
1. はじめに
AMD (ザイリンクス) の FPGA は長年に渡り HPC やデジタル信号処理など演算負荷の高いアプリケーションに採用されてきました。昨今の 5G 無線通信や AI を含む機械学習の分野ではさらに高い演算密度と消費電力の削減が求められます。
※ ザイリンクスは AMD による買収が2022年2月に完了し、現在は AMD の一員です。
AI Engine (エイアイエンジン) はこのような背景から生まれた新しいプロセッサです。固定されたキャッシュ階層を持たず、マルチコアプロセッサ上でデータを移動させながら計算する、FPGA と相性の良いアーキテクチャを備えます。7nm 世代の Versal (バーサル) ファミリーの製品に搭載されています。
本記事では Versal デバイスを搭載する VCK5000 を使って AI Engine を動かすまでのチュートリアルを解説します。前半では、チュートリアルの内容を理解するために必要な基礎知識として AI Engine の特徴的なアーキテクチャや開発フローについて説明します。後半のチュートリアルでは AI Engine を使用する簡単なデザインを C++ だけで作成し、AI Engine プログラミングの雰囲気を感じつつ開発の流れの全体像をつかんでいただけるようにしています。チュートリアルの内容は、ACRi ルームに導入済みの VCK5000 を使って簡単に試していただけます。
※ 記事冒頭の画像は AI (Stable Diffusion) に描いてもらった AI Engine の絵です。本記事の内容とは関係ありません。
2. Versal ACAP
AI Engine は 7nm 世代 Versal ファミリーに搭載されるプロセッサです。畳み込み演算によるフィルタ処理や行列乗算など、昨今の 5G 無線通信や AI を含む機械学習の分野で必要とされる大量の演算を高スループット、低遅延、高電力効率で処理します。ソフトウェアのプログラマビリティを備え、かつドメイン特化のハードウェアアクセラレーションを提供します。
ここで Versal について簡単にご紹介します。Versal は演算エンジンとして Arm プロセッサ、プログラマブルロジック (PL)、AI Engine を搭載します。さらに各種インターフェースや DDR、DMA といった共通ブロックをハードマクロとして搭載します。これらは広帯域なネットワーク・オン・チップ (NoC) で相互接続され、チップ単体でヘテロジニアスなアクセラレータプラットフォームを構成します。
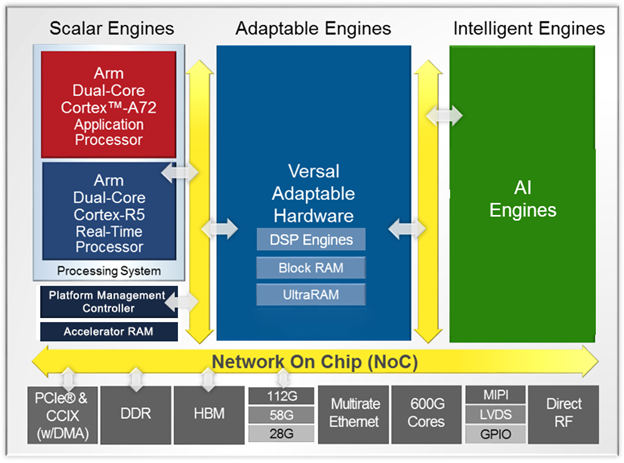
このように Versal はアクセラレータを実装するプラットフォームとして最適なアーキテクチャを備えることから、製品カテゴリとしては従来の FPGA とは区別して ACAP (Adaptive Compute Acceleration Platform、エイキャップ) と位置付けています。ユーザーは Versal が備えるヘテロジニアスな演算エンジンを活用して高性能、高効率なアクセラレータを実現できます。さらに各種ハードマクロを活用することで、限られた PL リソースをアクセラレータの実装に効率よく使用できます。
3. AI Engine アーキテクチャ概要
AI Engine (以降、AIE と略すことがあります) はコアとなるプロセッサ (AIE コア) が2次元上に配置され、プロセッサ間がデータメモリとインターコネクト、カスケードストリームで相互に接続された構造となっています。これを AI Engine アレイと呼びます。CPU などの一般的なプロセッサとは大きく異なるアーキテクチャです。
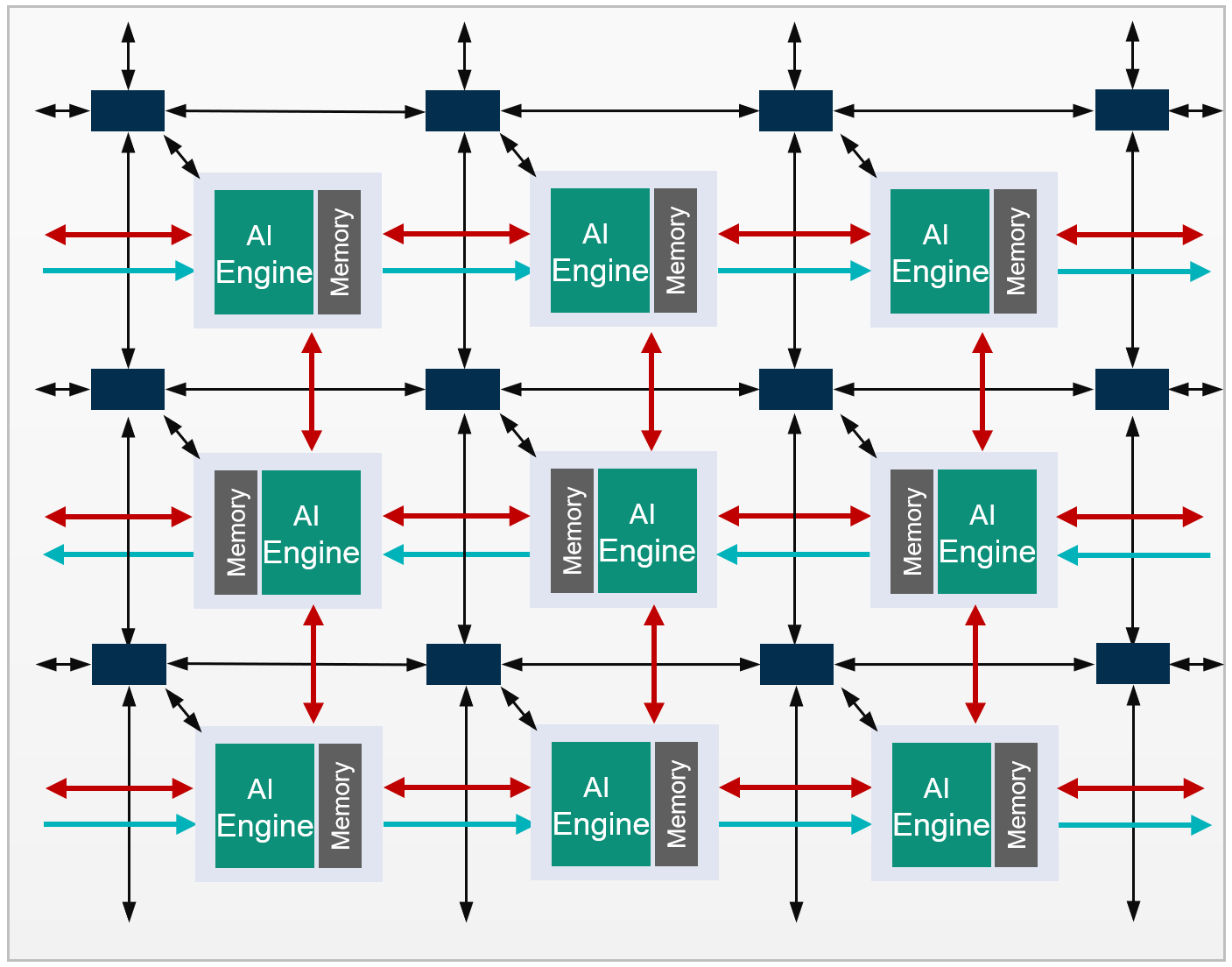
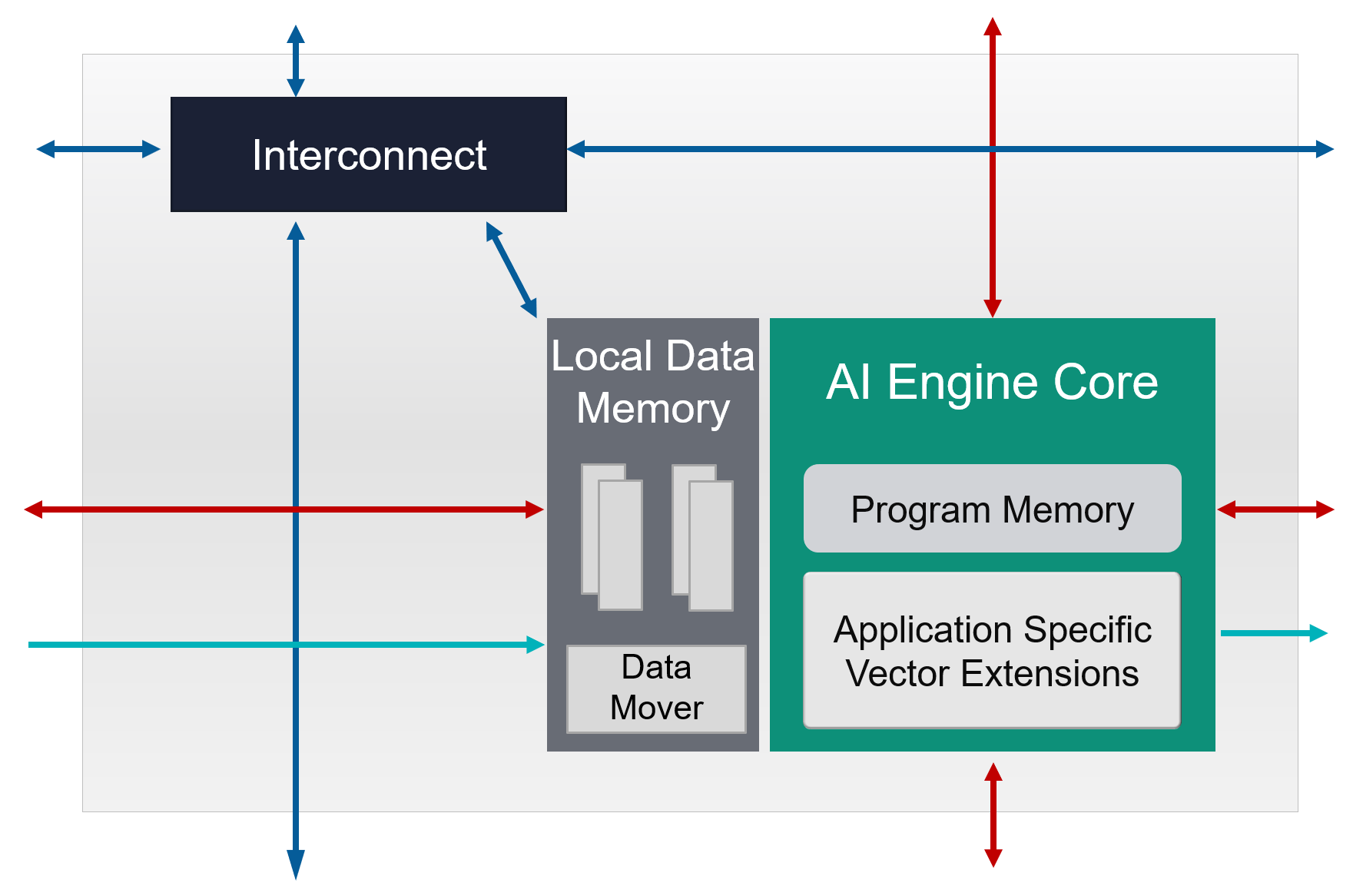
AIE アレイを分解すると、AI Engine タイルを縦横に繰り返し並べた構造になっています。AIE タイルは AIE コア、32KB のローカルデータメモリ、インターコネクトから構成されます。ひとつの AIE コアは、自身のタイルのデータメモリに加えて、隣接する (上下および左または右の) AIE タイルとデータメモリを共有し、計4つのデータメモリに直接アクセスできます (図中、赤矢印)。離れた AIE コア間ではインターコネクトを介して DMA またはストリームでデータをやり取りします (青矢印)。また、隣接する AIE コアに演算結果をカスケードするストリーム接続を持ちます (緑矢印)。
このように AI Engine では、プロセッサコア間が直接データをやり取りする複数の手段が用意されています。
AI Engine は一般的な CPU や GPU とはまったく異なるアーキテクチャとなっており、動作原理やプログラミング方法も異なります。
CPU や GPU では、実行するプログラムの内容があらかじめ決まっていないため、どのようなプログラムでも平均的に性能が出るよう、階層的なキャッシュを持つアーキテクチャとなっています。データが必要になったとき、キャッシュにデータがあればキャッシュから読み出し、そうでなければ DRAM から読み出す動作をします。これにより動作は非決定的 (実行するたびにタイミングが異なる) となり、キャッシュと DRAM との間では頻繁にデータコピーが発生します。このため、厳密に動作を予測することが難しかったり、データの移動に無駄が生じたりします。
