしたら、少なくともこのレベルの内容は事前に押さえておくと良いでしょう。

あるいは、ここではざっと全体を読んで何となく概要というかエッセンスだけは掴んだつもりのレベルに留め、具体的には (ちゃんとした考えと体制を持つ/持とうとしている企業に) 就職した後で、経験を積みながら都度読み直していくというやり方もあると思います (むしろ実際はこちらかも知れません) 。
高位合成と C ベース設計 ~ 目次
はじめに
1.HLS に対する誤解を解く
1-1.ハードウェア記述言語としての C/C++
1-2.C ベース高位合成 (HLS) の基本
1-3.主な対象は計算アルゴリズム
1-4.HLS か?RTL か?という二択の話ではない
Coffee Break.デバイスベンダー製の垂直統合 EDA
2.アーキテクチャの検討
2-1.FPGA 優位のデザインパターンと典型問題
■ 高性能アーキテクチャの鉄則
■ タスク “内” の並列性と課題
■ タスク “間” の並列性と課題
■ HLS-C で表現できないケース
2-2.実装品質の限界まで求められるケースも
2-3.そもそもハードウェア化すべきなのか?
Coffee Break.最終形は「ML+X」over「AIE+PL」かも?
3.C ベース設計と開発フロー
3-1.HW/SW アクセラレータの先行開発
■ HLS カーネルでアーキテクチャ検討
■ RTL カーネルで実用の詳細設計
3-2.手戻りを速く回す C ベース設計手法
■ 全体から部分へ (タスク分割)
■ 部分から全体へ (カーネル開発)
Coffee Break.ヘテロデバイス時代の就活
参考情報
あとがき
高位合成と C ベース設計 ~ 1章 HLS に対する誤解を解く
1-1.ハードウェア記述言語としての C/C++
C/C++ をエントリーして回路 (RTL) を生成する、いわゆる高位合成 (High-Level Synthesis : HLS) について、皆さんはどのような印象をお持ちでしょうか?
Xilinx の高位合成ツールは、従来の狭義の意味では Vivado HLS です (今後は Vitis HLS と呼ばれます) 。HLS よりも “さらに高位の” HW/SW 統合ツールとして Vitis がありますが、もしかしたら皆さんの中では両者の違いはあいまいかも知れません。その違いについては後述しますので、今はそのままで構いません。
読者の皆さんがソフトウェアエンジニアかハードウェアエンジニアなのか、多少の経験をお持ちかそうでないか、といった状況の違いでいろいろあると思いますが、例えばこんな感じでしょうか。
- C/C++ コードからツールが性能の良い回路を適当に生成してくれるなら楽だな
- FPGA の経験が無いソフトウェアエンジニアでも C/C++ で簡単に設計できそう、etc.
実際に (ちょっとは) 触ってみた方々からはこう言われることもありました。
- C/C++ だけでハードを知らなくても出来そうに思わせておいて、全然性能が出ないじゃないか
- HLS はやっぱり手設計の RTL と比べて性能も品質もショボそうだね、etc.
そいういう話ではないんです、というのが筆者の主張になります。じゃあどういう話なのか?一言では済む話ではなく、この3回のブログを通してお伝えしていくことになります。
そのような捉え方をされてしまうのは、一つにはベンダー側から本来伝えるべきメッセージが上手く伝わらず誤解を生んだ側面があると思います。それは EDA の歴史に高位合成が登場して以来ずっと付きまとってきた話でもあります。
例えば、多分 Xilinx 自身そんなつもりは無かったとは思いますが、後に Alveo カードをリリースし、高位系のツール群を Vitis として統一することになるずっと以前に、HLS を中に含む SDSoC (エンベデッド向け) や SDAccel (サーバー向け) を SDx と呼び、以下のように紹介していた時期がありました (原文を味わっていただきたくて、あえて訳しません) 。
Xilinx SDx Development Environment
SDxTMis a family of development environments for systems and software engineers. SDx enables developers with little or no FPGA expertise to use high level programming languages to leverage the power of programmable hardware with industry standard processors on or off chip.
オイオイ、さすがにそれは言い過ぎだろう… と思いました。それでも、パブリックにそのような言い方をされてしまうと、これから学ぼうとするオーディエンスがそれを文字通りに解釈して上に挙げたような印象や期待を持たれても、仕方がないかも知れません。あと、programming とか programmable という単語が入っていますが、「ハードウェア設計においてハードウェアは記述 (describe) するものであってプログラミングではない」と本来は表現すべきであると考えるならば、そのようなちょっとした言葉遣いも、コンパイラが適当にやってくれそうだという誤解を生む原因の一つになるのかなと思っています。
また、「プロセッサ向けの SW コンパイラ (g++) vs. Vitis の HW/SW 向けコンパイラ (v++) 」、というような表現の対比で類推しようとすると、そこでも簡単に間違った期待をしてしまいそうです。
言葉遣いや表現も大事ですが、誤解を招くもう一つの大きな理由としては、HLS を含む Vitis フロー全体で実際に立派に実現できている機能そのものにあると思っています。つまり、1チップ開発まで含む HW/SW を、その内容は問わず実装するだけで良いのであれば、「ユーザーが用意するソースコードとして内容は適当でも C/C++ だけで済む」のは確かに間違いではないという事です。その点では、上の紹介文の中で “with little or no FPGA expertise” は正しいと言えてしまいます。
そのように言える理由は、以下の2つが前提としてあるからです。
- 1チップ上でアクセラレータ (カーネル) 以外の足回りの回路や、それらをソフトウェアのアプリから制御するためのランタイム API も含めた Xilinx 製のプラットフォームが、事前に用意されている
- その上で、HLS が C/C++ からカーネルを自動生成し、Vitis がそれとプラットフォームを自動接続する
なので、ユーザーとしては C/C++ のアプリから高性能化したい部分をパーティショニングして別コードに分けるだけで、ユーザー自身が1チップ開発を行う必要はないのです。
Vitis と HLS の関係については Xilinx からの第1期ブログ連載に分かり易い解説がありますので、参考にしてください (以下) 。ブラウザで新しいページを隣に開いて、それと照らし合わせながら読み進めると良いかも知れません。

大事な点なので繰り返しますが、Vitis の肝は「Xilinx が用意したプラットフォームにユーザーのカーネルを自動で繋ぐ」です。その中で HLS の役割は「カーネルを事前に生成する」です。
実は、Vitis は、カーネルの RTL 記述が HLS からの自動生成なのか人手によるものなのかは気にしません (というか区別できません) 。Vitis は与えられたカーネルをプラットフォームにただ繋ぐだけです。ちなみに、HLS を利用する以外に、カーネルの RTL を人手で記述して Vitis にエントリーするフローも用意されています。
ハードウェア実装に必要な RTL 記述の準備が自動か人手かで、前者を HLS カーネル、後者を RTL カーネルと呼びます。RTL カーネルについては3章で触れる予定です。
