目次
3.C ベース設計と開発フロー
3-1.HW/SW アクセラレータの先行開発
■ HLS カーネルでアーキテクチャ検討
■ RTL カーネルで実用の詳細設計
3-2.手戻りを速く回す C ベース設計手法
■ 全体から部分へ (タスク分割)
■ 部分から全体へ (カーネル開発)
Coffee Break.ヘテロデバイス時代の就活
参考情報
あとがき
3章 Cベース設計と開発フロー
Xilinx の黒田です。最終章となる本章では、これまでの理解を踏まえ、高位合成 (HLS、Vitis) と Alveo を使い、ビジネスとして成立するレベルのアクセラレータを短期間で開発するために、開発フロー全体の中に C ベース設計をどう位置付ければいいのか、考えていきます。
3-1. HW/SW アクセラレータの先行開発
カーネル/アーキの記述が HLS-C だけで済めばそれが最短コースでベストですが、実用向けに価値を訴求できるほどの性能と実装品質の両方を極限まで追求した結果として、あるいは別の理由も含め、一部は HLS-C では表現できない方式のアーキやカーネル構成を採用せざるを得ない状況に (データセンターでは特に) なってしまいます。
その場合、実用向けのカーネル記述の形態としては、全てを HLS-C で記述する「HLS カーネル」ではなく、全て人手による RTL あるいは HLS とのミックスなのか、いずれにしても「RTL カーネル」(1-1節および本節後半) になります。
そのことを踏まえ、以降は、
“売り物になるアクセラレータを目指す場合には、むしろ RTL カーネルのほうが普通”
という認識を前提にした上で、それに向かっての開発を考え、組み立てていきます。
はじめに、実用化を目指すアクセラレータの開発全体を、次のように大きく2つの段階に分けて考えます。
工程1. アーキテクチャの検討
工程2. 実用向けの詳細設計
工程1) ではまず、サーバー CPU 上で動作している計算アルゴを FPGA/Alveo にオフロードしてアクセラレータ化する意義があるかどうか、最初の見極めを行うところから始めます。
この見極めによってアクセラレータ化の判断はできても、最終的に売り物になる内容までもっていけるかどうかまでは、この段階では分かりません (2章の Coffee Break まで含む後半の話)。それは、工程1で検討した結果の理解を元に、実用向けのターゲットを選定した上で初めて判断できます。
見極めに当たっては、サーバー CPU 上で動作する計算アルゴのプロファイルの採取から始め、機能レファレンスのコードを解析し、アクセラレーション対象と想定する部分についてタスク分割を実施します (2-1節)。
その上で、カーネルに与えられる帯域を使い切れるほどに十分な並列性を実現する “土管の” アーキをタスク内とタスク間において見出せるか、検討します (2-1節)。
そのようにして描いた叩き台のアーキを元にハードウェア化の判断をし、実用向けのターゲットとする Alveo の候補を立て、選定します。
選定した Alveo を対象として、工程2) で実用向けの詳細設計をフィックスさせます。
上で述べているのは、それぞれの工程の大枠と成果物だけです。工程1~2) まで全て机上で検討し、実用向けの RTL カーネルを一気に一回で書く、という訳ではありません。
原理的には可能だとしてでも、実用を目指す開発としては生産性が低過ぎて、現実的ではありません。
ターゲットの選定と言っても何となく行う訳にはいかないので、実際は叩き台のアーキを HDL (1-1節) で記述までして論理合成を行い、得られたデバイス使用率 (エリア) 情報を、案件毎に与えられた要求仕様 (制約) と照らし合わせた上でないと、正しい選定はできません。
その HDL も、エリアの見積りだけだからと言って内容は適当な記述でいいという訳にもいかないので、少なくともアクセラレータ化を決める根拠にした叩き台のアーキを元に、実際にカーネルを設計して用意する必要があります。
さらにその検証も、サーバー上で HW/SW ランタイムとして実行するカーネルに対するものなので、叩き台のカーネルであっても Alveo 挿しのサーバー上でアプリを実行し、システムレベルの検証まで行った結果でなければなりません。
そのように、ターゲットを選定するために、前に行われるべき開発のことを、工程1) のアーキテクチャ検討の手段として「HW/SW アクセラレータの先行開発」と呼びたいと思います。
“先行” とは、実用向けの詳細設計に先行する、という意味です。
先行開発には、実用向けの詳細設計の叩き台になるカーネル設計を含め、HW/SW アクセラレータのシステムレベル検証を行うための開発環境として、Alveo 挿しのサーバーが必要です (下図 TOP)。ですが、先行開発が終わるまでは (あるいは、ある程度進んでみないと)、実用向けの Alveo は決められません。なので、詳細設計のための開発環境としては、実用向けに選定した別の Alveo を挿したサーバーが必要 (下図 Bottom 右) になります。
同じサーバーにそれら2種類の Alveo を挿せるならベターかも知れません。
先行開発向けの Alveo として、実用向けの制約を気にせずアーキ検討 (ハードウェア化の見極めおよび叩き台のカーネル開発) に集中できるよう、デバイス容量やメモリ帯域が大きなもの (例えば、U250 or U280) が常設されていると良いと思います。オンプレで用意する余裕がなければクラウドの AWS F1 インスタンス (U200 相当) があります。
そう言えば、今なら ACRi ルームに色々揃っている Alveo にもアクセスできますね!
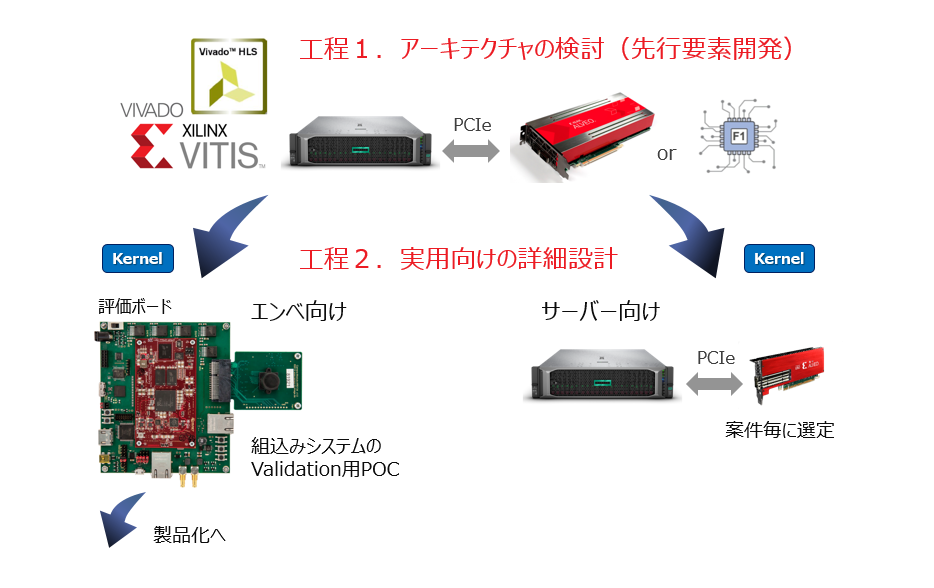
ところで、2章の前フリで断ったように本連載はサーバー向けのアクセラレーションの話にフォーカスをしていますが、上の先行開発環境はエンベデッド向けのアクセラレータ IP 開発にももちろん利用できます。
エンベデッド向けであればオフロード/アクセラレーション対象の CPU は組込み ARM になり、サーバーほどのシビアな要件は問われず HLS だけで十分だったり、その検証でも Alveo は必要なく HLS 上のシミュレーション (C-Sim、Co-Sim (1-2節)) だけで設計が済んでしまう場合も多いかも知れませんが、アプリケーションのレベルから IP 検証のスティミュラスを与えたい、Alveo を使って検証時間も短縮したい、といった場合もあるかも知れません。
一つ例を挙げると、MATLAB プログラムの一部をハードウェア化したいケースは有るかなと思います。
機能レファレンスとしての C/C++ は、MATLAB Coder を使ってエンベデッド FPGA 向けに高速化対象の M コードを M2C 変換して準備し、そこから HLS-C 化を検討します。
その検証のためのスティミュラスを MATLAB のアプリから与えたい場合には、Vivado HLS 上で実行するテストベンチに MATLAB を直接持ち込むことは出来ませんので、Alveo 向けのカーネルとしてアクセラレータを開発し、そのランタイム・プログラムを MATLAB コマンドとして使えるようプラグインするやり方になるかと思います (そのための仕組みが MathWorks 側で用意されています)。
エンベデッドの場合には POC の段階から (上図 Bottom 左) 実用化を見越したプラットフォームをカスタムで開発することになるのが普通なので、先行開発以降については、Xilinx が用意するプラットフォームを開発でも運用でも終始利用するサーバー向けとは違い、基本は IP を手動で繋ぐ、従来的な開発になります。
HLS カーネルでアーキテクチャ検討
前項で述べたアクセラレータ開発の2つの工程を、ここであらためて示します。
工程1. アーキテクチャの検討 (先行開発)
工程2. 実用向けの詳細設計
前項では、工程1) において、タスク分割に始まるアーキ検討から、最初の叩き台になるカーネル、さらに Alveo 上でアプリとして実行できる HW/SW アクセラレータまで、先行開発することの意味について、話をしました。
では、この先行開発をどのように進めるのがベストでしょうか?
先ほどは他に良い言い方が思いつかず、つい、”売り物になるアクセラレータを目指す場合には、むしろ RTL カーネルのほうが普通” です、といった (本連載のテーマを粉砕するかのような) コメントをしてしまいました。
では、先行開発で叩き台のカーネルから RTL で書き始めるでしょうか?