一方、AI Engine ではフィルタ処理や行列演算など、あらかじめ計算内容が決まっている状況で、その計算に特化した専用のデータフローアーキテクチャを AIE アレイ上に構築します。プログラマが複数の AIE コアに計算を割り付け、AIE コア間を最適なインターフェースで接続し、データが AIE アレイ上を流れるようにして計算が進むようにプログラミングします。AIE アレイ上のデータフローはアプリケーションに応じて柔軟に構築できます。たとえば次の図のように複雑なデータフローを作ることもできます。
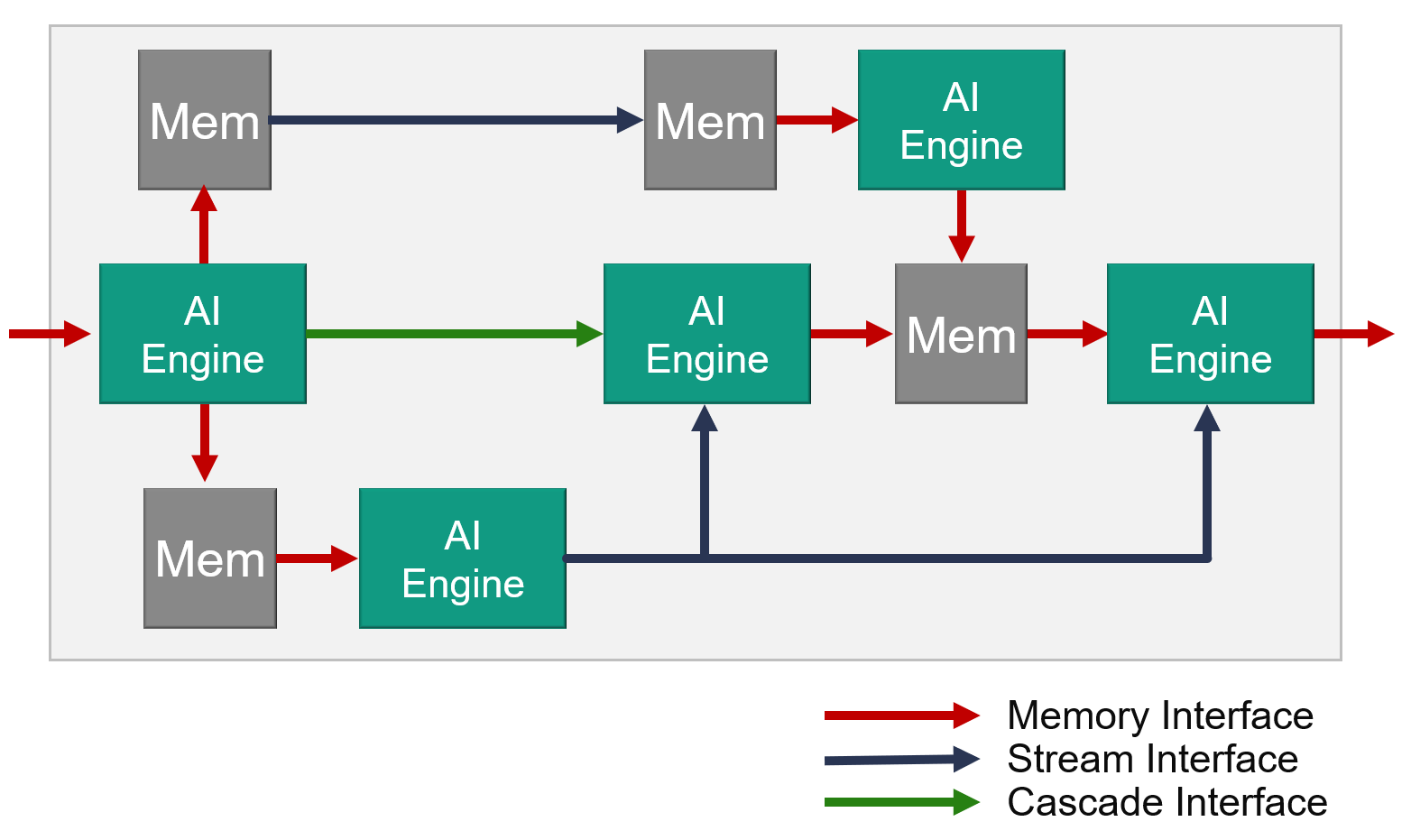
図中の矢印はデータ移動を表し、プログラマがコード上で明示的に記述します。各 AIE コアはプログラムにしたがって、必要な入力データが揃ったら計算して結果を出力します。この動作は決定的で実行タイミングを事前に予測できます。
DRAM へのアクセスは必要なときに必要なだけ行うため、DRAM 帯域を効率良く使用できます。DRAM アクセスを効率良く行うことができる一方、制限として AIE コアが直接アクセスできるデータメモリの容量は 128KB と限りがあるため、大きなデータは分割して処理する工夫が必要となります。
4. AI Engine コア
AI Engine コアは ISA (Instruction Set Architecture) ベースの VLIW (Very Long Instruction Word、超長命令語) プロセッサです。固定小数点ベクトルユニット、浮動小数点ベクトルユニットによる SIMD (Single Instruction, Multiple Data) をサポートします。
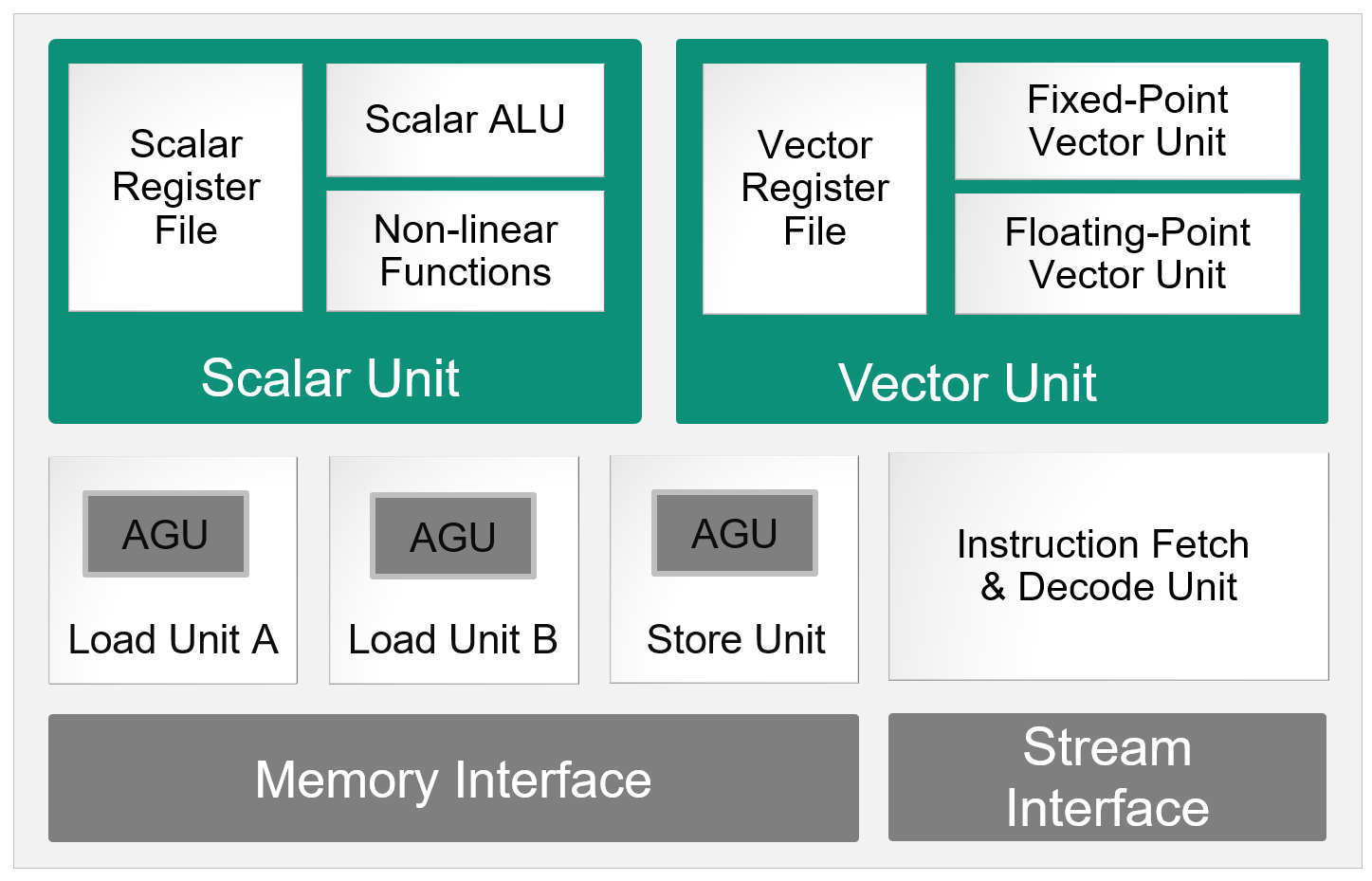
AI Engine コアでは、ひとつの VLIW 命令は7つのオペレータからなります。Instruction Decode ステージで命令がデコードされ、各オペレータは対応する実行ユニットに投入されます。7つのオペレータに対応する実行ユニットは以下の7つです。
- データメモリからレジスタへデータ移動する2つのロードユニット
- レジスタからデータメモリへデータ移動するストアユニット
- レジスタまたはストリームの間でデータ移動する2つのムーブユニット
- スカラユニット
- ベクトルユニット
各実行ユニットはパイプラインで動作し、AI Engine コア全体として1クロックあたり1 VLIW 命令を実行します。
VLIW プロセッサの一般的な特徴として、データ依存解析を含む命令実行のスケジューリングはプログラムのコンパイル時に決定されます。この性質により AIE アレイ全体の動作が決定的となります。
後ほどサンプルを使って紹介しますが、AIE コアのプログラムは C++ でコーディングします。コンパイラはプログラムの自動的な最適化や、プラグマベースのベクトル化は行いません。このため通常の C++ コードの書き方そのままでは性能が出なかったり、コンパイルが通らなかったりします。プログラマは専用の API を使いコンパイラが出力する VLIW アセンブリを意識したコーディングを行うことが重要となります。
ここで AI Engine の演算性能をみてみます。AIE コアのベクトルユニットでは、128要素の INT8 ベクトル同士を掛け合わせ (128回の乗算)、各要素をアキュムレータに足し合わせる (128回の加算) MAC 演算を1命令 (オペレータ) で実行できます。1命令は1クロックで実行されるので、コアあたり256 ops / クロックの演算性能があると言えます。ACRi ルームで利用できる VCK5000 では400個の AIE タイルが 1.25GHz で動作します。これより AI Engine 全体の演算性能は、256 ops * 1.25GHz * 400 core = 128 Tops となります。分かりやすく言い換えますと INT8 の演算を一秒間に128兆回行う性能があるといえます。
5. VCK5000 Versal 開発カード
VCK5000 は Versal デバイスを搭載し、ホストマシンの PCIe スロットに装着して利用するタイプのアクセラレータカードです。PCIe を介してホスト CPU と接続し、ホストアプリケーションの処理をオフロードする用途で使用できます。製品向けの Alveo カードとは異なり VCK5000 は開発キットの位置付けです。実際にデータセンターで運用することは想定されていません。Versal を搭載する将来製品に備えた性能評価や技術習得を行うためのプラットフォームとして利用できます。

VCK5000 では Vitis 開発フローがサポートされています。ACRi ルームでも Vitis 開発フローで独自のアクセラレータを開発することができる環境を整えています。Vitis については以前の記事でご紹介しました。

Vitis では、設計済みのソフトウェア (ドライバ、ユーザーレベル API) とハードウェア (DMA、カード管理など) をプラットフォームとして提供し、設計の一部を自動化することで、開発者はアクセラレータの本質的な開発に専念できます。
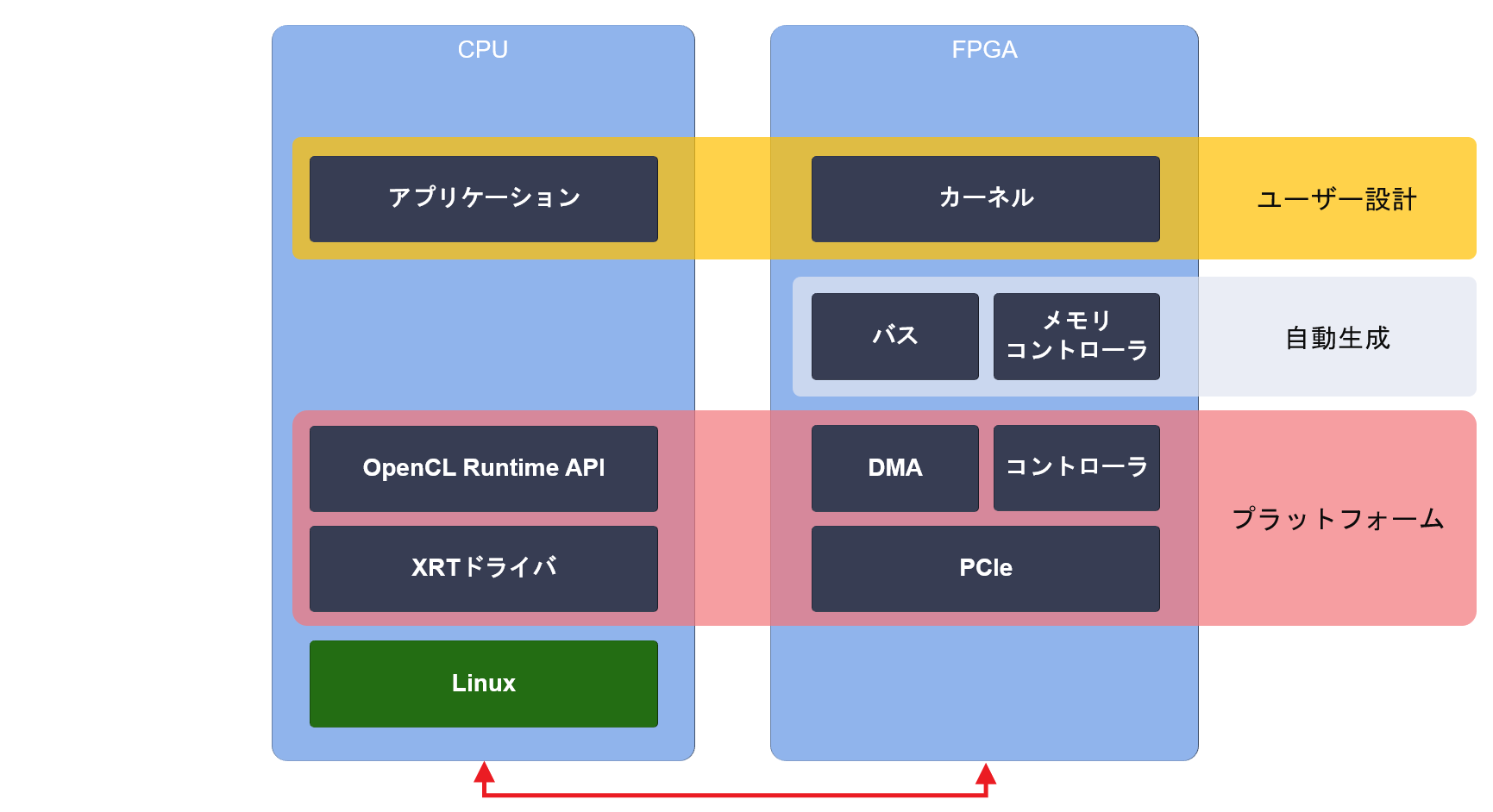
Vitis を利用するとホストアプリケーションからアクセラレータのハードウェアまでを C++ だけで記述できます。C++ のコードから RTL を生成する技術を高位合成 (High Level Synthesis、HLS) といいます。高位合成についてはこちらの連載記事で詳しく解説しました。