HLS カーネルであれば、アプリケーションの高性能化のための以下の工程を、ユーザーが用意するコードとしては全て C/C++ だけで進めらることになります。
SW アプリ → HW/SW パーティショニング → カーネル設計 → 1チップ HW/SW 実装および検証
ここまでお話しした上で、冒頭に挙げたような誤解から来る “不満” あるいは “嘲り” の理由は何かといえば、「HW/SW アクセラレーションするつもりで Vitis を実行したのに性能が出ない」ことですが、その元を辿れば「カーネルがショボい」ことになります。ではなぜカーネルがショボいのか? その理由は、パーティショニングは行ってアクセラレーション対象の C/C++ コードが用意されてはいても、「ハードウェアの設計は何も為されていない」から、です。HLS は C/C++ からカーネルを自動で生成してくれますし、Vitis はそれをプラットフォームに自動で繋いでくれます。でもその前に人間がまずカーネルをちゃんと設計してあげなくてはなりません。
カーネルのハードウェア設計とは、“設計言語が何であれ”、以下を行うことです。
高性能アーキテクチャを描く → そのアーキテクチャを記述する → 記述した内容が期待通りか検証する
HLS カーネルの場合には、アークテクチャを C/C++ で記述します。なので、HLS にエントリーする C/C++ は、プログラムではなくハードウェア記述言語 (Hardware Description Language : HDL) としての C/C++ です。そして、ハードウェアを記述するということは、記述すべきハードウェアのアーキテクチャが事前に描かれてないといけない。つまり、記述の前に、
- パーティショニングした C/C++ コードを解析/理解した上で、
(どのようなパーティショニングであるべきか?も同時に議論しながらですね) - 高性能を実現するカーネルのアーキテクチャを、人間が考えて描く、
(途中で、そもそもハードウェア化する意味あるのコレ?という話もあり得ます)
ということです。ツールではありません。そこだけは人間にしか決められないし、出来ない作業です。くどい言い方にはなりましたが、この当たり前の事をしっかりと押さえていただきたいと思います。
パーティショニングしただけの C/C++ コードはハードウェア記述ではなく、その後のハードウェア設計のための機能参照モデル、あるいは設計したハードウェアを検証するための期待値データ生成モデルとして扱います。
上述したハードウェア設計の3工程のうち、FPGA デバイスをターゲットにした時に、「高性能アークテクチャ」とは何か? について、2章で論じます。
次に、描いたアーキテクチャを C/C++ でどのように「記述する」のか? それが HLS そのものに関する話の肝になります。本章で概要を、2章でアーキテクチャの話とセットで、論じます。
また、カーネル単体だけでなく、1チップ HW/SW 全体まで見越してどのように「検証する」のか?も大事なテーマです。同様に本章で概要を、3章で実機 (Alveo カード) を利用するフローの話と併せて、論じます。
本節の最後に、筆者が EDA 業界にいた頃によく参照していた HLS 本、BLUE BOOK をご紹介します。

題材として使われているツールは Mentor 社の Catapult C Synthesis ですが、C ベースの高位合成の基本については Vivado HLS と共通の内容なので、その意味では HLS そのものの参考書としておススメです。
C/C++ の記述スタイルについては、プラグマ (1-2節で後述) やハードウェア向けデータ型のネーミングやシンタックス、それに紹介されているライブラリ関数 (いろいろな粒度のハードウェア機能部品) の仕立て方など、具体的な違いがあります。
以下は BLUE BOOK の「おわりに」の抜粋ですが、HLS がこれまで誤解を受け続けてどのような目に遭ってきたかが垣間見られるような気のする (筆者だけ?) 文章です。こちらも是非、原文のニュアンスを味わっていただきたいと思います。
Some Final Thoughts
(中略) Remember, High Level Synthesis is only a hardware design methodology. It requires “hardware designer” to realize the productivity gains over RTL design. It isn’t going to turn everyone into hardware designers, but it will allow hardware designers to match the ever-increasing complexity of ASIC design.
先ほどの SDx の紹介文とは真逆の印象ですね…。最初の Remember は筆者の耳には「いいかい、よくお聞き。」と響きます。あと “hardware designer” と引用符で囲っているところなんて、あの分厚い内容を書き切った後もなお鎮まらない苛立ちのようなものを感じます。高位系のツールを担当する中で、これまでに冒頭で触れたような誤解に遭遇するなど落ち込むことも多かったのですが、その度に筆者はこの文章を読んで (BLUE BOOK の著者も恐らく自分と同じような目に遭っていたに違いないと思い) 励まされたものです。
HLS の基本については後で触れますが、この連載は単に HLS の話だけでは終わりません。
上で挙げた BLUE BOOK の引用文の中で最後の文章では (ASIC を FPGA に置き換えても基本は同じです) EDA の根本のミッションを主張していますが、それは、デバイスの集積度と機能の複雑度の増大のペースに追随していくために、開発全体の設計生産性の向上を目指すことであり、HLS に即して言えば、 (手設計) RTL に対する設計生産性の向上です。
ここでも誤解されるのですが、その話をすると、筋金入りの RTL 設計者の方々から冒頭に挙げたような類のコメントを頂くことがよくあります (もとい、ありました) 。筆者にとっては “HLS あるある” の一つで、その件については「そういう話ではないんです論」の一つとして、1-4節と、3章では全体に亘って、展開させていただく予定です。
その上で本連載では、高位合成 (HLS、Vitis) と Alveo (アクセラレータ カード) を使い、ビジネスとして成立するレベルの高性能 HW/SW アクセラレータあるいはカーネルを、短期間で開発するためには何が必要か?をお題として、それを技術論だけでなく、経営・組織論の観点も併せて論じたくて、その問題意識を想定読者モデルの皆さんと共有したいのです。HLS に関する正しい理解はそのための出発点になります。
本連載のロゴのイラスト (上) はそのことを全身で表現している (つもり) です。
つまり、「HLS でアプリを加速しましょ~」はもちろんそうなんですが、もう一歩踏み込んで「HLS で開発全体を加速しましょっ!」が本当はお伝えしたいメッセージなんです。
ということで、まずは HLS の成り立ちを知るところから始めたいと思います。
1-2.C ベース高位合成 (HLS) の基本
1-1節の復習になりますが、仮に今、手元に C/C++ コードがあって、以下の状況にあったとします。
- アクセラレーション対象とする C/C++ コードをパーティショニングし、
- その解析を元に高性能を実現するカーネルのアーキテクチャを描き、
- それを (くどいですが、HDL としての) C/C++ で記述できている
さて、その C/C++ を HLS ツールにエントリーすると、
- そこで何が行われ、
- どんなハードウェア (RTL) が生成されるでしょうか?
- 人手で RTL を記述するのと何が違うでしょうか?