RTL で書くこと自体がそもそもイヤですが、本連載を貫く論点である設計生産性の観点でそれよりも問題なのは、まずは叩き台を目指すのであっても「タスク分割再検討 → アーキ改版 → カーネル改版」のイタレーションが一度で済まない可能性が高い中で (それ自体はとてもクリエイティブな行為だと筆者は考えますが) それを RTL でやらなきゃならないのが、何よりもイヤです (下図)。
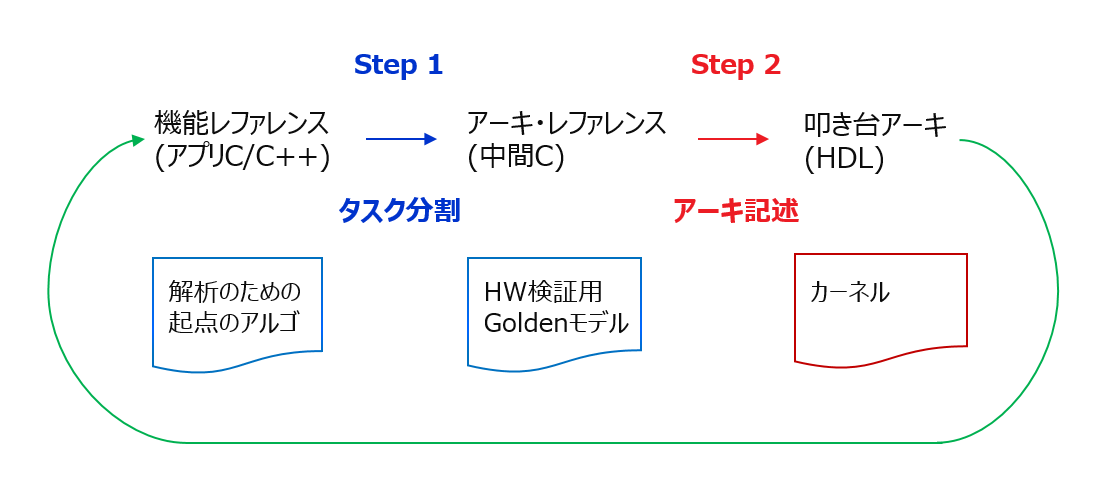
RTL 設計者でも (恐らく) このイタレーションを RTL で繰り返すのはイヤだと思います。アクセラレータの構成やカーネルの階層構造が複雑になりそうな場合はなおさら (というか、サーバー向けに売り物になるものは全てそう) です。
上の図 (左側) で示すように、アプリの計算アルゴから引っ張ってきたソースコードをアーキ検討のための解析の起点 (機能レファレンス) としますが、そのコードにはハードウェア化のための考慮など微塵も含まれません (元々 CPU 向けの “プログラム”)。
なので、繰り返しになりますが、2章 (2-1節) で述べたように、そのような素性のコードを FPGA 優位のデザインパターンの観点で解釈し直せるよう、タスクの概念を使って再構成します (この作業がタスク分割)。ハードウェア化の意義があると判断した場合、タスク分割の成果物を中間 C/C++ コードの形で残し、後でカーネル設計の Golden モデルとして利用できるようにします。これをアーキ・レファレンス (上図 (真中)) と呼ぶことにします。
元々素性の分からない機能レファレンスを起点とした背景があるため、アーキ・レファレンスを構成する複数のタスクあるいはサブ関数の組合せ (各サブ関数の内容や割り方を含めて) の在り方は、1通りではない可能性が高いです。
それで、初版のアーキ・レファレンスを元に意を決して RTL を書き始め、しばらくした後になって「あ、別の方式 思い付いちゃったよ」とか、途中で出てくるかも知れません。放置して進めても実用向けにも大勢に影響はないだろうと確信が持てるならいいですが、そうじゃないかも知れません。アクセラレータを構成する回路要素を一から十まで全て記述しないといけない RTL でそういった手戻りは本当にイヤです。
この非効率を解消するための手法として、実用向けには RTL カーネルであることが分かっていても、アクセラレータの先行開発を通して検討するアーキテクチャを、まずは HLS カーネルとして記述することを考えます。
ハードウェア化対象のアーキ・レファレンスであれば、各サブ関数は土管データパスを持つサブ・モジュールに対応することが担保されており、HLS-C 記述で置き換えられるはずです。
恐らく最終的に期待される性能の満額ではないにしても、これで少なくとも、実用化に向けた叩き台として、HLS-C で記述できる範囲内で最良の HLS カーネルを目指し、「タスク分割再検討 → アーキ改版 → カーネル改版 → HW/SW アクセラレータ検証」のイタレーションを C ベースで素早く回せるようになります (下図)。
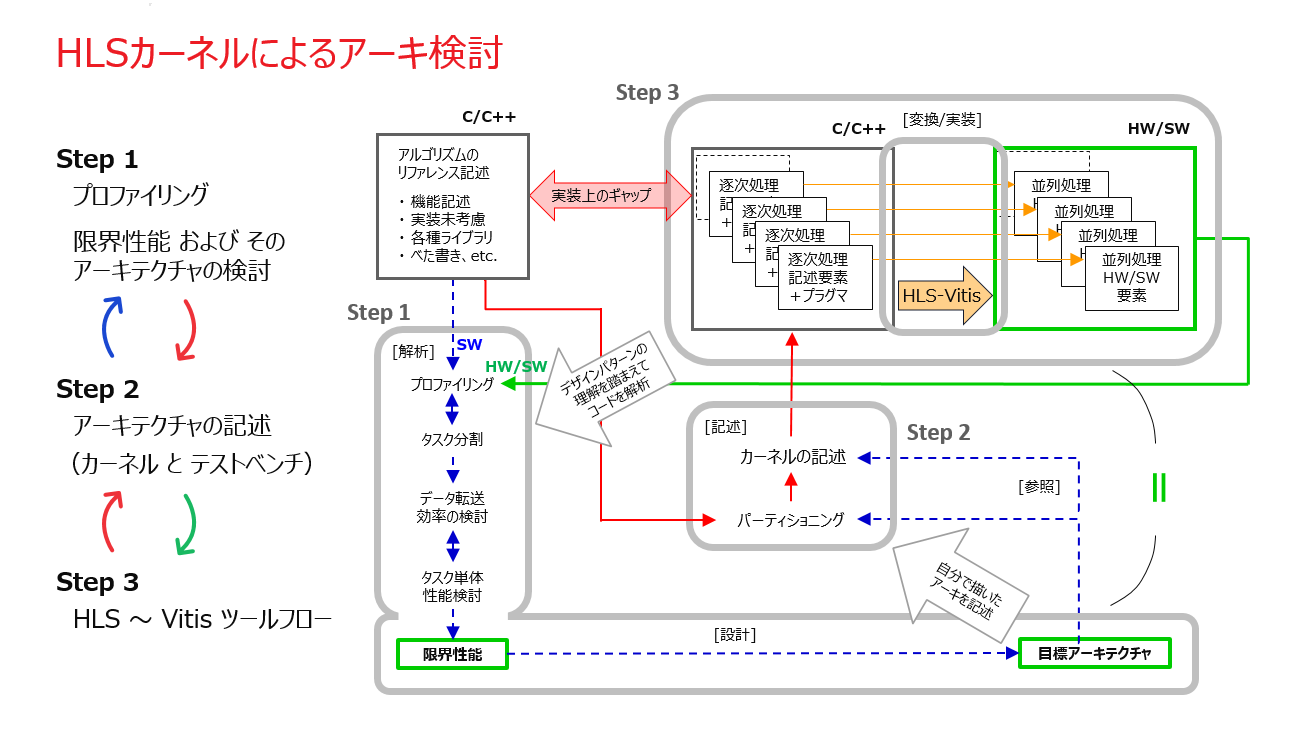
HLS カーネルによる先行開発の作業を通して、実用の RTL カーネルへの詰めの詳細設計に向けた準備として、いろいろな成果物や考慮事項が得られます。
- アプリにプラグインして動作させた実績を持つ Runtime プログラム
- カーネル単体についてデータ転送との SW パイプライン動作
- カーネル複製の実装に対してアプリのマルチプロセス実行
- HLS カーネルを使って各種 Alveo 向けに使用率の見積りが可能
- タイミング収束性の分析 (HLS カーネルはシングル・クロック実装)
- 性能測定とプロファイル分析結果 (SW オーバーヘッド、メモリ効率)
- HLS-C では表現できない別の方式のアーキテクチャの候補、etc.
先行開発で得られた情報に、案件毎の制約情報 (目標のコスパ = 性能と実装品質の両立/価格) を照らし合わせ、詳細設計と実装方針を検討した上で、実用向けの Alveo を選定します。
RTL カーネルで実用の詳細設計
売れるカーネルを目指して目標の指標を越えるよう、HLS カーネルでは表現できなかった/行わなかった内容を RTL カーネルへ反映させるべく、詳細設計 (工程2) を行います。例えば、以下のような内容が考えられます。
- HLS-C では表現できない内容
(1) 土管 (レイテンシ) を短くする別の方式
(2) カーネル内部のマルチクロック化 - 既存の RTL 資産の流用
ここでは特に1-(2)に触れておきます。実用向けの実装では高性能なカーネルを出来るだけたくさん詰め込みたいものです。使用率と性能をギリギリで両立させたいときに、必要に応じて以下の図で示すような検討を行います。
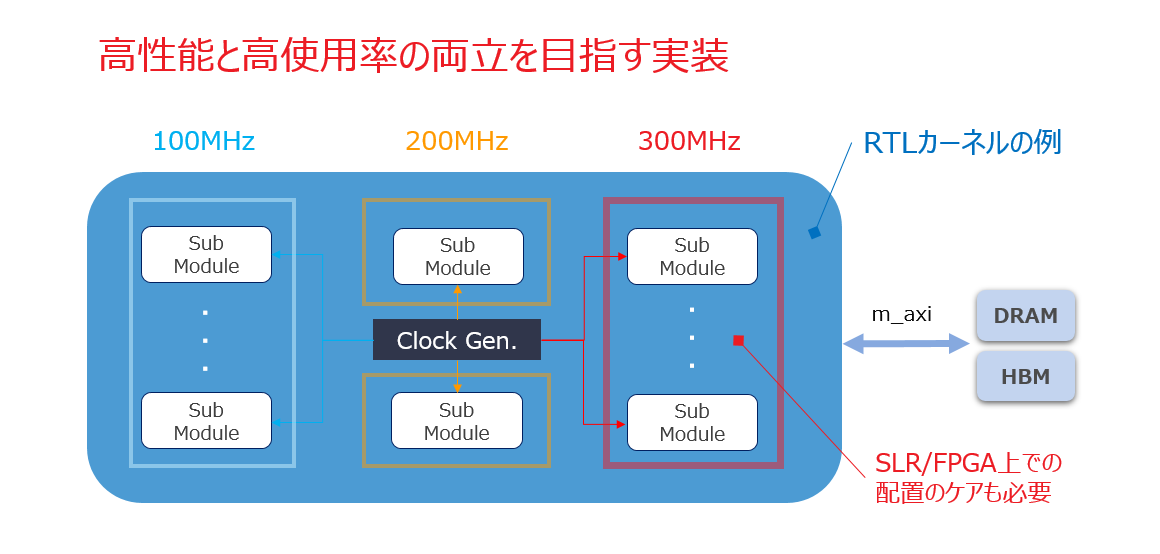