上記の Vitis と高位合成に関する記事を一冊の電子書籍にまとめ ACRi から出版しました。FPGA アクセラレータによる高速化の基礎的な考え方と、高位合成における設計メソドロジーをご紹介しています。
VCK5000 に話を戻しますと、VCK5000 の Versal デバイスは Arm プロセッサ (PS)、プログラマブルロジック (PL)、AI Engine を搭載します。またカード上に 16GB のメモリを搭載します。
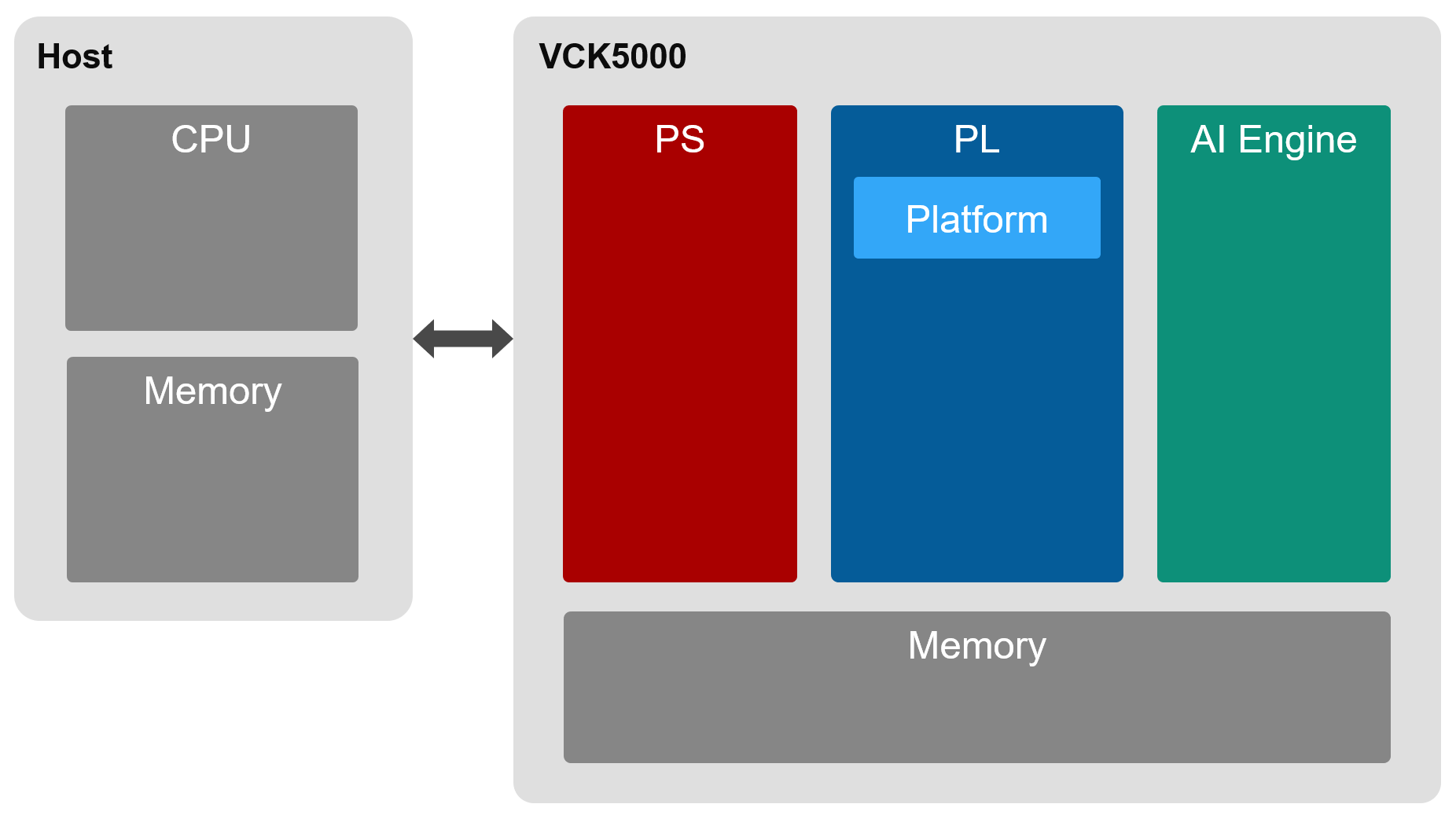
Vitis 開発フローでは PL に実装された Vitis プラットフォームを利用します。このプラットフォームを介してホストから PL の空き領域へのユーザーロジックのパーシャルリコンフィグと、AI Engine のプログラムを行います。PS ではカードの管理やプラットフォームの制御に関する処理が実行されます。
6. AI Engine 開発の流れ
ここで AI Engine 開発の流れについて説明します。
コーディングに着手する前に、まずは AI Engine に何を実装するかを考える必要があります。当たり前に聞こえると思いますが重要なことです。Versal は PS、PL、AIE を搭載するヘテロジニアスアーキテクチャですから、アプリケーションから高速化対象を切り出すときに、どの部分が PS、PL または AIE 実装に適しているかよく検討する必要があります。AIE を活用することで従来よりアクセラレート可能な対象が広がる反面、実装をどのように分割して割り付けるか (デザインパーティショニング) の見極めが重要となります。この見極めのためにそれぞれの演算エンジンの特性をよく理解しておく必要があります。
VCK5000 を対象としたときの AI Engine 開発では次のコードを作成します。
- AIE カーネル
- AIE グラフ
- PL カーネル
- ホストプログラム
AIE カーネルは、AIE コアで動作させるプログラムです。個々の AIE コアでは、データを受信し、計算して、結果を送信する、ということを繰り返し行います。このときデータはウィンドウまたはストリームで受け渡します。演算帯域にふさわしいデータ受け渡し方法を選択し、ベクトルユニットをうまく活用するコーディングを行います。
AIE グラフは、AIE アレイ上に構築するデータフローをグラフ構造として記述します。AIE グラフは AIE カーネルのインスタンスを表すノードと、データ接続を表すエッジで構成されます。AIE グラフに AIE の外部 (PL やメモリ) とデータ接続するための入出力ポートを記述します。AIE コンパイラは、AIE グラフを入力として AIE カーネルとデータ接続を AIE アレイ上にどのように配置するかを自動的に決定します (ユーザーが指示することもできます)。データが AIE と PL を行ったり来たりするようなデザインも可能です。
PL カーネルの実装には、従来の Vitis フローと同じく HLS (高位合成) や RTL が利用できます。PL に適した計算を実装したり、AIE とメモリの間でデータを移動するロジックを実装したりします。
※ 現在の VCK5000 プラットフォームではメモリと AI Engine が直接データを受け渡しする仕組み (GMIO) はサポートされていません。このため、AIE とメモリの間でデータを移動するロジックを PL に実装する必要があります。
ホストプログラムの実装には従来の Vitis フローと同じく XRT (Xilinx Runtime) を利用します。ホストプログラムでは、ホストメモリとデバイスメモリの間のデータ転送と、PL カーネルの起動を制御します。ホストプログラムでのデータ転送やカーネル起動には OpenCL Runtime API、または XRT Native API を使用します。チュートリアルでは XRT Native API によるプログラミング方法をご紹介します。
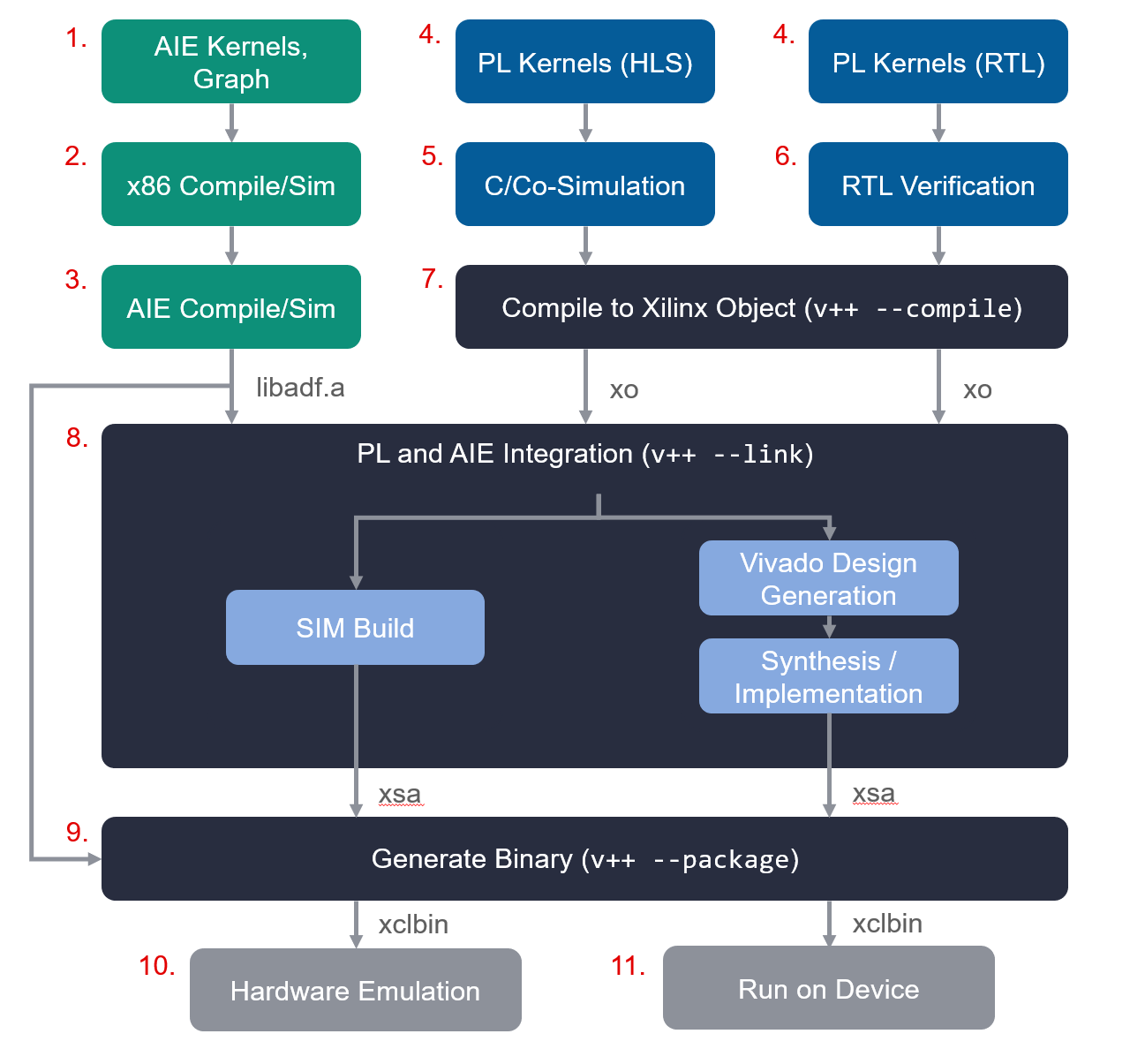
コード作成から実機で動作させるまでの開発の流れは次の通りです。
- AIE カーネル作成、AIE グラフ作成
- x86 向けコンパイル、x86 シミュレーションによる検証
- AIE 向けコンパイル、VLIW アセンブリレベルでの性能解析、論理シミュレーションによる検証および性能解析
- PL カーネル作成
- HLS カーネルの C-Simulation、Co-Simulation による検証
- RTL カーネルのシミュレーション検証
- Vitis による PL カーネルの Xilinx Object (xo) へのコンパイル
- Vitis によるターゲットプラットフォームへの PL/AIE カーネルの統合 (ハードウェアリンク)
- 実機またはハードウェアエミュレーション向けのバイナリの生成 (パッケージ)
- ハードウェアエミュレーション
- 実機動作
図で表すと次のようになります。
7. AI Engine チュートリアル
ここまで AI Engine の概要と開発フローを説明しました。説明だけでは分かりにくい部分が多かったかと思います。ここからは具体的なコードを使いながら AI Engine 開発の流れを詳しく見ていきます。
本記事のチュートリアルの内容は Jupyter ノートブックにまとめてあり、ACRi ルームで簡単に試すことができます。ACRi ルームのサーバー (as005 または as101~103、as105) にリモートデスクトップで接続し、ターミナル上で次のコマンドを実行するとブラウザが開き、Jupyter 上で AI Engine 開発を体験できます。