そのための取っ掛かりの簡単な例題として、浮動小数点の加算を取り上げ、以下のスライドに沿って HLS 実行の各工程を見ていきましょう。
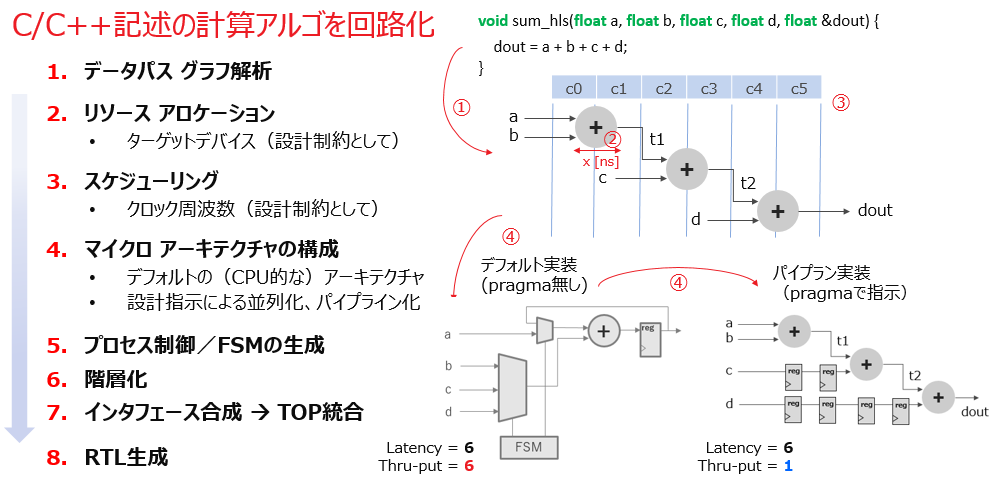
HLS には、ハードウェア化対象の C/C++ コードを ”関数として“ エントリーします。
C は C でも HDL としての C ですよ! としつこく繰り返していますが、この例題について見ると、C なので考えてみると当たり前ですが、浮動小数点の加算式という以外に、回路としての具体的な記述は何一つ見当たりません。
HLS はまず、与えられた C/C++ コードを解析してアルゴリズムを複数の演算要素に分解 (アセンブリング) し、それら要素の演算とデータパスのグラフとして、全体を捉え直します。これが1の「データパス グラフ解析 (①) 」の工程です。
次に、ユーザーが選んだデバイスのテクノロジーリソース情報 (論理セルやマクロの遅延情報, etc.) を元に、FPGA リソースを各演算へマッピングしていきます。これが2の「リソース アロケーション (②) 」です。それによりグラフの各要素に遅延情報が付加されます。
HLS の実行に当たってユーザーは、グローバルな設計制約情報として、ターゲットデバイスの指定 (上述) の他に、目標のクロック周波数を与えます。クロックの情報とグラフに付加されている遅延情報から、データパスの全体が消費するクロックサイクル数 (あるいはステート数) が得られます。ハードウェア性能のうち、“少なくともレイテンシ (一回の処理に費やすサイクル数) は” 確定したことになります。これが3の「スケジューリング (③) 」です。例題では、それが6サイクルだと言っています。
具体的な回路化が始まるのはここからです。
HLS は与えられた設計指示に従って、C/C++ では記述しない/できない詳細レベルの回路構成 (これをマイクロアーキテクチャと呼んでいます) を決めていきます。その設計指示はローカルな C/C++ 記述に対してはプラグマ文の挿入、グローバルにはディレクティブ (ツールに対するコマンド) の形をとります。これが4の「マイクロアーキテクチャの構成 (④) 」の工程です。
C/C++ 記述に対してプラグマが何も適用されていなければ、それをデフォルトのマイクロアーキテクチャの指示とみなし、例題ではスライドに示すような、“逐次処理” の回路を構成します (④の左) 。
例題ではスケジューリングの段階 (③) でレイテンシの6サイクルが分かっていましたが、逐次処理だと ”スループットとしても“ 6サイクルになります。つまり、複数のスカラーを次々と最速で入力したいと思っても、6サイクル毎にしか入力を受け付けない演算器という事になります。サイクル毎に連続して入力を受け入れるような、いわゆるパイプライン構成 (スループットが1サイクル) のマイクロアーキテクチャ (④の右) にしようとするなら、明示的にプラグマ文でその指示を与える必要があります。
ちなみに、HLS への期待として、プラグマを与えなくてもマイクロアーキテクチャをツールが勝手に決めてくれればいいのに、という声がありますが、筆者は反対の意見です。
なぜなら、 (マイクロ) アーキテクチャは外部要因を踏まえた設計目標を元に設計者 (人間) が決めるべき自由度を持つもので、ツールはそれを適当に決めて良い立場にはないからです。それを気を利かせているつもりで勝手にやられてしまうと、どのようなマイクロアーキテクチャになるのか設計者には事前には分からないということになり、却って面倒くさい (迷惑な) 話になります。それに対して、プラグマ無しのデフォルトが逐次処理と分かっていれば、設計者はプラグマを使ってそれとは違うマイクロアーキテクチャを自分で決められる (設計できる) のです。
C/C++ 記述とプラグマ文との関係について、(まずは簡単にですが) 説明できたので、ここから以降は、データパス回路の機能と構成を記述する C/C++ と、そのマイクロアーキテクチャを決める指示を与えるプラグマ文、それら両方を併せて HLS 向けの C ベースの HDL の代名詞として “HLS-C” と呼び、話を進めます。
HLS-C で記述/指定する必要のあるデータパス回路 (マイクロアーキテクチャ) 以外に、明示的な記述/指定が無くても HLS が勝手に作成してくれる制御回路/信号線があります。具体的には、設計者が確定したマイクロアーキテクチャに応じてデータパスの流れを制御するための信号を生成するステートマシン (FSM) です。
その他にも、HLS-C から回路化したいのが例題のようなスカラー入出力の単なる演算器の粒度ではなく、配列データを入出力として複数データを処理するアクセラレータの粒度であれば、開始 (start) と終了 (done) の認識が必要になるので、そのためのプロセス制御回路 (これも FSM を含みます) と、そこからの信号線~入出力ポートまでが (これも勝手に) 作成されます。
実際上の意味はなくても、スカラー入出力の簡単な演算器にも、プラグマを適用することで (無理やり?) start/done を持たせることは可能です。
それらが5の「プロセス制御/FSM の生成」工程になります。
また、HLS-C で記述する回路がもっと大きな粒度、つまり、トップレベルのアーキテクチャをハードウェアとして階層構成にしたほうがよい内容の場合には、それを (プラグマではなく) C/C++ 記述で明示的にサブ関数に分けて階層的に表現する必要があります。6の「階層化」の工程では HLS がその記述スタイルを踏まえ、サブ関数毎に適切なインタフェースを持ったサブモジュールを生成します。
階層構成のアーキテクチャが適している状況については2章で触れる予定です。
最後に、それらサブモジュールを統合します (その際はトップレベルで複数のサブモジュール間のスケジュールを管理する FSM も生成されます) 。トップ関数の引数に対して指定したプラグマの内容に従ってトップレベルのインタエースを作成し、内部のサブモジュール群と接続します。これが7の「インタフェース合成 → トップ統合」の工程になります。プラグマによる指定が無ければ、引数のタイプ毎にデフォルトのインタフェースが決まっています。