アプリのマルチプロセス等の対応で高性能カーネルを複製してギチギチに詰め込みたい状況では、当然使用率が上がってタイミング収束性の難易度が増します (2-2節)。例えば上図だと、HLS カーネルの先行開発を通して 300MHz 一律の制約ではタイミング収束しないことと理由が分かっているとして、仕様に影響しない範囲の対策として RTL カーネルへの詳細設計ではマルチ・クロック化を検討し、高い使用率と性能の両立を目指します。
HLS カーネルはシングル・クロックのみ対応のため、RTL カーネルにクロック生成 IP (MMCM) をインスタンスして実装します。RTL カーネル内で HLS 生成モジュールを流用する場合には、モジュール間を手で繋ぎます。例えば、HLS カーネルにデータフロー (2-1節) が存在した場合には、シングル・クロックのシンプルな FIFO で実装されていたストリーム・チャネルの代わりに、RTL カーネルでは上記1-(2)の対策によって異なるクロックのモジュール間を AXI Stream で繋ぎなおします。
その RTL カーネルですが、全てをスクラッチで作成するのではなく、RTL カーネル TOP のラッパーを生成してくれる Vitis 付属のユーティリティ機能 (RTL Kernel Wizard) があるので、利用しない手はありません。
詳しくは、UG1393「第8章:RTL カーネル」を参照ください
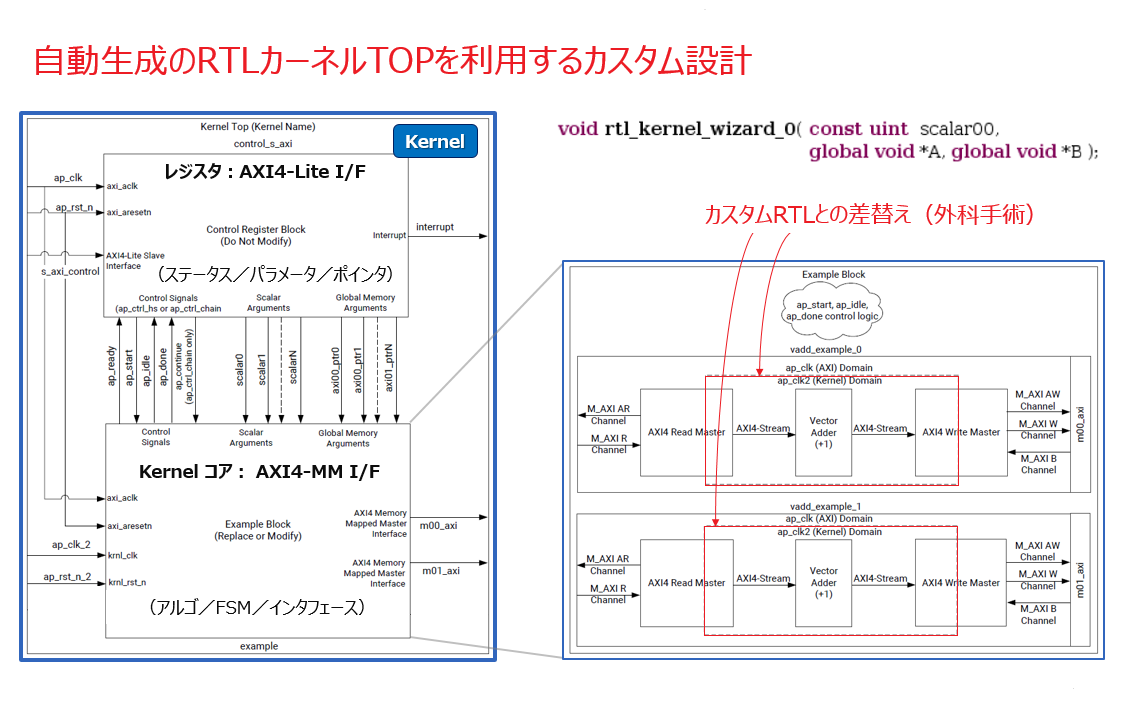
RTL カーネルのインタフェースは、カーネル制御の Runtime API 側で想定しているカーネル TOP 関数の引数とデータアクセス先の内容が対応付くように指定します。上の例では、デバイス・メモリ (ポインタ引数) にアクセスするために m_axi インタフェースの TOP が生成されています。ポインタ引数毎に AXI バスを独立してもたせるのか、複数のポインタを束ねてバスを共有するのか等、Wizard で選べます。m_axi なので、中に AXI Read/Write マスター部を含んでいます。アルゴのコアとしてダミーのモジュールが仮に生成されるので、それを上述したような実装対策が施されたオリジナルと差替え、 AXI マスター部を修正してそれと繋ぐ作業を行うことになります。
アクセラレータ開発に興味を持たれた学生の皆さんの中で、在学中に RTL カーネルにまで手を伸ばされる方は少ないかも知れないですね。RTL でないと記述できないアーキが研究テーマにでもならない限りは、就職先の実務で積み上げるで良いのかなと思います (筆者の勝手な想像と私見です)。
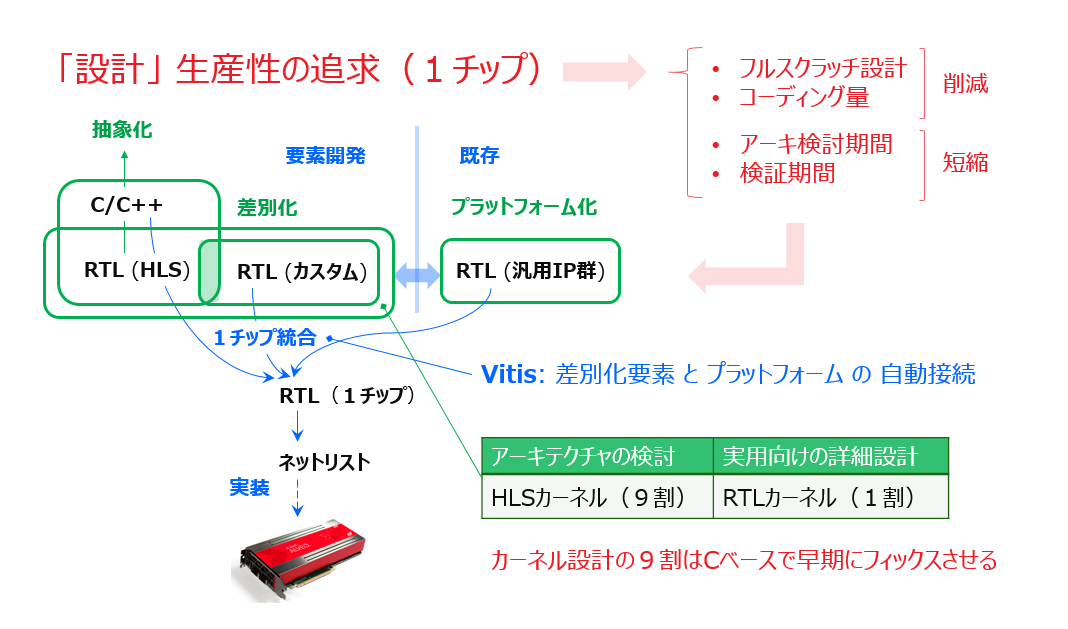
「高位合成 (HLS、Vitis) と アクセラレータ・カード (Alveo) を使い、ビジネスとして成立するレベルの高性能 HW/SW アクセラレータあるいはカーネルを、短期間で開発するためには何が必要か?」
高位合成 (HLS) をテーマとして、1章の最初にこの論点を掲げました。1-2節で HLS の原理を理解した上で、HLS-C で全てを記述できる訳ではないとして、1章の最後でその答えの方向性 (というか答えそのもの) を問いかけの形で大まかに示していましたが、2章で得た理解も踏まえ、本節でその答えに明確な表現を与えたことになります。
つまり、「HLS カーネルによる HW/SW アクセラレータの先行開発を通して、ハードウェア化の見極めからアーキテクチャまで早期にフィックスさせ、実用向けの詳細設計に必要な詰めの情報も先行開発の過程で採取することで、RTL 設計の必要性を最小限に抑える (特に、アーキ変更に伴うレベルの大きな手戻りを RTL では行わない) 」ということです。
感覚的には、HW/SW アクセラレータの目標の仕上がりの9割までは HLS カーネルで素早く持っていくようなイメージです。
3-2. 手戻りを速く回す C ベース設計手法
設計においては、「良い (必要な) 手戻り」と、「悪い (無駄な) 手戻り」があります。
- 良い手戻りは、最適解を探索するために全体と部分の間で往還を繰り返す際の手戻りです。
- 悪い手戻りは、一度定めた最適解を実装するために部分を積み上げていく際の手戻りです。
前者は創造のために必要な、試行錯誤も含むイタレーションのプロセスです。アクセラレーション開発でいうと最適なアーキテクチャを見極めるための行為になります。なんですが、それを RTL ではなく、Cベースの HLS カーネルで進めることでその大きなイタレーションのサイクルを高速化しましょう、という提案が3-1節の話でした。というかそれこそが、高位合成をテーマに本連載で追及し続けた設計生産性の問題意識に対する答えです。
後者は、その一つのイタレーション・プロセスにおいて、仮にでも一度決めた仕様を実装するために、石橋を叩いて渡るような手順を守るか守らないかという話です。ここでは主に、設計ツール (HLS と Vitis) を使った作業フローにおける手順の話になります。