$ cd /scratch ... (as005で実行するとき)
または
$ cd /scratch/$USER ... (as101~105で実行するとき)
$ cp -a /tools/repo/acri-room/aie-tutorial .
$ cd aie-tutorial
$ ./start.shVCK5000 実機で動作させる場合は as005 をご利用ください。as101~105 ではハードウェアエミュレーションのみ実行できます。
このチュートリアルは acri-room/aie-tutorial でも配布しています。
7.1 実装するアプリケーション
このチュートリアルでは int 型の4要素のベクトルをふたつ足し合わせて結果を返す簡単な例を使います。C++ で書くと次のようになります。
#include <iostream>
#include <vector>
int main(int argc, char** argv)
{
// 入力と出力のベクトル
std::vector<int> in0(4), in1(4), out(4);
// 適当な値でベクトルを初期化
for (int i = 0; i < 4; i++) {
in0[i] = i + 2;
in1[i] = i * i;
}
// ベクトル加算
for (int i = 0; i < 4; i++) {
out[i] = in0[i] + in1[i];
}
// 結果を出力
for (int i = 0; i < 4; i++) {
std::cout << out[i] << std::endl;
}
}とても簡単ですね。このコードを実行すると次のように出力されます。
2
4
8
14この計算を AIE に実装してみましょう。
7.2 デザインパーティショニング
まずはアプリケーションのパーティショニングを考えます。とは言ってもこの例は簡単なのであまり考えることなく、ベクトル同士の足し算の部分を AIE で実行することにしましょう。AIE で計算するには、メモリと AIE との間でデータを移動させる必要があります。このデータ移動は PL カーネルとして実装する必要があります。システム全体のデータの流れを図で表すと次のようになります。
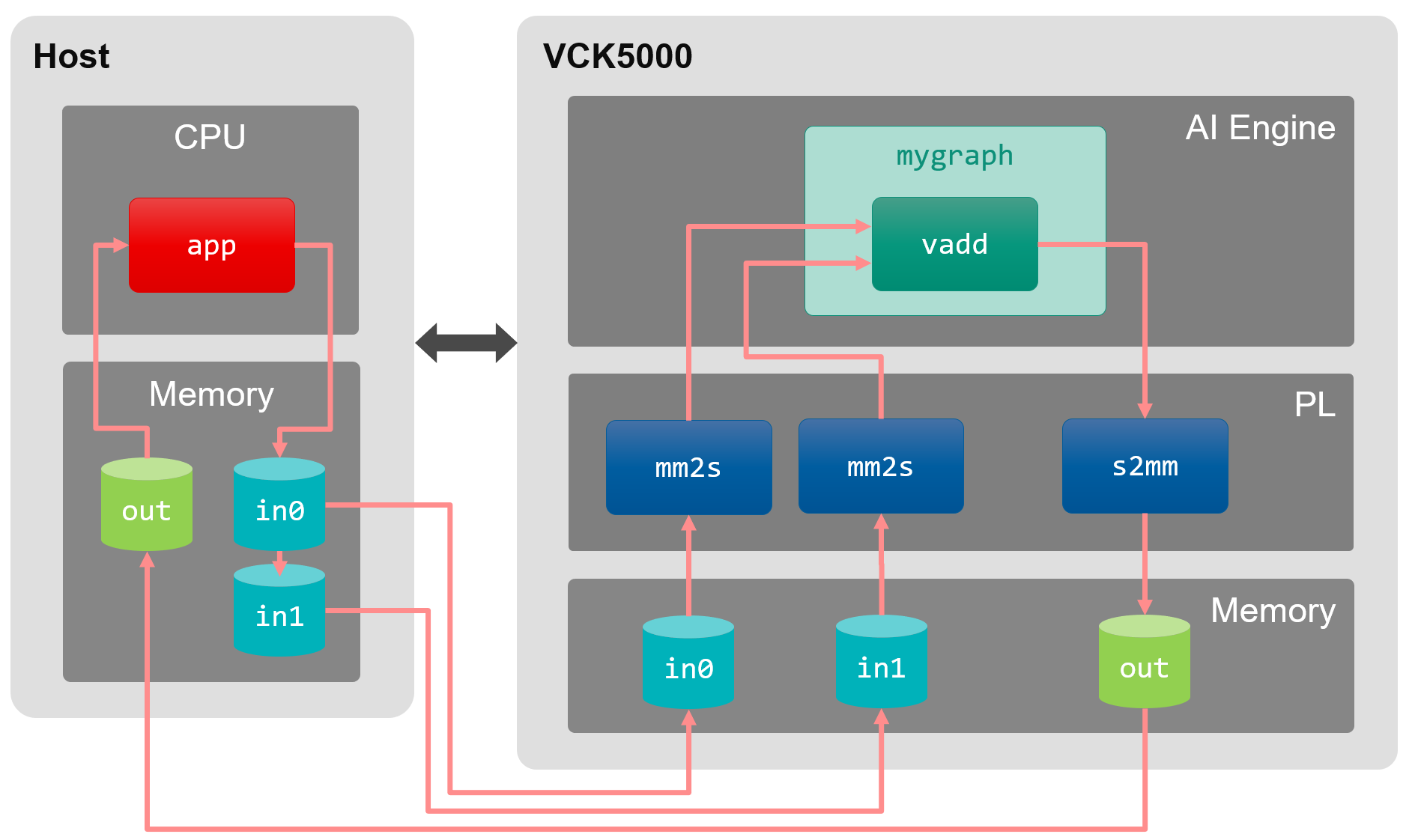
各構成要素とその役割は次の通りです。
- ホスト CPU で実行するプログラム (
app)- ホストメモリ、デバイスメモリにバッファ (
in0、in1、out) を確保 - 入力データを初期化
- ホストメモリとデバイスメモリ間のデータ転送
- PL カーネル起動
- ホストメモリ、デバイスメモリにバッファ (
- PL カーネル
mm2s: メモリからデータを読み出し、ストリームとして AIE へデータを転送s2mm: AIE からストリームを受け取り、メモリへデータを書き出し
- AIE カーネル (
vadd)、AIE グラフ (mygraph)- ストリームからベクトルを受け取り、加算、結果をストリームに送信
7.3 AIE カーネルの作成
AIE カーネルは C++ で AI Engine API を使用して記述します。AIE カーネルのコーディングでは、入出力データはストリームまたはウィンドウで受け取り、どちらを使用するかを関数の引数として明示的に記述します。また、計算にベクトル演算器を使用するために専用の API を利用します。
ここで計算対象のふたつのベクトルを入力ストリームから読み込み、ベクトルユニットで足し合わせて、出力ストリームに書き出すプログラムを作成します。
// (1) 必要なヘッダーファイルをインクルード
#include <aie_api/aie.hpp>
#include <aie_api/aie_adf.hpp>
#include <aie_api/utils.hpp>
// (1) AIEカーネルの定義
void vadd(
// (2) 入出力ストリーム
input_stream<int32>* in0,
input_stream<int32>* in1,
output_stream<int32>* out
) {
// (3) 入力ストリームからのデータをint32の4要素ベクトルとしてベクトルレジスタへ格納します
aie::vector<int32, 4> a = readincr_v<4>(in0);
aie::vector<int32, 4> b = readincr_v<4>(in1);
// (4) ベクトルレジスタに読み込んだふたつのベクトルを足し合わせます
// 結果はベクトルレジスタに格納されます
aie::vector<int32, 4> c = aie::add(a, b);
// (5) ベクトルレジスタ上の計算結果を出力ストリームに書き込みます
writeincr(out, c);
}(1) AIE カーネルのコーディングに必要なヘッダーファイルをインクルードします。
(2) AIE カーネルの入出力をストリームとして定義します。
(3) では入力ストリームのポインタ input_stream<32>* から readincr_v<4> 関数を使って aie::vector<int32, 4> を取得しています。aie::vector<int32, 4> は名前の通り、int32 を4要素格納するベクトル型です。これにより入力ストリームからのデータがベクトルレジスタへ格納されます。