引数の各タイプとプラグマの関係性によるインタフェースの決まり方については、ユーザーガイドのUG902 (Vivado Design Suite User Guide : High-Level Synthesis) の1章をご参照ください。
HLS は C/C++ の関数からさまざまな粒度 (部品からアクセラレータまで) やインタフェースを持つ回路を生成できます。例えば、以下のスライドは、Alveo カードで想定しているインタフェースを持つカーネルの例です。
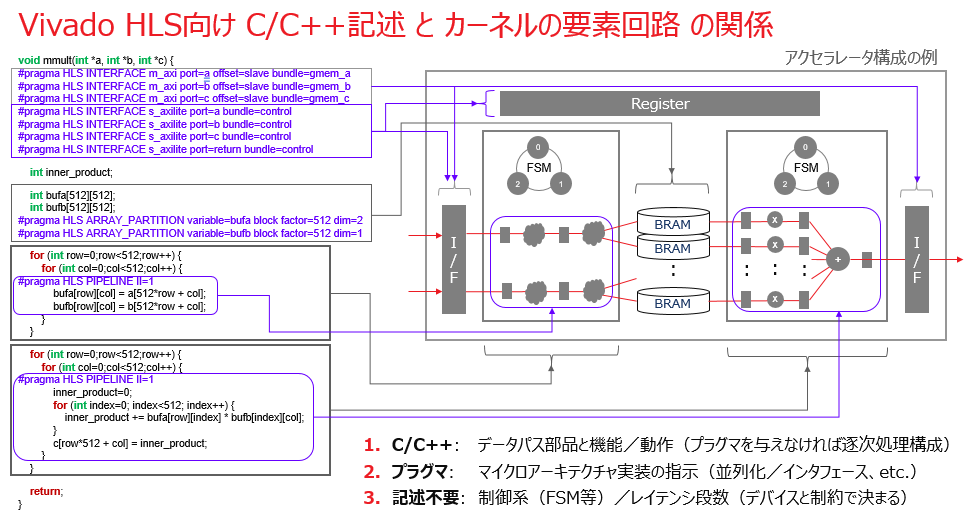
HLS の原理の説明で用いた例題は単なるスカラー演算器でしたが、こちらのスライドに示すカーネルの例はスカラーではなく、ポインタとして DRAM 上のサイズの大きな (配列) データにアクセスし、それらに対し並列度の高い演算をバーストで行えるパイプライン構成のアーキを記述しています。
アーキテクチャと HLS-C の関係については、2章 (次回の記事) で詳しく触れる予定です。
Vitis がこの HLS カーネルを、Alveo 上の FPGA 毎に用意されている既存のプラットフォームに自動接続してくれるよう、DRAM へのアクセスのためには AXI マスター、ホストからの制御 (オフセットアドレス設定、起動終了, etc.) のためには AXI Lite スレーブ、といった決め打ちのインタフェースに従う必要がありますが、ポインタ引数や return に対してプラグマを適用 (m_axi, s_axilite 指定) するだけで済みます。
この辺りの話についても、1-1節で紹介した同じ記事に分かり易く書かれていますので、併せてご覧ください。
以上の説明で、
- HLS-C (C/C++ とプラグマ) で何が記述できて、どのような回路が生成されるのか?
- HLS-C で明示的に記述しなく (できなく) ても生成される回路要素は何か?
を大体イメージできたと思います。
人手で RTL 記述する設計では、どのような回路であれ設計したい対象を “全て人間が記述” する必要がありますが、HLS-C ではデータパス機能や階層構成を C/C++ で記述し、そのマイクロアーキテクチャやインタフェースの種別をプラグマで指定するだけで、“残りは全て HLS が生成” してくれます。
これを HLS-C による回路表記モデルの「抽象化」と呼びたいと思います。HLS が生成する回路や信号のうち、記述上は捨象されているものがあるという意味での抽象です。それにより、人手による記述量が減り、コーディング生産性が UP します。

EDA の歴史の一つの流れとして、デバイスの集積度の増大と機能の複雑化のスピードに設計生産性が追い付くようにと、回路表記のモデルについては回路図/ネットリストから RTL へ、そして RTL から C/C++ (HLS-C) へと、それに伴って合成ツールも論理合成、そして高位合成へと、進化していきました。
上のスライドは、先ほど例題として見ていただいた浮動小数点の加算式の HLS-C 記述 (左端) を実際に Vivado HLS で高位合成して生成した RTL (真中)、およびそれを後段の Vivado で論理合成した結果のネットリスト (右端) を抜粋で示しています。記述量の違いに注目いただきたいです。
回路モデルが、ネットリスト → RTL → HLS-C へと移っていくにつれてコーディング生産性が UP することが分かりますが、理由はそれぞれ違います。RTL (論理記述) → HLS-C (動作記述) については抽象度の UP、回路図/ネットリスト (結線情報) → RTL (論理記述) については可読性が UP したことによります。論理合成によって RTL からネットリストに変換される際には、最適化によって削除される部分はあっても、回路全体の中に RTL 記述で捨象される要素は何一つありません。その意味で、RTL とネットリストの抽象度は同じです。
さて、そのような HLS-C 記述のエントリーから高位合成実行の7つの工程を経て生成された回路 (RTL) の内容について、以下の4点をログ情報やシミュレーションで確認し、問題が無ければ一丁上がりです。
- 目標性能 (カーネルの起動から終了までに要するクロックサイクル数) は達成しているか?
- 対象としているデバイスについてタイミング (セットアップ時間) は MET しているか?
- 同様に、目標の FPGA リソースの使用率 (LUT、DSP、BRAM/URAM) は達成しているか?
- 人手で記述した C/C++ と、HLS が生成した RTL は、機能的に同じ内容か?
1) については、設計がちゃんと出来ているのなら、事前に分かっているはずの内容です。期待するオーダーと結果が違っていれば、性能に影響する各マイクロアーキテクチャ (例えばパイプライン, etc.) の結果について精査する必要があります。
2) については、「はじめに」でも紹介した以下の入門知識があれば、レポートの意味は理解できると思います。
ちなみに、達成するクロック周波数が高いほど性能も UP するので、周波数の目標を出来るだけ高く設定したいところではありますが、対象デバイス毎にもちろん上限があります。
また、HLS (高位合成) の遅延見積もりは後段の Vivado (論理合成) ほど精度が高くないため、HLS でタイミング MET できない結果であっても、そのマイナス分 (negative slack) がクロック周期の1割未満であれば、後段の Vivado が吸収して MET してくれる場合が多いです。
3) についてはいかがでしょうか? LUT、DSP、BRAM/URAM は Xilinx FPGA を構成する論理素子やマクロブロックの事ですが、設計者はそれらの使用率の結果について何を期待している (あるいは、すべき) でしょうか?