本節では、C ベース設計を生かす視点をもって、HLS カーネルによるアクセラレータ先行開発を通してアーキテクチャを固めていく進め方について、より具体的に見ていきます。
全体から部分へ (タスク分割)
サーバー CPU 上で動作する計算アルゴの中で、Alveo にオフロードして高性能化したいルーチンの部分をアクセラレータとして実装する訳ですが、その実装対象の成り立ちをまず外枠から眺めます。次の図の赤い枠で囲んだ部分になります。
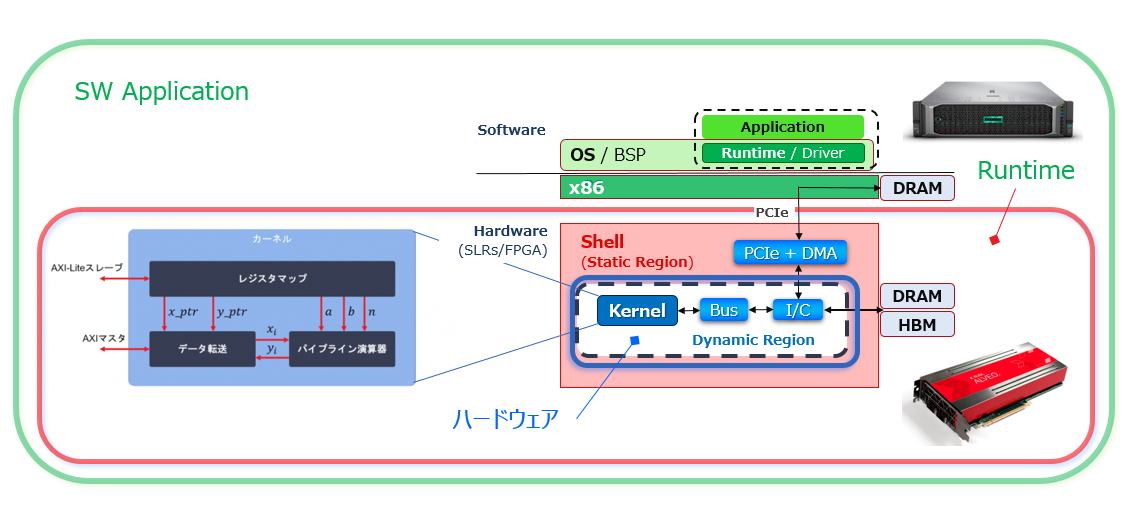
カーネルとプラットフォームの関係については、1章の中で「Vitis はカーネルをプラットフォームに繋ぐ」という以外に具体的な事は何も言っていなかったと思います。以降の話の理解のためにここで簡単に触れておきます。
Vitis がサポートする HW プラットフォームのことを Shell と呼び (上図 (右側) で赤い網掛け部分)、カーネルが PCIe 経由でホスト側から制御を受けたり、アクセスするデータをホストとデバイス側でやり取り (Mem Copy) する DMA を含む足回り (データ・ムーバー系) を担います。
Shell は実装済みで用意されており、Alveo をインストールする際にコンフィギュレーションしてしまいます。その意味で、FPGA 上の Shell 領域のことを “Static Region” とも呼びます。
カーネルを Shell に繋ぐために必要になる、制御を含む AXI バスやメモリ・コントローラといったデータ・ムーバー部品は、Vitis がカーネルのインタフェースとそれに紐づけられたアクセス先を見て内容を判断して生成し、カーネルと一緒に実装します。
その部分のビットストリーム・データは、アプリケーションを実行する際にランタイム API を介してパーシャル・リコンフィギュレーション機能で流し込む形です。その意味で、FPGA 上のその領域のことを “Dynamic Region” と呼びます。
アクセラレータを実装できた後は、元々は CPU が処理していたデータを、今度はカーネルが処理してアプリとやり取りが出来るよう、Runtime プログラムで DMA とカーネルをホストから制御することになります。
カーネル TOP 内/インタフェースはそれを可能にするために決め打ちの構成/内容になっています (1-2節)。
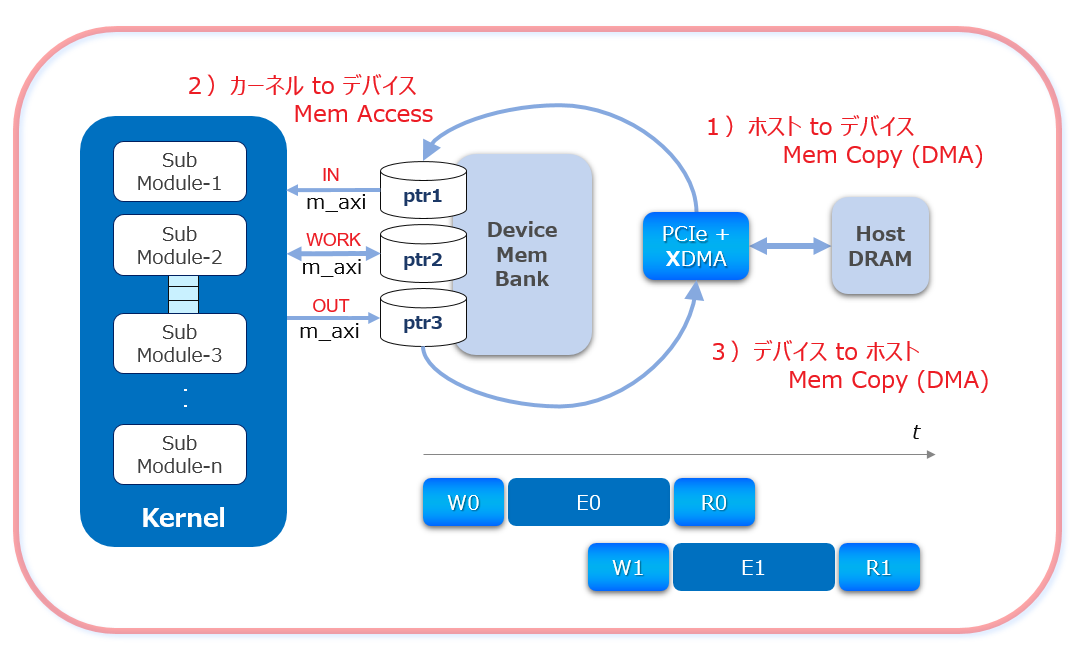
カーネルが処理するデータには、基本はホストからデバイス・メモリに Mem Copy した上でアクセスする前提で考えると、DMA とカーネルを制御するための Runtime プログラムはただの起動と終了だけのそれではなく、上図で示すようにカーネルが常時稼働するように DMA との間で SW パイプライン動作のための制御も含むよう考慮が必要です。
Xilinx からの第1期ブログ連載に分かり易い図解がありますので、こちらも参考にしてください。

オフロード先のアクセラレータ (Runtime プログラムの対象) についてイメージが持てたところで、ここからカーネル開発の話に移ります。
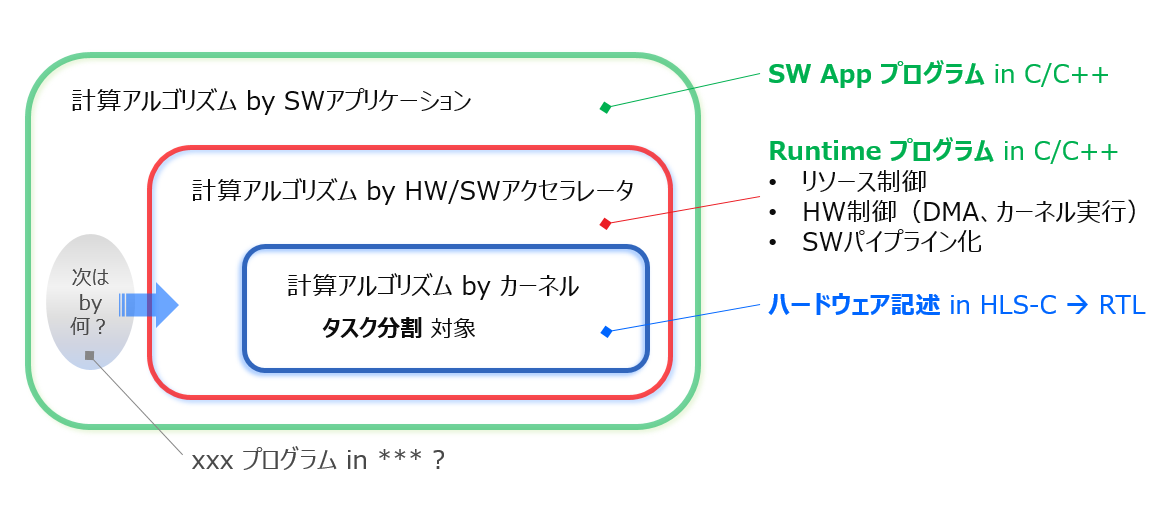
上図の赤い囲みは先ほどの話と同じ意味合いで示しています。高性能化のために切り出したルーチンと元のアルゴとの境界ですが、アクセラレータ実装後は Runtime プログラムとの境界になります。
図の左側で赤枠の外に示すイラストですが、将来は FPGA 以外にヘテロの別要素が加わってくる可能性を匂わす意味合いで載せています。
その切り出したルーチンのコードは、それと等価な機能を持つ高性能ハードウェアであるカーネルを設計するための機能レファレンスとして利用します。
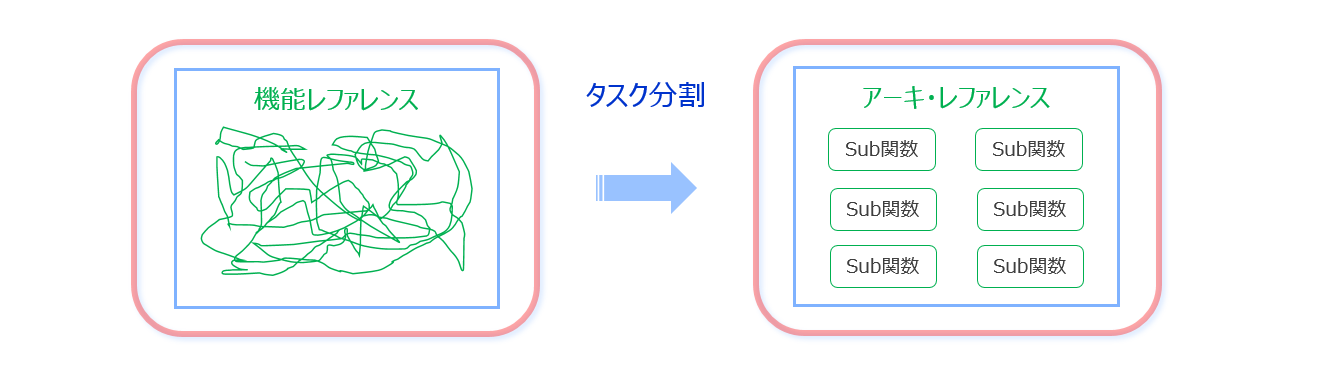
機能レファレンスはハードウェア化の事など考慮されていない素性のコードになるので、それを眺めながらいきなりカーネルの設計を始めることは出来ません。
上の図で機能レファレンス・コードの様子がグチャグチャに見えるのは、文字通りそうなのではなく、ハードウェア化のために事前には素性が分からない、という意味合いを強調したかっただけで、他意はありません。(^^;
なので、以降のハードウェア設計のために直接的に参照できるような別のレファレンスが必要になりますが、それをアーキ・レファレンスと呼ぶことにしたのでした (3-1節)。そうすると、機能レファレンスからアーキ・レファレンスに変換する作業がタスク分割 (2-1節) になります。
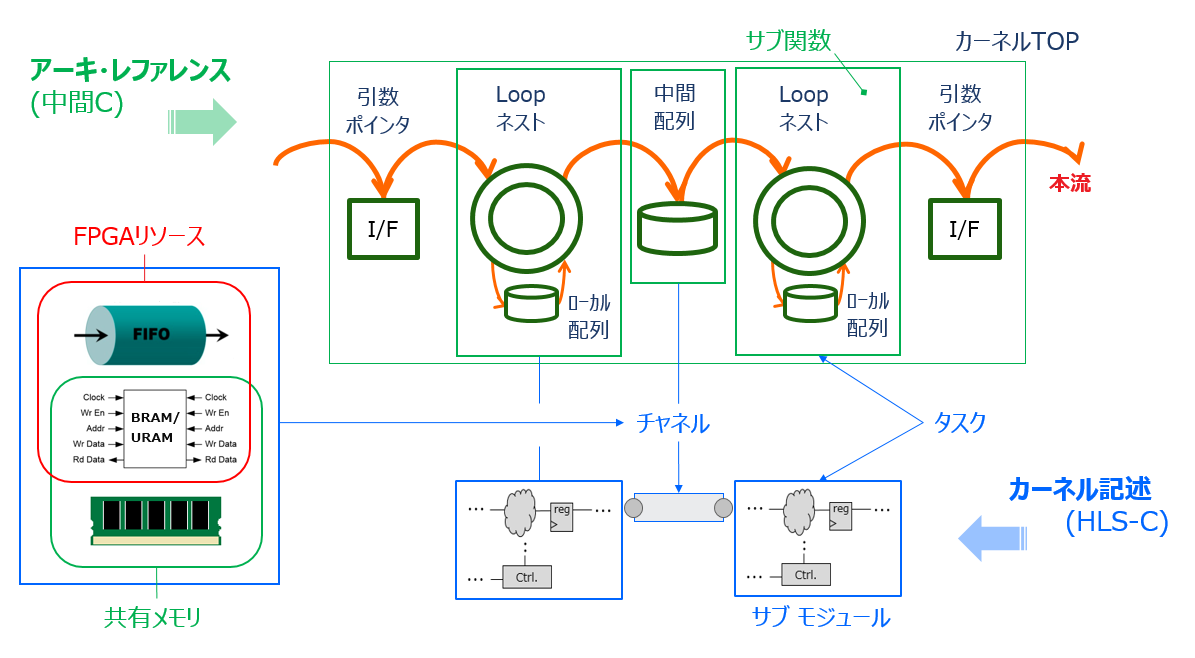
タスクの概念は上の図に示す理解で、C/C++ 記述の観点ではアーキ・レファレンスのサブ関数に、ハードウェアの観点ではカーネルを構成するサブ・モジュールに、1:1で対応します。各サブ・モジュールの設計はそれに対応するサブ関数を参照して行います。その意味で、タスク分割の作業はすでにハードウェア設計です。