(4) では (3) でベクトルレジスタにロードしたふたつのベクトルを aie::add 関数を使って足し合わせ、結果をベクトルレジスタに格納します。
(5) ではベクトルレジスタの値 (計算結果) を出力ストリームのポインタ output_stream<32>* に出力しています。
このように AIE カーネルのプログラミングでは、カーネルへデータを出し入れする手段を明示的に記述します。また、ベクトルユニットを利用するときには、ベクトルレジスタを介して演算するようにします。AI Engine API についての詳しい情報は AI Engine API User Guide をご参照ください。
AIE カーネル引数の構成を AIE グラフから参照できるよう、次のようにヘッダーファイルを作成します。
#pragma once
#include <adf.h>
void vadd(
input_stream<int32>* in0,
input_stream<int32>* in1,
output_stream<int32>* out
);7.4 AIE グラフの作成
AIE グラフの役割は、AIE カーネルをインスタンスし、AIE カーネル間の接続と、AIE グラフの外 (PL またはメモリ) との接続を定義することです。次の図のようなグラフを C++ コードで定義します。
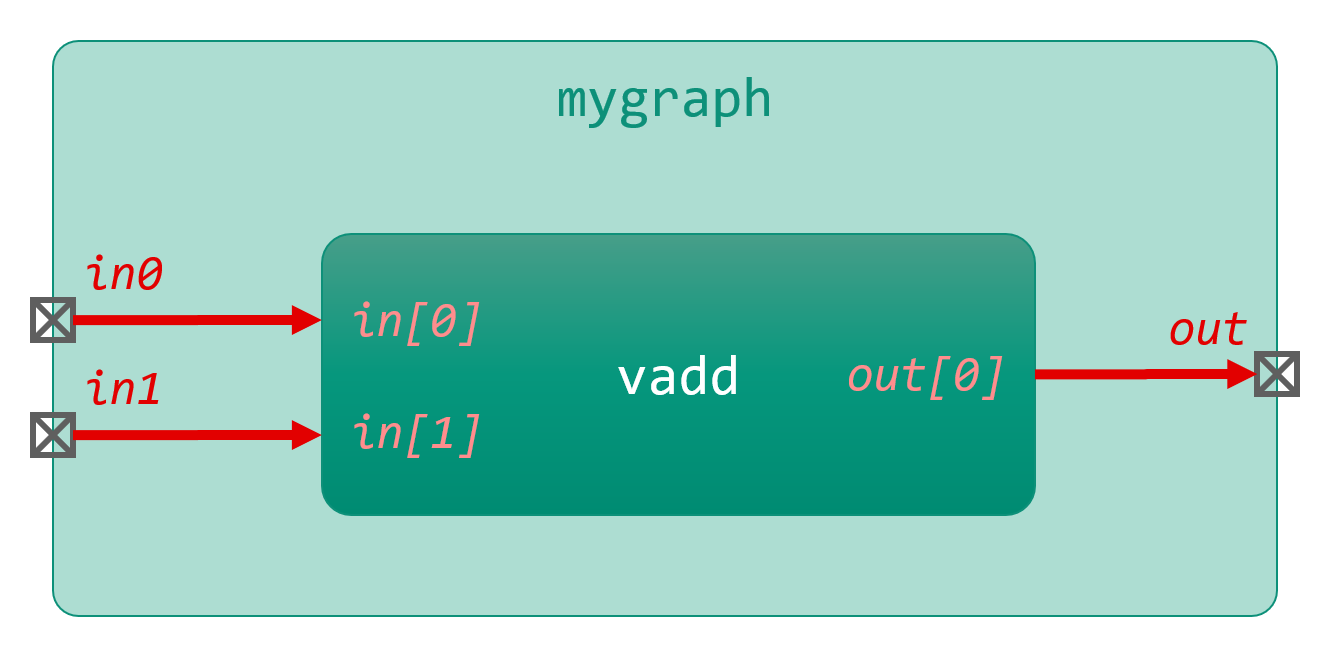
この AIE グラフのコードは次のように記述します。
#pragma once
// (1) 必要なヘッダーファイルをインクルード
#include <adf.h>
#include "vadd.hpp"
// (2) adf::graphを継承したクラスを作成し、この中でグラフを定義します
class mygraph : public adf::graph
{
private:
// (3) AIEカーネルインスタンス
adf::kernel vadd_kernel;
public:
// (4) PLとの入出力を定義
adf::input_plio in0, in1;
adf::output_plio out;
mygraph()
{
// (5) vaddカーネルを作成し、ソースファイルを指定します
vadd_kernel = adf::kernel::create(vadd);
adf::source(vadd_kernel) = "vadd.cpp";
// (6) PLとの入出力を作成します
// 第一引数はポートの名前を設定します
// 第二引数はポートのビット幅を設定します
// 第三引数はシミュレーションで使用する入出力データのファイル名を指定します
in0 = adf::input_plio::create("in0", adf::plio_32_bits, "input0.txt");
in1 = adf::input_plio::create("in1", adf::plio_32_bits, "input1.txt");
out = adf::output_plio::create("out", adf::plio_32_bits, "output.txt");
// (7) カーネルとPLIOをストリームで接続します
adf::connect<adf::stream>(in0.out[0], vadd_kernel.in[0]);
adf::connect<adf::stream>(in1.out[0], vadd_kernel.in[1]);
adf::connect<adf::stream>(vadd_kernel.out[0], out.in[0]);
// (8) カーネルのランタイム比を設定します
adf::runtime<adf::ratio>(vadd_kernel) = 1.0;
};
};(1) AIE グラフの定義に必要なヘッダーファイルをインクルードします。
(2) AIE グラフの記述は adf::graph を public 継承したクラス定義の中で行います。
(3) AIE グラフ内にインスタンスする AIE カーネルを定義します。ここでは入れ物だけ用意し、AIE カーネルの具体的な中身は後で指定します。複数の AIE カーネルをインスタンスする場合にはここで adf::kernel を複数定義しておきます。
(4) AIE グラフの外、この例では PL と接続する入出力ポートを定義します。
(5) adf::kenel::create 関数に AIE カーネル関数を渡すことで、adf::kernel インスタンスを作成します。adf::source 関数を使って、AIE カーネルのソースファイルを指定します。
(6) AIE グラフの外との入出力ポートを作成します。adf::input_plio::create、adf::output_plio::create 関数により PL と接続する入出力ポートを作成しています。1つ目の引数で入出力に名前を付けています。この名前は Vitis で PL カーネルと接続するときに使用します。2つ目の引数は、PLIO のビット幅を指定します。3つ目の引数はシミュレーション時にこのポートに流し込む、またはポートから出てくるデータを格納するファイル名を指定します。