企業が製品に FPGA を使おうとするときには当然、採算性を気にします。具体的には、製品の要件を満たす範囲内で最小のデバイス (面積、単価) を追及します。そのため RTL で設計をする場合には、機能や性能の目標に加え、推定される LUT やマクロを意識した記述スタイルを心掛けるものです。例えば、メモリであれば、デバイスベンダー毎でメモリマクロ (Xilinx だと BRAM/URAM) が確実に推定されるように RTL の記述スタイルを分けて用意するといった内規を、企業毎に用意されているかも知れません。デバイスベンダーからも RTL 記述スタイルに関するユーザーガイドが出ています。
HLS-C でハードウェアを記述する場合も基本は同じです。HLS で対象にするのは制御回路ではなく主にデータパス回路に限定されるので、その推定対象にしたい DSP や BRAM/URAM といった貴重なリソースの使用率が気になりますね。HLS-C ではデータパスの機能&構成を明示的に記述するので、C/C++ 記述とプラグマ文の内容から大体の想定をした上で結果に臨めると思います。それに、論理合成よりも高位合成のほうが確認サイクルを速く回せます。
最後の 4) はいわゆる等価性検証ですが、抽象度の違う C/C++ と RTL との間で機能的な等価性が担保出来ているかどうかを、シミュレーションで確認します。
高位合成 (HLS) でも、論理合成であっても、合成の前後で設計者は2種類の検証を行いますが、HLS の場合は以下のスライドに示すような内容です。
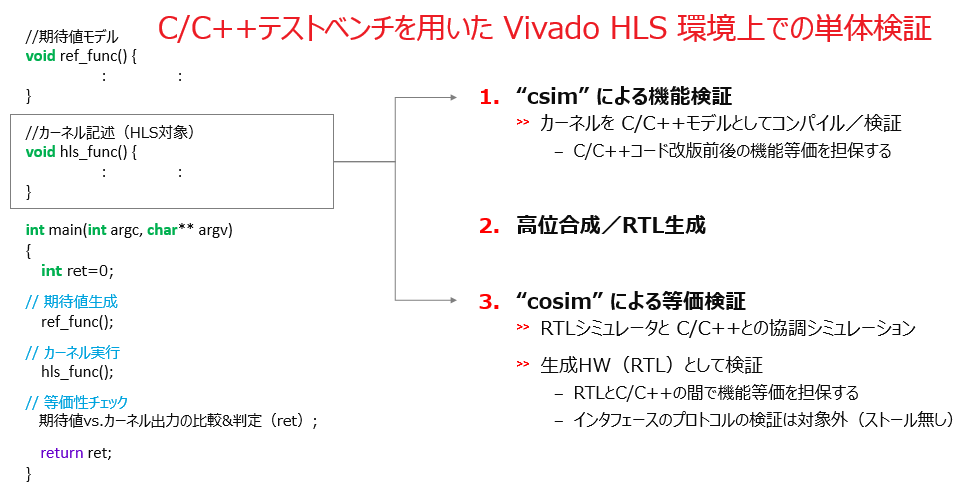
HLS の前にまず、設計者が HLS-C で記述したハードウェアについて機能検証を行います。ハードウェアの機能を C/C++ で記述するので、検証用のテストベンチも C/C++ です。参照モデルが生成する期待値と、回路モデルである HLS-C (関数) からの結果を比較するルーチンを含むテストベンチを用意して、HLS-C を更新する度にシミュレーションを実行してデバッグします。ハードウェアの機能検証ですが RTL と比べて抽象度の高い C/C++ でシミレーション (よく、“C-Sim” と言います) できるので素早く回せます。
HLS 実行で生成された RTL の等価性検証ですが、機能検証のために用意したのと同じ C/C++ テストベンチを流用します。生成されたのは RTL ですがテストベンチは C/C++ ということで、RTL シミュレーションと C/C++ シミュレーションを併せて実行する、いわゆる協調シミュレーションあるいは Co-Simulation (よく、“Co-Sim” と言います) を行います。
ちなみに、論理合成後に RTL とネットリストの間でも同じ理由で等価性検証を行うべきですが、対象が ASIC か FPGA かでかなり趣が違ってきます。FPGA はその名の通りプログラマブルなデバイスなので何度でも焼き直せますが、ASIC は一回勝負で後戻りできないので、心持ちからして全く違います。
RTL とネットリストの等価検証のやり方には2種類方法があって、シミュレーションによるダイナミックか、回路構造同士を直接比較するスタティックか、のどちらかですが、前者は避けたいと思うはずです。RTL シミュレーション自体が遅いのに、それがネットリストを用いるゲートレベルシミュレーション (ゲート Sim) になるとさらに遅くなるのが分かっていて多数の検証シナリオを実行するのは、気が引けます。ということで、ASIC の場合は論理合成の後工程の配置・配線にネットリストをハンドオフするための等価性確認はスタティックで行うのが常識になっていると思います。
スタティックだと、回路モデル同士を、その構造を直接比較することで検証できるので、テストベンチが不要でシミュレーションを流す必要もなく、検証シナリオの抜け漏れなど気にする必要がない完全検証になります。そんなスタティック検証/解析が可能なのは、上述したように RTL とネットリストの抽象度が同じだからです。HLS-C と RTL では抽象度が違い過ぎる (捨象している回路があったりサイクル精度も違う) ので、そんなツールがあると言われても、少なくとも FPGA に関しては、現実的ではなさそうな印象です。
RTL vs. ネットリストの等価性検証 (ゲート Sim として) 、FPGA ではどうでしょうか。多分ほとんど実施されていないのではないでしょうか。FPGA は何度でも焼き直せるので、RTL を Vivado に渡したら、あとはいきなり実機上で検証するのがほとんどではないかと想像します。デバッグも必要であれば、観測回路を埋め込んでの実機デバッグも可能ですし。
(以上、長い補足でした)
HLS フローにおいて、FPGA が対象で試しのフェーズでは特にスルーしたい工程だとしても、設計の手戻りを防ぐために Co-Sim は行ったほうがいいです。それをやらずに実装をして実機でハングったりすると、HLS-C とネットリストの抽象度が違い過ぎて、実機上でデバッグしてハングした箇所を特定できたとしても、頭の中で両者をクロスプローブさせることは、実際上できないと思います。
ですので Co-Sim は実行してほしいですが、C-Sim と違って Co-Sim は RTL シミュレーションを中に含むので、実行がムチャクチャ遅いです。そういう事もあって Co-Sim の実行は、本番向けの機能検証済み HLS-C を後段の工程にハンドオフするための儀式として、1回だけで (といっても、確認すべき検証シナリオはたくさんあるかも知れませんが) 済ませたいものです。
検証 TAT (Turn Around Time) を短縮したい話について、3章でもう少し突っ込んだ話をします。
Co-Sim が NG になるとすれば、理由は主に2つです。
- HLS-C vs. RTL の間で不一致が起きる
- シミュレーションがスタックする
まず 1) の不一致の原因の可能性としては、こちらも2つです。
- C/C++ (ソフトウェア) と RTL (ハードウェア) の間で振る舞いの違う対象の取り扱いを間違えている
- Vivado HLS がバグっている (^^;
A) の一例としては、未初期化の配列を参照するなどのケースです。サイズの大きな配列であれば、HLS が生成した RTL は BRAM/URAM にマッピングされるかと思いますが、初期化を行う回路を明示的に入れていない限りリセット後の値は不定です。C/C++ のコンパイラと HLS で違いがあると思います。
ちなみに、static 変数として定義した配列であれば、デフォルトだと Vivado HLS はメモリの0初期化を行う回路を自動で挿入します。