詳しくは2-1節で説明していますので、内容を忘れられた方はそちらをご覧ください。
部分から全体へ (カーネル開発)
タスク分割の結果、FPGA をターゲットにアクセラレータ化の意義があると判断されれば (ということは、もちろん、意義無しのケースもあって (2-1節)、大事なのはそこの見極めです)、そこからはボトムアップで設計を積み上げていくフローの話になります。
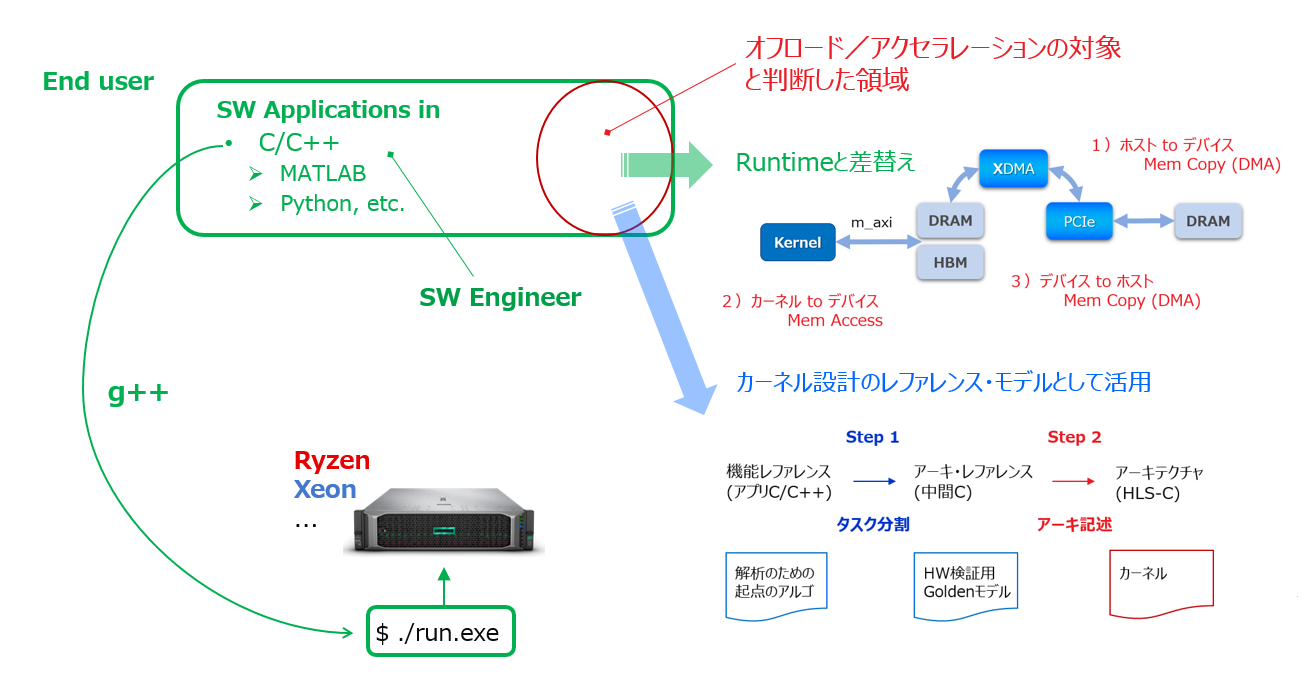
上の図は本節の前半の話を1枚にまとめたような内容になっていて、高性能化のために元のアプリから切り出したアルゴのルーチンが、一方ではアクセラレータ実装後の Runtime プログラムと差し変わり、もう一方ではカーネル設計のためのレファレンスの起点になる、という二つの方向を示していますが、話は後者の続きになります。
もし仮に今、カーネル記述や Runtime プログラムが一応は完了した状況だったとして、そこから Vitis を実行して Alveo 挿しのサーバー上でアクセラレータを実行できる状態になるまでのフロー全体を、下の図で示しています。この前の図からの続きとして眺めると、意味が分かり易くなると思います。
図は筆者の自作ですが、時間の都合で翻訳が間に合わず英語のままですみません。ご覧いただければすぐ分かる内容かとは思います。
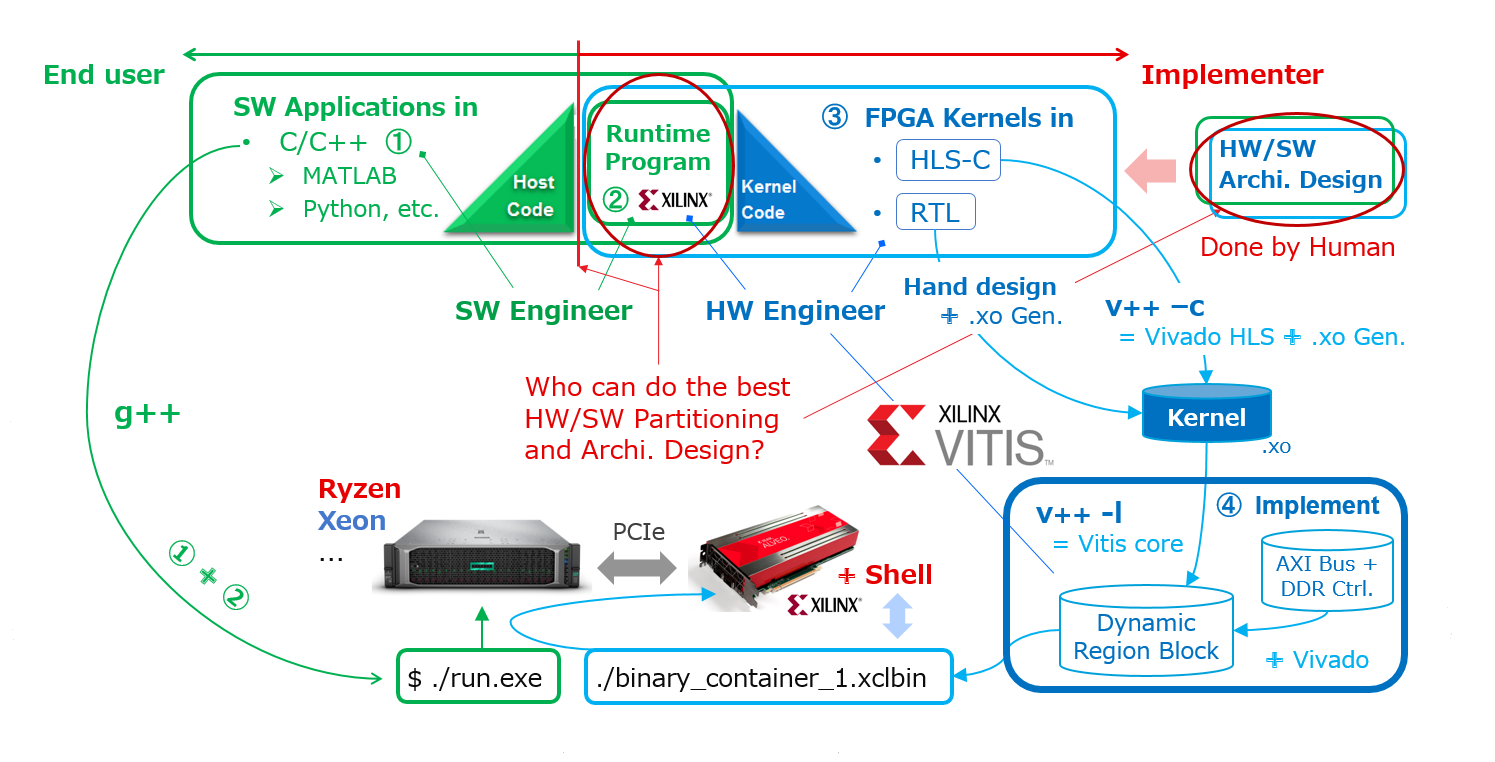
Vitis には自身のエンジンもありますが、それ以外は Xilinx の EDA ツール群のスーパーセットになっていて、Vitis がそれらの実行を制御します。そのためのコマンドとして v++ が用意されていますが、Vitis フロー実行の制御は全て v++ とそれに対するオプションを使って行えます。
Xilinx としては g++ との対比の図式で v++ を見せたいのだと思います。Vitis による実装には GUI 操作と Makefile によるスクリプト実行の二つのやり方がありますが、使い始めは全てのツール作業を GUI で行って、慣れてきて以降は、実装は Makefile で、結果の解析は GUI で、という使い分けをすると、ツールを使う作業をより生産的に進められるかと思います。GUI だと実はその裏でどんな処理を行っているか見えにくいですが、Makefile に自分が理解している内容だけをスクリプティングすれば、Makefile に記述した内容しか Vitis は実行しないので、実装結果に対してコントロール出来ている感も得られます。
HLS カーネルの場合には、Vitis の実行を開始するとまず v++ -c (-compile:コンパイラー) が起動しますが、カーネル記述の HLS-C から高位合成で RTL を生成する Vivado HLS と、その RTL を Vitis がプラットフォームに接続するために必要な情報、さらに後の論理合成や配置・配線で必要になる設計制約情報まで含んだパッケージである .xo ファイルにまとめるためのユーティリティ、それら二つの実行を v++ -c コマンド一つで行えます。
RTL カーネルの場合には、HLS カーネルでは HLS-C から HLS が自動生成する RTL を、人手で準備することになるので v++ -c は実行しませんが、.xo ファイルを作成するためのユーティリティだけ実行します。
カーネルの設計情報である .xo ファイルが用意されると、それを受けて今度は v++ -l (-link:リンカー) が起動され、本節の前半で見たように、カーネルと Shell を繋ぐためのデータ・ムーバー部品の RTL をくっ付けて Dynamic Region のデザイン TOP を作成し、それを Vivado に渡して論理合成と配置・配線を経て、その部分のビットストリーム・データ (.xclbin) が生成されます。
Vitis を実行するだけでカーネルから1チップ化まで一気通貫ですが、その前にはもちろん、カーネルの設計 (記述と検証) が済んでいないといけません。
HLS カーネルの設計には Vivado HLS を、カーネルとデータ・ムーバーから成る Dynamic Region 部の実装と検証に Vitis を用います。その様子を下図で示します。
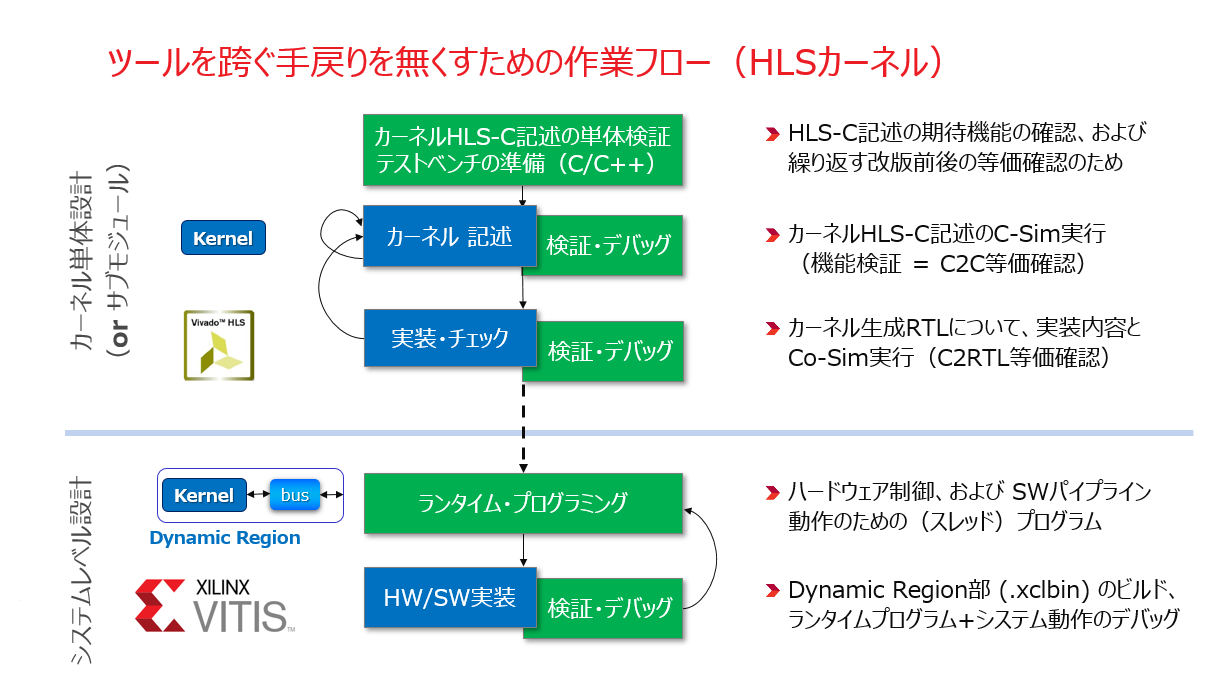
このフローで起きる手戻りは本節の冒頭で触れた悪い手戻りになるので、それを無くすような手順を踏んで作業を進める必要があります。
まず HLS カーネルのデザインは、Vivado HLS 上で完全にフィックスしたことを確認した上で Vitis のフローに渡します。そのために、HLS-C で記述/実装した内容を検証するためのテストベンチを用意した上で、その機能検証を C-Sim で、HLS で生成した RTL の HLS-C に対する等価検証を Co-sim で行います (1-2節)。