(7) AIE グラフ内のデータ接続を定義します。adf::connect 関数に渡す引数で接続元と接続先のポートを指定します。このときテンプレート引数に adf::stream を渡すことで、これらのデータ接続をストリームとするよう指示しています。接続元と接続先のポートは、AIE カーネルや PLIO ポートの in、out を使って指示します。カーネルに複数のウィンドウまたはストリーム引数がある場合は、入力と出力ごとに順番にインデックスが振られます。in、out に対してインデックスを使用して配列アクセスして、具体的にどのカーネル引数に接続するか指定します。
(8) カーネルのランタイム比と呼ばれるパラメータを設定します。グラフ全体のスループット要件から考慮して各 AIE カーネルに許容される実行サイクル数のうち、この AIE カーネルが消費する割合を見積もって設定します。この設定はひとつの AI Engine に複数の AIE カーネルを柔軟に配置できるようにするための制約として使用されます。たとえば1000サイクルのバジェットがあり400サイクルの AIE カーネルがふたつあったとき、このふたつの AIE カーネルをひとつの AI Engine に配置し、順番に実行することで、スループットを満たしつつ AIE リソースを節約できます。
次に AIE グラフのシミュレーションを行うテストベンチを作成します。グラフを初期化して、グラフを一度だけ実行するテストベンチとしています。
#include "graph.hpp"
mygraph graph;
int main(int argc, char** argv)
{
graph.init();
graph.run(1);
graph.end();
}7.5 AIE カーネル/グラフのコンパイル、シミュレーション
ハードウェア (AIE) をターゲットとして AIE グラフをコンパイルします。--platformオプションに使用するカードのプラットフォームファイルを渡します。検証のために x86 上での高速なエミュレーションを利用することもできますがここでは省略します。
$ XPFM_FILE=/opt/xilinx/platforms/xilinx_vck5000_gen4x8_qdma_2_202220_1/xilinx_vck5000_gen4x8_qdma_2_202220_1.xpfm
$ aiecompiler --target=hw --platform=$XPFM_FILE --include=src src/graph.cppAIE グラフのコンパイルに成功すると Work ディレクトリと libadf.a が作成されます。
次に AIE グラフ単体でシミュレーションを実行します。入力ポートの作成時に指定したファイル (data/input0.txt と data/input1.txt) に入力データを用意します。
2
3
4
50
1
4
9シミュレーションを実行します。このとき、コンパイル時に作成された Work ディレクトリの場所と、入力データを用意したディレクトリを引数で渡します。--profile オプションを指定することで、シミュレーション実行時にプロファイル情報を取得できます。
$ aiesimulator --pkg-dir=Work --input-dir=data --profileシミュレーションを実行すると、出力ポートで指定したファイル (aiesimulator_output/output.txt) に出力データの値と時刻が保存されます。
T 660 ns
2
T 664 ns
4
T 668 ns
8
T 672 ns
14シミュレーションによるプロファイルの結果は Vitis Analyzer で確認できます。AIE グラフ単体で性能が目標に達しているかをここで確認します。
$ vitis_analyzer aiesimulator_output/default.aierun_summary7.6 PL カーネルの作成
メモリと AIE との間でデータ移動を行う PL カーネルを C++ で作成します。
mm2s カーネルは、第三引数で指定された数だけポインタを介してメモリからデータを読み出し、AXI ストリームに書き込みます。
#include <ap_int.h>
#include <ap_axi_sdata.h>
#include <hls_stream.h>
extern "C" {
void mm2s(
ap_int<32>* mem,
hls::stream<ap_axis<32, 0, 0, 0>>& str,
int size
) {
for (int i = 0; i < size; i++)
{
ap_axis<32, 0, 0, 0> x;
x.data = mem[i];
x.keep = -1; // バイトイネーブルのフラグをすべて立てる
str.write(x);
}
}
}ap_int<32> は HLS で符号付き 32bit 整数を表す型です。
hls::stream<ap_axis<32, 0, 0, 0>> は他のカーネルとストリーミングインターフェースでデータを直接送受信する AXI4 ストリームを表す型です。ap_axis<32, 0, 0, 0> は送受信するデータが符号付き 32bit 整数であることを示します。符号なし整数やビット列を送受信する場合は ap_axis の代わりに ap_axiu を使用します。詳しくは UG1399: AXI4-Stream インターフェイス をご参照ください。
関数内では mem ポインタを介してメモリから 32bit のデータを読み出し、str ストリームへ書き込むハードウェアを記述しています。HLS により for ループはパイプラインとなり、メモリへのバーストアクセスが推論されます。HLS により効率の良いハードウェアが自動で合成されます。