B) はあってはならない事ですが、100%無いとは言い切れません。ちなみにが多いですが、筆者が Xilinx に入社して6年の間にそのようなケースに遭遇してサポートが発生した事は、一度もありません。ですので、念のための Sanity Check です。それは論理合成も同じです。今後も出ないことを祈りますが、もしや?の際はお問合せください。。
Co-Sim が NG になる理由 2) のシミレーションがスタックする可能性については、特にサブモジュールで階層化されたデザインでモジュール間のデータをストリーム/FIFO を介して転送する場合にいくつか候補がありますが、主な原因はその FIFO が何らかの理由で詰まるというものです。
C/C++ で FIFO に相当するのはストリーム実装のための回路部品ライブラリとして用意されている hls::stream<> ですが、C-Sim で検証している間はそのようなスタックの問題は表に上がりません。データのサイズあるいは深さを無限として扱えるからです。
アーキテクチャ要素と HLS-C の関係については、2-3節で触れることにします。
FIFO、何それ?という方もいらっしゃるかも知れません。またこの問題は、階層デザインのアーキテクチャの理解を踏まえないとイメージできないと思います。ですので、2章であらためて触れることにします。
本章の後半では、このような HLS の立ち位置について、考えてみたいと思います。
1-3.主な対象はアルゴリズム
1-1~前節にかけて、EDA の歴史の一つの流れとして抽象化に向かう HDL の一つである HLS-C 言語と、HLS-C から RTL を生成する高位合成について、キーワードの定義を丁寧に確認しながら、それらの成り立ちを見てきました。
“HLS-C” を、データパス回路の機能と構成を記述する C/C++ と、そのマイクロアーキテクチャを指示するプラグマ文の2つを併せた抽象度の高い HDL の代名詞と定義し、人手による RTL 設計と何が違うのかいろいろと比較もしてみました。
人手による RTL 設計であればもちろん、1チップ全ての領域をフルスクラッチで好きなように開発できますが、設計生産性を追求しようとするとき、RTL よりも HLS-C のほうが適している部分として「計算アルゴリズムのアクセラレータ」というカテゴリを、 (1-2節では例題の取り上げ方からしてすでに仄めかしていたことではありましたが) ここであらためてハイライトしておきたいと思います。
その中で、HLS-C 設計の対象をさらに C-Sim で機能検証できる回路だけに絞ったほうが良い、と筆者は考えます。Co-Sim (RTL Sim) でしか検証できない HLS-C 記述にはメリットを感じません。その場合、計算アルゴのアクセラレータは、HLS-C ではなく人手の RTL 設計の対象になりますが、その場合は HLS-C に拘る必要もなく、RTL カーネルとして設計すればいいだけの話です。
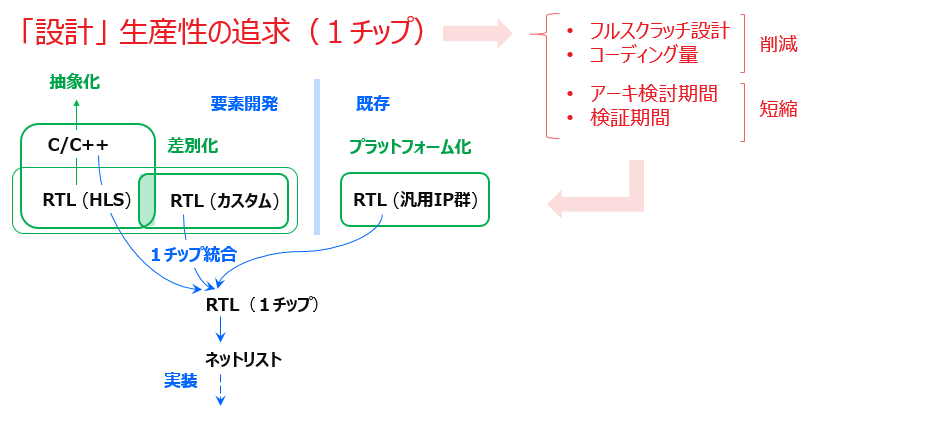
たまに、「HLS-C でこんな制御回路を設計してみました」というような事例紹介を目にすることがありますが、HLS-C 記述では制御回路は捨象されるものであって、HLS から勝手に挿入されるような立場にあることを思えば、そこをあえて積極的に HLS-C 記述の対象にするのは HLS の素性を考えると不自然かなと感じます。
ちなみに、別の C ベースの HDL として SystemC がありますが、アルゴのコアのデータパスだけでなく制御回路の領域にも手を拡げようとして支持が得られずに終わってしまった言語だったのかなと、筆者は勝手に考えています。少なくとも HDL としての SystemC を耳にすることは無くなりました。
例えば、HDL として全てを C++ で統一することにこだわって、アクセラレータのインタフェースを無理やりサイクル精度 (つまり RTL と同じレベル) で記述する SystemC のやり方に対して、デバイスベンダーである Xilinx は、汎用のインフラ部分をまずプラットフォームとして用意し、アクセラレータ/カーネルとの接続のためのインタフェースは決め打ちにしてしまい、それに応じて HLS カーネルでは関数の中身の機能記述は抽象的なまま、引数に対してプラグマを指定するだけでその決め打ちのインタフェースを実装できるようにする。また、Pure HLS-C では記述が難しい内容なら RTL カーネルにして、決め打ちのインタフェースを含むトップのラッパーは Vitis に自動生成してもらい、ユーザーは中身のコアだけを RTL 設計すればよいといった仕組みを用意してあげるほうが、設計言語の統一に拘る視点からすると「継ぎはぎ」と言われそうですが、「適材適所」とも言えますし、全体の設計生産性を UP させるやり方としては、はるかに現実的だと思われます。
1-4.HLS か?RTL か?という二択の話ではない
前節では、C-Sim で検証できないような内容であれば無理やり HLS-C で記述しようとしなくても RTL 設計でいいではないですか、といったコメントをしました。では RTL 設計であれば HLS は全く使わないのかといえば、そういう極論でもないという話をします。HLS の紹介をすると、すぐに HLS か RTL かという二択の話に持ち込もうとする方がけっこういらっしゃいます。筆者にはそれはある種の反射のように映ります。
最終的に RTL カーネルだったとしても、その設計生産性を上げられるよう HLS が貢献出来そうな用途として、まだ2つくらい残されているように思います。
- データパス回路の部品生成ツールとして
- アクセラレータ全体のアーキテクチャ検討のサイクルを速く回す手段として
1) については1-2節の中で、HLS-C からはさまざまな粒度 (部品からアクセラレータまで) のデータパス回路を生成できる点に触れましたが、例えば何か理由があって RTL カーネルを設計するとして、その中の演算器が HLS で生成した部品であっても悪くはないですよね。コーディング生産性の話では、浮動小数点の加算だけの数行の HLS-C 記述から、何百行の RTL、数千行のネットリストへと、膨れ上がっていく様子も見ていただいたと思います。
さらに言うと、仮にその浮動小数点の演算器を人手で RTL 設計したとして、その後の実装検討の結果、タイミング収束容易性のためにパイプラインレジスタの段数を増やそうという話が設計にフィードバックされたとします。RTL 記述に手を入れるのと、HLS-C のプラグマでその段数の指示を追加するだけで済ませられるのと、どちらが良さそうでしょうか?