そのようにして検証済みのカーネルを Vitis に渡した後の検証は、ハードウェアとしてはカーネルにデータ・ムーバーを加えた Dynamic Region の TOP に対して行う図式になります。その検証も Vivado HLS でやったのと同じように行いますが、その前に、Vivado HLS 向けに用意したカーネル検証のためのテストベンチを、今度はシステムレベルの文脈で1チップ HW/SW アクセラレータとしての検証が出来るよう、Runtime プログラムも含めた形に変更しておく必要があります。
準備した Runtime プログラムは、Vitis 上で行う検証でも、実機で実行するにも、その内容は終始変わりません。Runtime プログラムにとっては、ハードウェア動作の実態である .xclbin の内容がどのようなモードで実行されるのかは分かりません。
検証対象のハードウェアのスコープは、Vivado HLS ではカーネルだったのが、Vitis ではカーネルとデータ・ムーバーを併せた Dynamic Region 部になります。
そのハードウェア動作モデルとしては3つあって、一つは C モデル、二つ目は RTL モデル、三つ目がハードウェアそのものです。
HLS カーネルの場合、C モデルによる検証 (sw_emu:ソフトウェア・エミュレーション) で Runtime プログラムのデバッグをクイックに済ませます。
RTL モデルによる検証 (hw_emu:ハードウェア・エミュレーション) は、検証済みのカーネルを Vitis がデータ・ムーバーと繋いだ経緯で存在する Dynamic Region 部の内容がおかしくないかの C2RTL の等価確認のために行います。特に、カーネルのアクセス先になるデバイス・メモリのバンクを任意に指定しているような場合は、その意図が反映されているかどうかの確認にもなります。
RTL カーネルの場合には、Cモデルはもちろんないので、HLS カーネルでは C モデルと RTL モデルの二つに分けて行った検証を、後者に集約してまとめて行う形になります。
ここまでお話した、「カーネル設計・実装と検証 → 1チップ HW/SW 実装と検証」の作業フローでは、あたかもカーネル設計は全体を一気に記述して行うような印象を持たれたかも知れないですが、それは現実的なやり方ではありません。
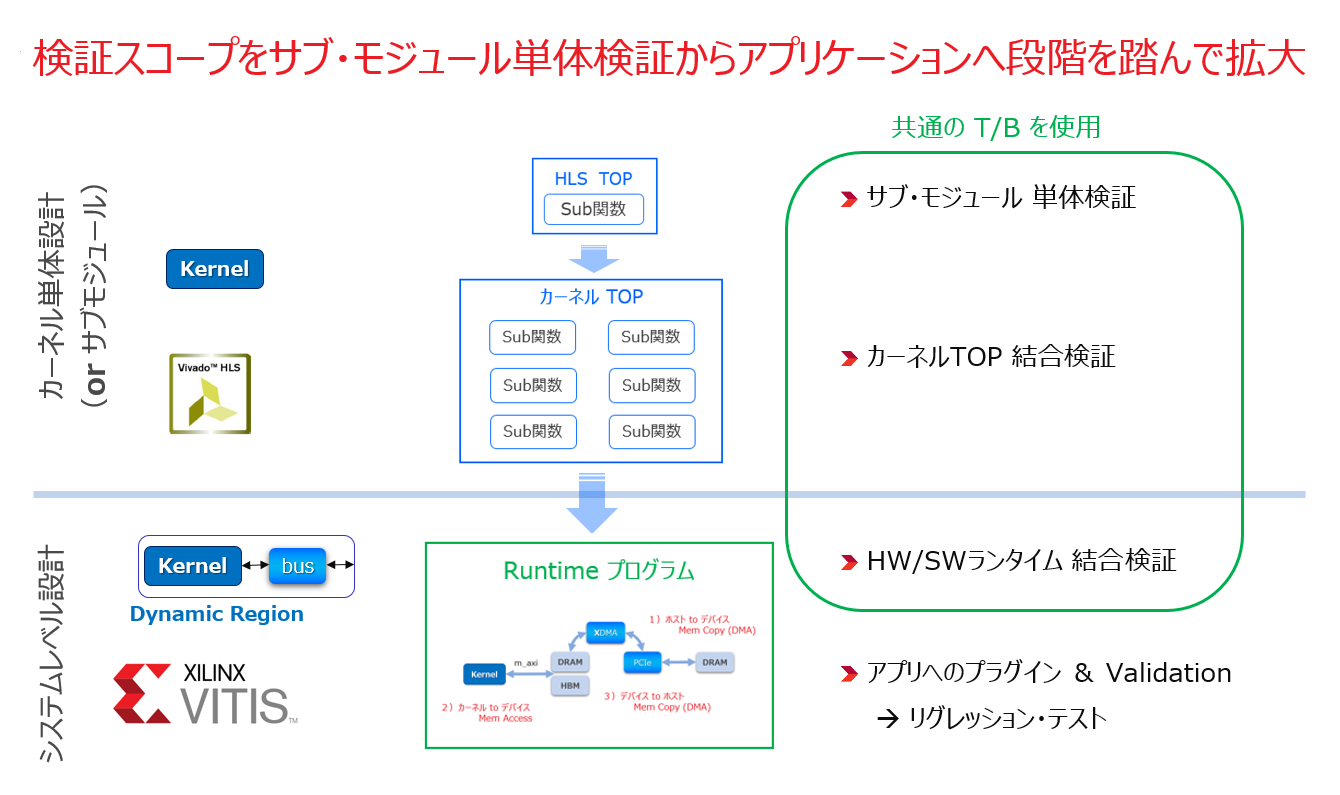
設計はボトムアップで積上げる、と言ったときのボトムにあるのはカーネルではなく、それを構成する一つ一つのサブ・モジュールになります。RTL 設計でもブロック (サブ・モジュール) 毎に検証を進めていくのと同じです。以下の図はその様子/流れを示しています。
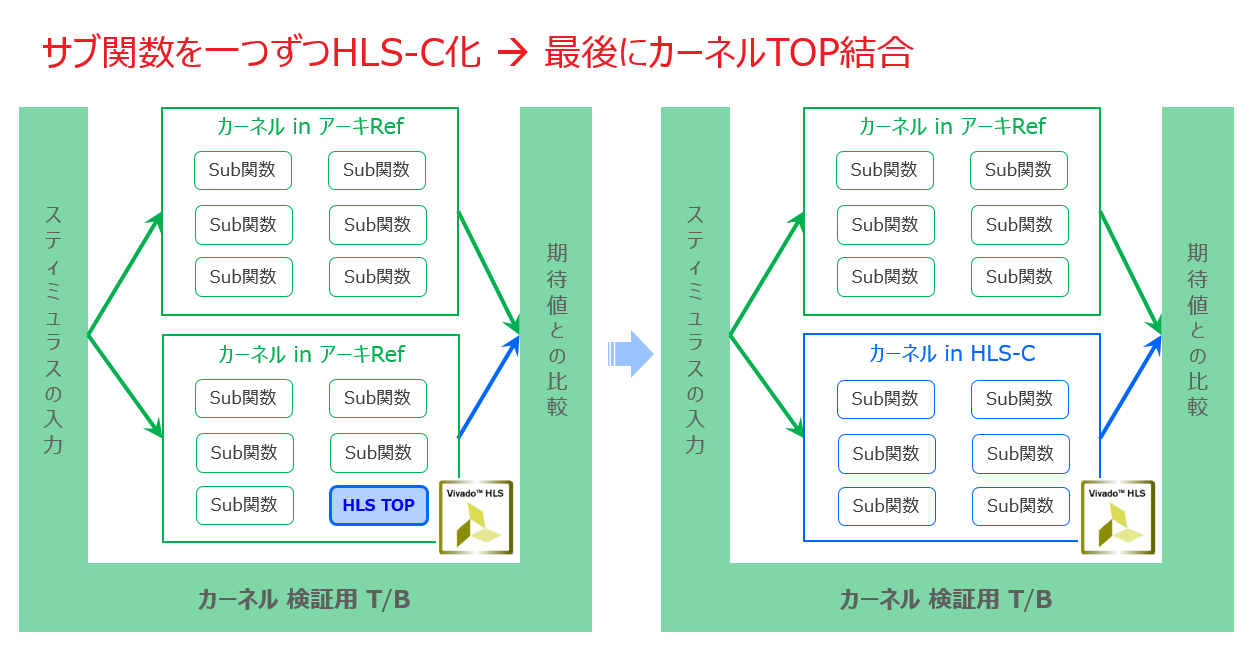
ということで最後は、ボトムアップで検証を進めていくためのテストベンチ (T/B) の話になります。
以下の3つのレベルで検証が必要ですが、可能であればテストベンチはそれぞれの検証のために別々なバージョンを用意するのではなく、次の図で示すように、共通で済ませたいものです。
- カーネル内の各サブ・モジュールの単体検証
- 単体検証済みの全てのサブ・モジュールを含むカーネル TOP の結合検証
- カーネルと1チップ結合後の HW/SW アクセラレータとホストとの結合検証
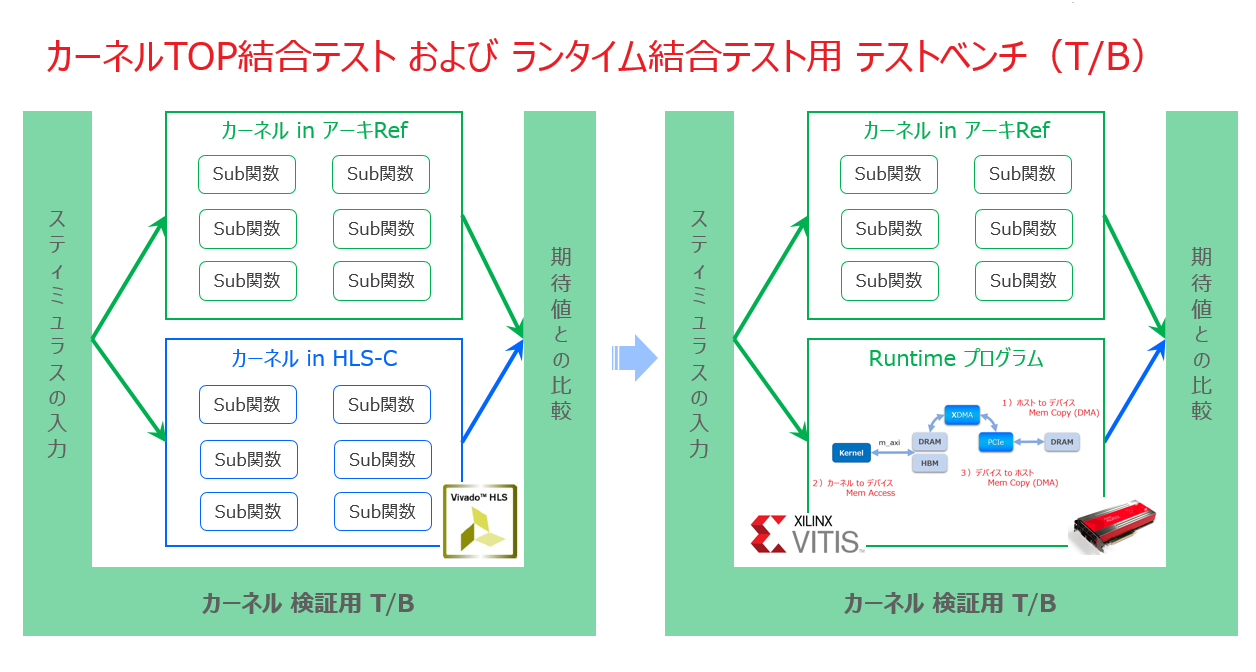
Vivado HLS 向けに用意したカーネル検証のためのテストベンチを、Vitis 向けの1チップ HW/SW アクセラレータ検証にも共通して流用できるようにするのに、Runtime プログラムも含めた形に多少の変更が必要になるという話は、先に述べた通りです。
各サブ・モジュールの検証についてはどうでしょうか?これもテストベンチを別に用意するのではなく、TOP 検証と同じものを用いて、下の図のようにカーネルのアーキ・レファレンスを二つ並べ、サブ・モジュールに対応する HLS-C のサブ関数を一つ一つ差替えながら検証を潰していき、そのまま TOP の結合検証まで持っていくというやり方が可能ならそうしたいです。
アプリに精通する専業のインプリメンターであればそのようなテストベンチを用意できるはずだと思います。
サブ・モジュール単体の高位合成と検証の際に関心があるのはコアの内容だけなので、その引数はポインタあるいは配列のままで、それらに対してインタフェース合成用のプラグマを当てる必要は無いです。
カーネル TOP として全てのサブ・モジュールを繋ぎ合わせる際には、データフローに該当するサブ関数の引数および対応する中間配列を hls::stream<> に変更する必要があるでしょう。カーネル TOP 関数の引数には、カーネルのインタフェースとして期待するプロトコルが実装されるよう、適切なプラグマを当てます (1-2節)。
補足をもう一点。HLS-C のサブ関数はカーネル TOP 下でハードウェアとしてサブ・モジュールになる階層を意味するので、そのモジュール化の意図を明確に Vivado HLS に伝えるために、各サブ関数内の TOP レベルのスコープ下で以下のプラグマを指定しておくと間違いないです。