s2mm カーネルは mm2s カーネルの逆を行います。
#include <ap_int.h>
#include <ap_axi_sdata.h>
#include <hls_stream.h>
extern "C" {
void s2mm(
ap_int<32>* mem,
hls::stream<ap_axis<32, 0, 0, 0>>& str,
int size
) {
for (int i = 0; i < size; i++)
{
auto x = str.read();
mem[i] = x.data;
}
}
}ここではこれらの PL カーネルの検証の話は省略します。
これらのコードを Vitis を使って Xilinx Object にコンパイルします。このとき HLS により C++ コードがハードウェアに変換されます。次に mm2s カーネルを実機向けにコンパイルする場合のコマンドを示します。
$ v++ \
--compile \
--target hw \
--platform $XPFM_FILE \
--kernel mm2s \
-Isrc \
src/mm2s.cpp \
-o mm2s.xoこのコマンドを実行すると mm2s.xo が生成されます。s2mm カーネルも同様にコンパイルします。
7.7 ハードウェアリンク
AIE グラフと PL カーネルができたら、デバイス側の部品がすべて揃いますので、プラットフォームとあわせてひとつのシステムとしてリンクします。AIE グラフの記述と同様に、PL 領域に PL カーネルをインスタンスし、各カーネルのストリームポート間の接続を指示します。今回のデザインでは次の図の構成となります。
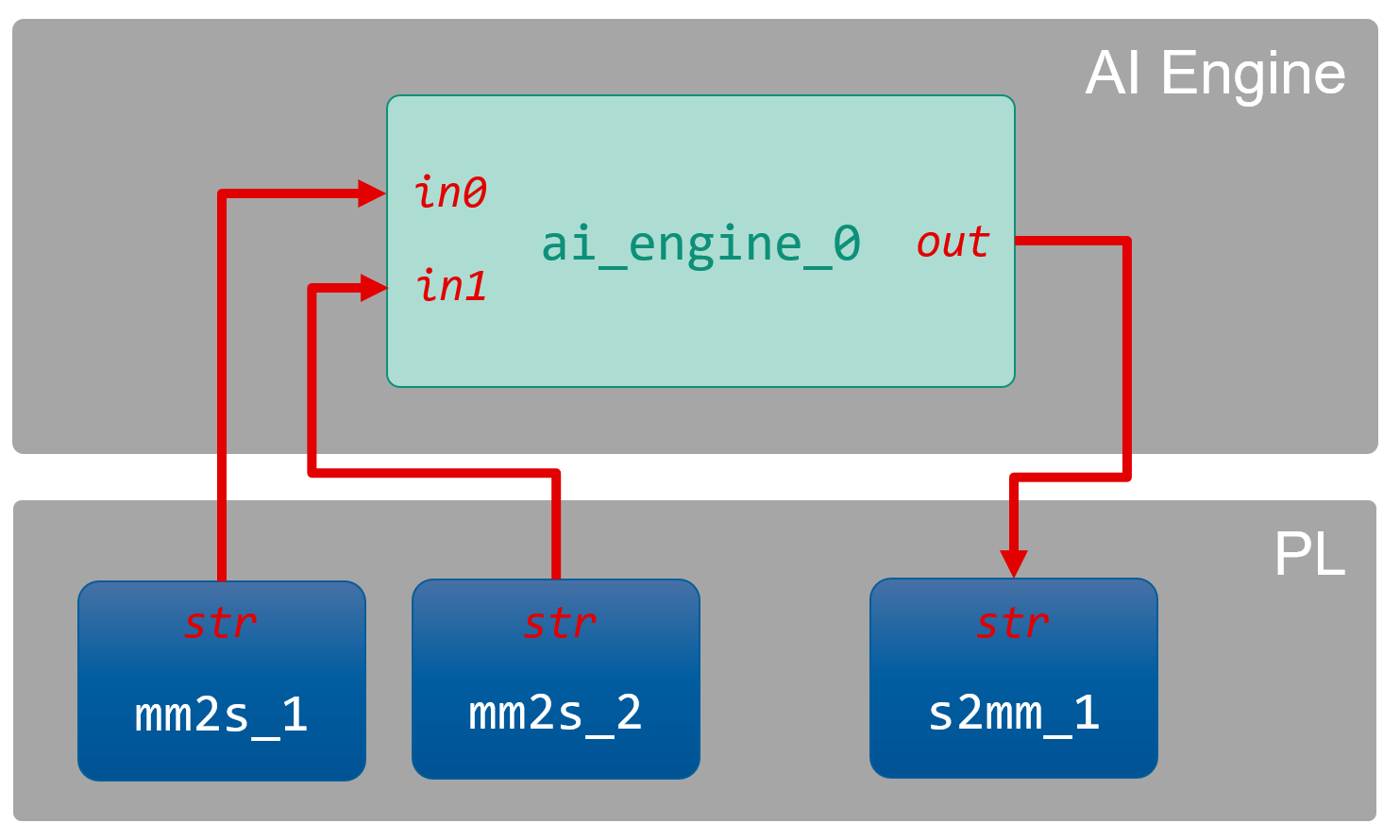
Vitis ではシステムの構成を設定ファイルとして記述します。設定ファイルの connectivity セクションに、インスタンスする PL カーネル名とその数を nk オプションで、カーネル間のストリーム接続を sc オプションで記述します。
mm2s カーネルは AIE カーネルの入力ポート数に合わせてふたつインスタンスしています。AIE グラフは ai_engine_0 で表され、AIE グラフ定義時に指定したポート名を使って接続します。
[connectivity]
nk=mm2s:2
nk=s2mm:1
sc=mm2s_1.str:ai_engine_0.in0
sc=mm2s_2.str:ai_engine_0.in1
sc=ai_engine_0.out:s2mm_1.strVitis の v++ コマンドを使い、PL カーネルをプラットフォームとリンクします。このとき AIE グラフの情報も必要となるため libadf.a も入力として渡します。
$ v++ \
--link \
--target hw \
--platform $XPFM_FILE \
--config ../src/system.cfg \
libadf.a \
mm2s.xo \
s2mm.xo \
-o link.xsaこのコマンドを実行すると、システム構成にしたがい Vitis が自動で Vivado プロジェクトを作成し、論理合成、配置配線を実行します。配置配線は組み合わせ最適化問題を解く重い計算です。この例では完了までおよそ50分かかりました。リンクした結果は link.xsa に保存されます。
7.8 パッケージ
ハードウェアリンクにより生成された xsa ファイルと AIE グラフをパッケージ化します。
$ v++ \
--package \
--target hw \
--platform $XPFM_FILE \
--package.boot_mode=ospi \
link.xsa \
libadf.a \
-o vadd.xclbinvadd.xclbin がデバイス側の最終的なビルド結果として出力されます。このファイルはホストプログラムの実行時に使用します。
7.9 ホストプログラムの作成と実行
XRT Native API を使ってホストプログラムを C++ で記述します。
#include <iostream>
#include <xrt/xrt_bo.h>
#include <xrt/xrt_device.h>
#include <xrt/xrt_kernel.h>
int main(int argc, char** argv)
{
const int device_index = 0;
const std::string xclbin_file = argv[1];
std::cout << "(1) デバイスを開く" << std::endl;
auto device = xrt::device(device_index);
std::cout << "(2) xclbinをデバイスにプログラムする, " << xclbin_file << std::endl;
auto uuid = device.load_xclbin(xclbin_file);
std::cout << "(3) カーネルを作成する" << std::endl;
auto mm2s_1 = xrt::kernel(device, uuid, "mm2s:{mm2s_1}");
auto mm2s_2 = xrt::kernel(device, uuid, "mm2s:{mm2s_2}");