部品の設計生産性も大事だと思いますが、この連載の本流のテーマとしてハイライトしたいのは 2) です。
アクセラレータを新規で開発しようというプロジェクトが始まったとして、それを (理由はともあれ) 製品向けに RTL カーネルとして設計する方針を決めたとして、
- どの辺りのタイミングで最初の RTL をコーディングし始めるものでしょうか?
- そして、最終版に向けてどのような進め方をするものでしょうか?
以下のスライドの中では開発手段/環境として C ベース設計/HLS のフローを見せていますが、今はそれを人手による RTL 設計に読み替えて見ていただければと思います。
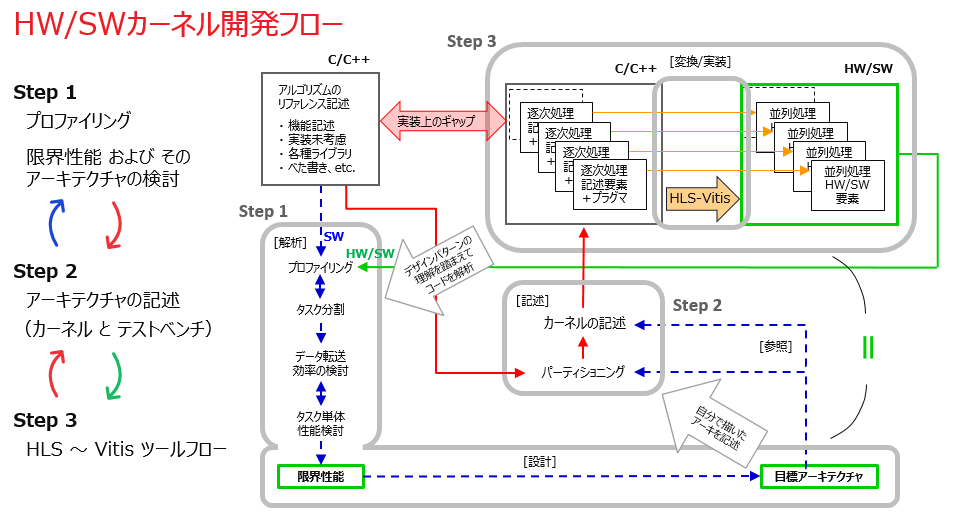
ちっちゃくて適当なものを開発しても競争力のある製品にはならないでしょうから、取り組むのは大規模でちゃんとしたものになると思います。製品の競争力を決めるのは設計言語やツール以前に、人間 (設計者) が考案するアーキテクチャだと筆者は信じていますので、まずはアーキテクチャ検討をしっかりと行うところから始まると思います。
FPGA 上の高性能アークテクチャの話は2章のメインテーマなのでここで始めたりはしないですが、大規模でちゃんとした (複雑な) 内容だとすると、恐らくハードウェアとして階層設計を検討することになると思います。機能レファレンスとするソフトウェアコードを解析してアルゴを理解するところから、アクセラレータの階層構成を検討、踏まえて各階層 (モジュール) 毎で並列性を実現するデータパスの検討、一回りしてやっぱり別の構成がいいかと再検討、それでもう一回りして。中にはパーティショニングまで戻っての再検討もあるのかなと想像したりもします。そういう試行錯誤も含むような検討を全て机上だけで完璧に行い、RTL のコーディングは最初から最終版として1回だけで済む、というような進め方でしょうか?
たとえ最終的に人手での RTL 設計で RTL カーネルの開発になったとしても、そのようなアーキテクチャ検討の工程に、HLS を持ち込んでその検討サイクルを加速できないか? そして、そういうやり方で進めたアーキ検討からのフィードバック情報を元に、それこそ最終版の RTL を1回でクイックに済ませられることにも繋がらないか? といった問題意識を筆者は抱いています。
それにアクセラレータ開発といっても、その対象はハードウェアだけでなく (サーバー向けだと特に) HW/SW 全体に及ぶので、アーキ検討を最初からアプリの文脈に置いた状態で進められるよう、そこに HLS だけでなく Vitis と Alveo とのセットで持ち込むのがいいのではないか?
そういった論点を持って、2章のアーキ検討、3章の設計手法/開発フローについて話を進めていき、最後にまた上の問いに戻って、皆さんと全体を振り返られればと思います。
Coffee Break. デバイスベンダー製の垂直統合 EDA
ふぅ。やっと1章の Coffee Break まで辿り着きました。ちなみに、筆者がここに至るまでに飲んだ Coffee、少なくとも100杯は下らないと思います (感覚です) 。読者の皆さんも我慢できずに、3杯目くらいでしょうか (それも、ここまでお付き合いいただけていればの話ですが…) 。
これまで散々 (?) C ベースの高位合成の話をしてきましたが、何を隠そう、筆者の高位合成との初めての出会いは C ベースではなく、MATLAB/Simulink ベースでした。
Xilinx にも System Generator (Sys Gen : ”シスジェン“と呼ばれます) という、Simulink 上で検証できる高位合成ツール (あるいはテンプレート合成と言うべきか…) がありますが、筆者が EDA 時代にサポートを担当したのは、かつて在籍していた Synplicity という EDA ベンダー (2008年に Synopsys に買収されました) が当時リリースしていた Synplify DSP と呼ばれる同じようなツールでした。
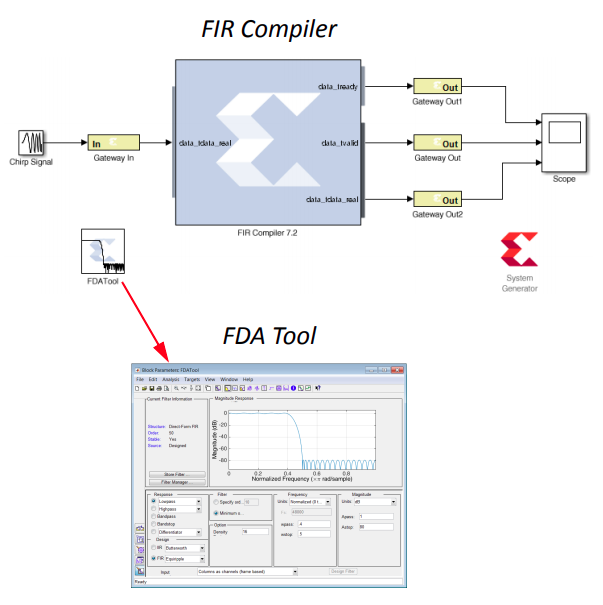
Synplicity 社と言えば FPGA 向けの定番の論理合成ツールが有名で、ターゲットの FPGA が Xilinx と Intel (当時は Altera) のどちらであっても、同じ記述スタイルの RTL から最適なネットリストを生成できるということで、一世を風靡した時期がありました。
Synplify DSP に話を戻すと、Simulink 上で設計対象になる回路は主に、いわゆる信号処理 (フィードバックも含む) でした。例えば、基地局向けのベースバンド処理とかです。
ユーザーにとっては、高位合成でなくても人手の RTL でも設計できるよと上司や周りから言われそうな状況の中で、EDA ベンダーに高額なツールライセンス料を払っても使いたいと主張できないといけない訳ですから、よっぽどの理由が無いと承認をもらえません (当然です) 。それで購入を決めた理由は何でしょうか?次の2つです。
- 信号処理のハードウェア設計のための検証環境として、Simulink 上で回路化対象やテストベンチを信号処理の文脈で分かり易く組めること
- 汎用的な機能要素について、信号処理の流れが分かり易い表記を保てて (上の図では FIR フィルタを示していますが、FIR フィルタの箱を一つ置いて終わりです) 、かつ FPGA 向けの実装品質がきちんと担保されること