#pragma HLS INLINE off
逆に、サブ・モジュール化の対象でもないのに、記述内容の見通しを良くするためだけに関数にしているルーチンについては、ハードウェアとしてモジュール階層を持たせない意図を同様に以下のプラグマの指定で Vivado HLS に伝えます。
#pragma HLS INLINE
HW/SW アクセラレータに対して以上の検証を終えたら、それを元のアプリにプラグインで戻し、想定されるユーザーのアプリ使用状況 (カーネルを複製実装したアクセラレータに対してアプリのマルチプロセス実行の確認等も含む) を全てカバーする Validation のテストを行って終了です。
ちなみに、RTL カーネルだと手作業で組まれた背景があるので、結合検証のテストベンチを使ったハードウェア・エミュレーションのレベルでは捕獲できなかったバグが HW だけでなく HW/SW 間の絡みでも潜在している可能性が、HLS カーネルよりも高いと思いますが、その場合にはアプリ実行中の実機デバッグのために観測回路 (ILA コア) を埋め込める ChipScope を適用できます (それも、Alveo に直接 JTAG ケーブルを繋がずとも PCIe を介してホスト・サーバー上で、あるいはそのサーバーに Ethernet 経由で別のマシンから、バーチャルでリモートの制御が可能です)。実用向けの実装だと使用率が高いはずなので、デバッグのために実装上の工夫が必要になるかも知れません。
HLS カーネルによる先行開発の段階ではそこまでのテストはやらずとも、簡易のテストベンチによる結合検証くらいで OK かとは思います。その後は、売り物を目指す実用に向けた RTL カーネルの中で、先行開発の途中で思いついて HLS カーネルでは表現できなかった方式のサブ・モジュールを入れたり、高実装と高性能の両立のためにカーネルをマルチ・クロック化して HLS から流用の複数サブ・モジュールを手で繋いだりと、心ゆくまで RTL 設計を楽しめると思いますが、残念ながら一回で終わりです ww。
本稿にはチュートリアルやマニュアル的な内容を記載しませんでしたが、読者モデルである学生の皆さんがここで得た考え方や心構えの理解をもってユーザーガイド (UG902:Vivado HLS、UG1393:Vitis) に臨めば、今後はあの分厚い内容から自分が必要とする情報を適切に取り出して吸収し、目の前の作業に生かせる状況になっていると思います。
本論としては以上です。
Coffee Break. ヘテロデバイス時代の就活
ふう。やっと、本連載最後の Coffee Break まで辿り着きました (ここまでホントに長かった…)。今回、筆者が飲んだ Coffee の量はさておきww (ちなみに、今回は文章よりもお絵かきの時間が多かったです)、今回のテーマは「ヘテロデバイス時代の就活」です。ある意味、締め括りの言として、実は本連載の中で一番お伝えしたかったコトになるのかなと思っています。
なので、長いです。(^^;
「就活」というくらいなので、目の前に想定しているオーディエンスは「学生」(あるいは転職を考えている「第二新卒」) の皆さんです。
ハードウェア設計やビジネスの実務経験が無い中でここまで読み進んで来られた数少ない学生の皆さんは、大変に優秀で粘り強い資質を持たれ、かつ、恐らくこれからのご自身のキャリアについて、以下のようなビジョンに多少なりともご興味を持たれたのだろうと、筆者は (勝手に) 想像しています。
- 「ノイマン・アーキ」ではなく、ヘテロを相手に「俺様アーキ」を考案して世に広めたい
- サーバー向けのほうがアクセラレータ開発もビジネスも大変そうだけど、その分、面白そう
- World Wide のエコシステム (2-3節) やお客様と、一緒に仕事がしてみたい
その前提で、話を続けます。
あ、その前に断っておきますと、今回の Coffee Break はオジサンである筆者からの、これまでで最も暑苦しい内容になりますので、Coffee はホットよりアイスのほうをおススメしておきます。
仮にそのような3つのキャリア・ビジョンを心に抱いたとして、そのまま大学の研究室に残るのでなければ、皆さんは最終的に就職する企業を (初任給や福利厚生を別にすれば) そのどの辺りを見て/感じて決めますか?
例えば、皆さんが親孝行者で、以下2つの候補があったとして、どちらを選びたいですか?
候補1
・ 親が聞いて安心するような、誰もが知っている、一部上場企業
・ ベイエリアの超高層ビルの眺めのいいフロアに職場がある、オシャレで先進的な外見
候補2
・ 親に言っても通じない、業界の人しか知らない、”非” 上場企業
・ 首都圏でも近くに食事処が Big Boy しかない、片田舎に職場がある静謐な外見
他に何も無ければ、偏見かもしれないですが、大多数の方は生存本能的に候補1) に惹かれるのではないでしょうか?