auto s2mm_1 = xrt::kernel(device, uuid, "s2mm:{s2mm_1}");
std::cout << "(4) バッファオブジェクトを作成する" << std::endl;
auto bo_1 = xrt::bo(device, sizeof(int) * 4, mm2s_1.group_id(0)); // in0
auto bo_2 = xrt::bo(device, sizeof(int) * 4, mm2s_2.group_id(0)); // in1
auto bo_3 = xrt::bo(device, sizeof(int) * 4, s2mm_1.group_id(0)); // out
std::cout << "(5) ホスト側のバッファポインタをユーザー空間にマップする" << std::endl;
auto buf_1 = bo_1.map<int*>();
auto buf_2 = bo_2.map<int*>();
auto buf_3 = bo_3.map<int*>();
for (int i = 0; i < 4; i++) {
buf_1[i] = i + 2;
buf_2[i] = i * i;
}
std::cout << "(6) ホストからデバイスへバッファの内容を同期する" << std::endl;
bo_1.sync(XCL_BO_SYNC_BO_TO_DEVICE);
bo_2.sync(XCL_BO_SYNC_BO_TO_DEVICE);
std::cout << "(7) カーネルを起動する" << std::endl;
auto mm2s_1_run = mm2s_1(bo_1, nullptr, 4);
auto mm2s_2_run = mm2s_2(bo_2, nullptr, 4);
auto s2mm_1_run = s2mm_1(bo_3, nullptr, 4);
std::cout << "(8) カーネルの完了を待つ" << std::endl;
mm2s_1_run.wait();
mm2s_2_run.wait();
s2mm_1_run.wait();
std::cout << "(9) デバイスからホストへバッファの内容を同期する" << std::endl;
bo_3.sync(XCL_BO_SYNC_BO_FROM_DEVICE);
std::cout << "(10) 計算結果を出力する" << std::endl;
for (int i = 0; i < 4; i++) {
std::cout << buf_3[i] << std::endl;
}
}ホストプログラムの解説はコード中のコメントをご参照ください。
バッファオブジェクトは少し分かりにくい概念かと思います。この例のようにバッファオブジェクトを作成すると、ホスト側とデバイス側の両方にバッファ領域が確保されます。ホスト側のバッファはカーネル空間に確保されており xrt::bo::map 関数でポインタを取得してホストプログラムから直接操作します (バッファオブジェクトにユーザー空間で確保したメモリを使う方法もあります)。ホストとデバイスの間のバッファ間データ転送は xrt::bo::sync 関数を使って移動の方向を指定して行います。
カーネルの実行はホストプログラムとは非同期で行われます。s2mm カーネルが確実に完了してから結果を読み出すために xrt::kernel::wait 関数を使用してカーネルの完了を待ちます。
AIE グラフは自動で起動するためホストプログラムでは特に制御する必要はありません。
ホストプログラムをビルドします。
$ g++ \
-o app \
src/app.cpp \
-I/opt/xilinx/xrt/include \
-L/opt/xilinx/xrt/lib \
-lxrt_core \
-lxrt_coreutilホストプログラムに xclbin ファイルを引数として渡して実行します。AI Engine で計算された結果が表示されます。
$ ./app vadd.xclbin
(途中のログは省略)
2
4
8
14期待通りに出力されれば成功です。本チュートリアルはここまでとなります。
8. まとめ
本記事では AI Engine の概要と開発フローをご紹介し、具体的なコードを見ながら開発の手順を詳しく解説しました。短い簡単なコードを使ってひとつひとつ解説していくことで AI Engine のプログラミングの雰囲気を感じていただけたかと思います。チュートリアルを簡単に試せる Jupyter ノートブックを用意していますので、ACRi ルームで実際に動かして体験してみていただけるとうれしいです。
AI Engine は AMD (ザイリンクス) にとって新しいプロセッサです。開発環境やプラットフォームは発展途上にあり、現在も活発に改善が続けられています。チュートリアルでは Vitis 2022.1 時点での開発フロー、プラットフォームを対象に解説しました。
AI Engine 自身も発展を続けています。本記事でご紹介した AI Engine よりもさらに機械学習に最適化された次世代の AI Engine-ML が発表されています。AI Engine-ML のベクトルユニットはデータ型として新しく INT4、BFLOAT16 をサポートし MAC 性能を高めています。また AIE コアから高速にアクセスできるデータメモリの容量が強化され、大容量のオンチップメモリも追加されます。今後ますます応用が広がることが期待されます。
ザイリンクス株式会社 (AMD-Xilinx) 安藤潤