1) については文句なしに納得です。ちなみに MATLAB/Simulink では信号処理の分野で規格になっているような検証用シナリオが揃っていて、それももう一つの大きな理由だと思います。
筆者にとっては 2) が問題でした。
FIR フィルタというのは以下のような構成になります。
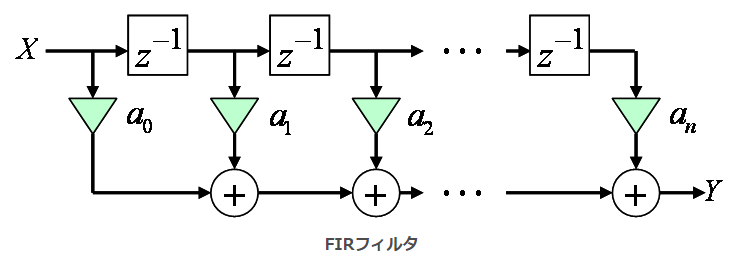
これを FPGA で実装しようとすれば、Xilinx の場合だと、ダイの上にも一列に並んでいる DSP48 スライスのカスケードチェーンへの推定/マッピングを期待したいところです (HLS 後の RTL の品質評価について上述しましたが、製品レベルの実装として期待する使用率、つまりデバイス単価の話に関わります) 。それが叶わないとツールを購入する意味は無くなります。
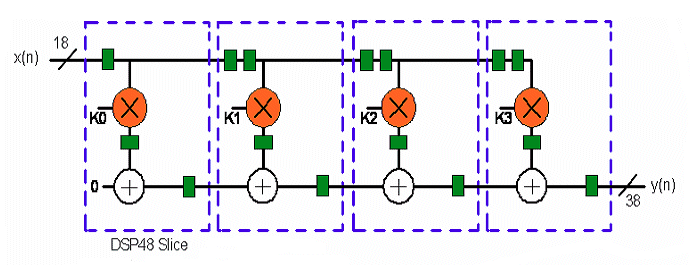
これが DSP48 を推定するのではなく、LUT を食い散らかして構成するのは嫌です。信号処理なのに DSP48 を使わずにロジックを消費するだけでもったいない上に、タイミング クリティカルな実装だと、目標のタイミング制約を MET しない状況にもなり得ます。
タイミング クリティカルと言えば、DSP48 への推定についてはもう一つ、そのマクロの中には積和だけでなくタイミング収束のためにリタイミング用のパイプラインレジスタが含まれていますが、Synplify DSP が生成する RTL を受ける後段の論理合成ツールである Synplify Pro が そのレジスタまで推定できるような記述スタイルの RTL を Synplify DSP が生成できているのか?という問題です。パイプライン用のレジスタを Simulink 上では挿入できて生成 RTL にそれを反映できていたとしても、Synplify Pro が DSP48 内のレジスタを推定できなければ、DSP48 の外にあるレジスタを推定することになり、無駄な実装になってしまいます。
幸いにも、Synplicity には 高位合成の Synplify DSP、論理合成の Synplify Pro の両方を持っていたので、EDA ベンダーとして、その間を擦り合わせられる開発体制にあった訳です。なんですが、当時は Synplify DSP の開発チームがトルコの首都のアンカラに (‼) 、Synplify Pro は米国とインドでした。日本でサポートする立場にある筆者が何に一番時間を使い、心を砕いていたか、それは Synplify DSP と Synplify Pro を擦り合わせるべく、お客様を含む4者の間を取り持つための交通整理でした。それでヘルペスを発症するくらいストレスを感じた記憶があります。
それでも良い事はあって、Synplify DSP を担当できたおかげで、生まれて初めてトルコに出張に行く機会を得ました。多分、それが最初で最後のような気がしています。
そのような辛くも良い経験が出来て、後で振り返ってみて、以下の悟りを得ました :
高位合成ツールは、論理合成ツールと密結合できてないと高価なオモチャでしかない
Xilinx の Vivado HLS は Vivado と密結合しています。さらに、Xilinx はその EDA がターゲットとするデバイスのベンダーです。その事を思い、もう一つ悟りました :
高位合成ツールは、デバイスベンダー自らが開発する垂直統合 EDA の中に組み込まれてこそ幸せだ
EDA ベンダーだろうと、デバイスベンダーだろうと、EDA 開発のために必要な人件費に変わりはないはずです。デバイスベンダーの EDA はお安く出来ているということではありません。ただ、その開発投資/コストの回収モデルが違うだけです。EDA ベンダーはそれを、ツールを利用するユーザーからツールライセンス料という形で直接的に回収するモデルです。一方、デバイスベンダーのツールは、EDA ベンダーのそれに比べると、ユーザーから見てタダみたいなものですが、それはその EDA 開発コストをユーザーから直接ではなく、デバイス収益の粗利からうっすらと満遍なく回収するモデルなので表面からは分からないだけです。多少の値が付いているのは、ツールをサポートするローカルのスタッフの人件費に回すためだと思います。ちなみに、Vivado HLS の Web Pack 版は本当に無償ですね。
そういう経験を経て6年前の2014年に Xilinx に入社し、その後1年経ったら、SDSoC がリリースされ、次に SDAccel、そして今は Vitis。Vitis に至っては、Xilinx 製のプラットフォームを前提に、カーネルの内容はともかく C/C++ だけで1チップ HW/SW 統合までやれてしまう、こういう事はデバイスベンダーである Xilinx にしか出来ない事です。
ASIC だと FPGA とデバイスの内容から違いますし、デバイスベンダーも複数いるので、EDA ベンダーとの分業モデルに意味があります。そういえば EDA ベンダー登場以前の昔の日本では、半導体ベンダー毎に EDA ツールを自社開発していましたね。HLS の記事を書きながら、そんな時代の日本を思った次第です (って言っても、筆者はその頃はまだ学生でしたが) 。
第2章へ続く
ザイリンクス株式会社 黒田成一