そこで即断する前に、ちょっと一呼吸おいて、上に挙げた3つのキャリア・ビジョンをちゃんと社員に提示することのデキる企業の要件について、あらためて考えてみることを提案したいと思います。
これまでアクセラレータ開発の話をしてきましたが、2章の冒頭で前置きしたように今回の連載では、高性能化したい計算アルゴのホスト CPU としてエンベデッドよりはサーバー、そしてサーバーでも特にデータセンター向けの開発とビジネスに求められる課題 (技術と組織) の話を意識的に優先しました。
2-3節「そもそもハードウェア化すべきなのか?」でお見せした中で、データセンター向けのエコシステムの全体像を示すスライドをこちらでも掲載します。
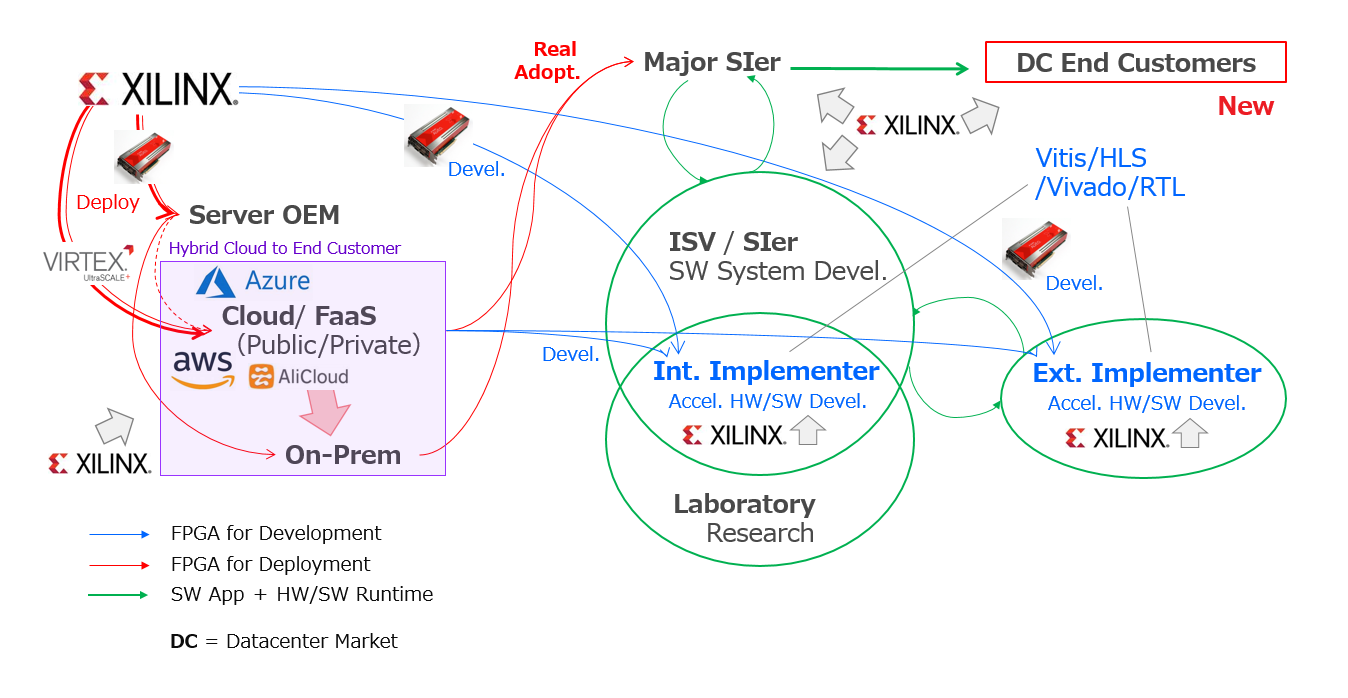
FPGA/ACAP を使い、世のため人のためになる HW/SW アクセラレータをデータセンターのエンドカスタマーにシステムの要素として届けられるようになるまでの要件について2-3節で論じましたが、それをこれから就活する学生の観点で、もう一度眺め直してみましょう。
・FPGA/ACAP によるデータセンター向けのアクセラレーター開発は、前人未踏の世界
・そこでエンドカスタマーにシステムを提案・開発・提供するのは、(メジャー) SIer
・SIer は、システム要素を World Wide エコシステム (SIer 自身も含む) から調達する
・FPGA による特定分野のアプリの高性能化は、専業インプリメンターにしか実現できない
・そのような専業インプリメンターは、独自のアーキを核とするサブスク・ビジネスで勝負する
・エコシステムと協業する専業インプリメンターは、BD (Business Development) と開発が一体の複合体として動く
以下の新聞記事は就活する学生/転職希望者に向けたものですが、今の時代に就職/転職先の企業を見極めるためのヒントについて論じています。データセンタービジネスに即して見れば、どちらかというとその上で運営されるサービスを利用する企業側の視点のように読めますが、専業インプリメンターの要件にも通じる話だと思ったので紹介する次第です。
「ソフトウエアをビジネスに」 SmartTimes 大阪大学教授 栄藤稔氏
日経産業新聞 2020/1/8付

これからこの分野に乗り出したいと思う企業にとって、従来の FPGA ビジネスとはパラダイムが全く異なる新しい世界 (そして今後は ACAP に発展) で新規の試みになる活動は、時間軸上では営業/マーケティングの段階に移るずっと前のイノベーション、つまり何年も先を見据えた “投資” として位置付けられると思います。そのために、以下の問題に対する難しい意思決定が求められます。
経営問題1. 成功する保証の無い将来のビジネスに対して、リソースを張る必要がある。
経営問題2. 従来のパラダイムを下地にした縦割り組織と人事評価では、進められない。
企業に求められる資質として、まず経営問題1) に対しては、ファイナンス的な体力と、それを元に投資家に対する優れた IR 能力が要求されます。
中長期的な競争力を目指した投資を考える時、目先の利益に敏感な不特定多数の株主 (投資家) を持つ上場企業よりも、非上場企業のほうが意思決定はし易そうに思えます (もちろん本業の収益があってのファイナンス力が前提ですが)。
上場企業の場合、数年は赤を垂れ流すことが分かっていて賭けに出ることを投資家に納得させられる (企業価値/株価を下げない) ようなマネジメントの器は、よほどのものであろうかと推察します (例えば、世界的な代表例として Amazon.com Inc.とか)。あるいは、本流の事業が安定していてイノベーションを担う研究所を有する上場企業もありますが、今後はそれだけで済む簡単な話ではないような気がしています。
ちなみに、米国に本社を置く、数学計算ソフトや EDA ツール群を開発する MathWorks 社 (MATLAB/Simulink を覚えてますか? 1章の Coffee Break で触れました) はプライベートカンパニー (非上場企業) です。また、筆者が現在籍を置く Xilinx 社は (シリコンバレーはどこもそうなのか) 上場企業です。全然関係ないですが、アルコールや清涼飲料で有名なサントリーは非上場の企業グループ、また、ホテルリゾート開発・運営で有名な星野リゾート社は同族企業です。企業が社会に貢献する手段として上場することに必然性はない、ということが言いたかっただけです。
経営問題2) については、何年も先のあるべき姿を洞察し、現在の姿との間のギャップを測り、それを問題意識として変革を唱え、実際に行動まで起こすリーダーシップ人材と、その主張を受け入れる度量を有するマネジメントの両方の存在が不可欠です。
それも、そのようなリーダーを生む企業文化を、スペックだけ優れた人材を報酬と見栄えの良さでクイックに寄せ集めるだけで終りではなく、長い時間をかけて醸成できたものがベースに無いと、有り得ない状況だろうと推察します。
2-3節で筆者が (誰に向かって話をしているのかよく分からない言い方で) 「そのような企業が日本にどのくらいいそうか…」とつぶきましたが、これから就活を考える学生の皆さんに対してここで繰り返せば、筆者からのコメントとしては、「現時点では、片手で数えるほども無さそうです」になります。
「高位合成と C ベース設計」の話からだいぶ離れましたね (故に Coffee Break 枠なんですが、それも文字数が多過ぎてもはや Coffee Break でもない…)。(^^;
何となく文章のトーンが段々と後ろ向きな雰囲気を醸すように聞こえたかも知れませんが、違います。そのような難易度の高い要件をクリアできる企業って、尊くて貴重ですよねと、共感を得たかっただけです。
ここでその数少ない具体例の一つとして、本連載で長々と述べてきた要件の全てを備え、筆者の知る限り、成功に向けて確実にムーブメントを起こせている専業インプリメンター企業の筆頭である、アイベックステクノロジー株式会社 (以降、IBEX) について、これまでの活動も含め、ご紹介したいと思います。
IBEX の HP:https://www.ibextech.jp/
ちなみに、IBEX は ACRi の協賛企業でもあります。

HP にあるように IBEX は元々、放送業界向けに以下の3つのビジネスを展開しています。
・ システム製品/提案
・ IP コア製品
・ RTL 受託開発サービス
そこで培われた映像コーデック/トランスコード技術と資産を元に、データセンターにおける映像配信/伝送および映像制作・編集の分野で新規のアクセラレーション事業を立ち上げるべく、4年も前からリソースを投入して活動を続け、今年の6月には今後のビジネスを見据え「CRO 技術部 (以降、CRO 部) 」という独立の専業部署を新設されました。ホームページの左上には、その事業内容として「CRO ソリューションサービス」が加わっています。
「技術部」とありますが、実際の組織と活動の中身は2-3節やここで述べているような、開発とマーケが一体化した事業部のそれになります。

立上げを開始された4年前は Alveo なんて無くて、U200 相当の VCU1525 カードと、ツールとしては Vitis で統合される以前の SDAccel を使われていました。
当初は既存の RTL 資産を組み合わせて RTL カーネルを構成し、販促のための POC を開発するためのフローを立上げるところからで、アサインされたエンジニアは一人だけでした。
Xilinx Japan 側も当時は SDAccel を含め、高位系ツールの専任は筆者一人でした。いろんな意味で心細い思いをしてたような気がします (どうでもいいか)。
技術の立上げと並行して進められていたのは、いわゆる BD (Business Development) 活動です。その BD を担当された方 (昨年から取締役になられています) が、当時から World Wide のエコシステム (2-3節) とのコンタクト (国内だけでなく多数の海外出張を含む) を重ね、ビジネスの可能性を探り続けてこられました。
本質的に大事な活動で、P.F.ドラッカーも自著の「マネジメント」の中でこう言っています:
“企業の目的は、それぞれの企業の外にある。企業は社会の機関であり、その目的は社会にある。企業の目的の定義は一つしかない。それは、顧客を創造することである。”
IBEX がカーネル開発に HLS を導入し始めたのは昨年の夏頃です。BD 活動の成果としてリレーションを構築できたある SIer との POC 案件の話が挙がったのがその少し前。RTL カーネルの一部に新規機能が必要になり、POC 開発に与えられた期間が短かったことから、急遽 HLS 導入の話になりました。そこから少しづつ HLS 適用の範囲が拡がり、IBEX 内の HLS ユーザーも増えていきました。
IBEX は元々筋金入りの “超” RTL 設計者集団だったので、著者からは恐ろしくて HLS の話など口にしたことは無かったと記憶していますww。ですがその POC 案件がきっかけとなり、フタを開けてみると、機能レファレンスの C/C++ から RTL 設計に移る前に、アーキ検討の成果物として “アーキ” レファレンスと呼ばれる中間 C/C++ のモデル (2-1節、3-1節) を用意するといった開発手法を取られていたことが分かり、そこにも HLS を適用して全体の開発 TAT を短縮できるではないですか? (ソレ、もっと早く言ってよ) と、話が盛り上がりました。いい思い出です。
そんなこんなで4年前に2名で始めた活動が今では CRO 部へと進化し、現時点で専任が5名、来期にはさらに数名増員される予定とのことです
引き合いが増えて、アーキ設計の人材が足りなくなってきているらしいです。
CRO 部はこれまでの組織とは違い、データセンター向けのビジネスに対応すべく、先述の通り BD/マーケと開発が一体となったチームとして活動されています。BD だけでなくエンジニアの皆さんのバックグラウンドも多様で、それぞれ (良い意味で) 個性的でいらっしゃいます。
特に BD で CRO 部長兼取締役は、最初 IBEX にエンジニアとして入社されましたが、その後 MBA を取得して IBEX 内で BD の道を進まれた方です。
また、部長代理で1エンジニアでもあるプレイングマネージャーの方は、元々はソフトウェアエンジニアでしたが、ハードウェア設計がやりたくて IBEX に入社されています。
そんなお二人がエコシステムと対外的なインタフェースを取りながらビジネスや開発をリードし、CRO 部の精鋭エンジニアチームとワイワイやりながら、案件毎に (技術と経済の両面で) 最適解のアーキと実装を追及されています。
ところで IBEX には親会社がいて、株式会社日本デジタル研究所 (略称:JDL) という “非” 上場企業です。会計事務所向けに、財務・税務の会計ソフトだけでなくハード (サーバー:基板から筐体、電源まで!) も含めたシステム全てを自社開発し、Web サービスまで含めたソリューションを提供するという、とてもユニークな会社です。
JDL の沿革に記載がありますが、1991年に東証二部に上場、1993年から東証一部上場に指定替えの後、2016年の MBO (Management Buyout) によって2017年に非上場化しています。IBEX 以外のグループ会社に航空運送会社もあったりして、いろんな意味で興味深い企業です。
そんな IBEX の所在地ですが、川崎市麻生区の黒川という、里山や果樹園があるような静かな場所にあります。近くにある食事処が、オフィスのある丘から降りて街道沿いにある Big Boy だけという。人によっては片田舎と感じられる方もいらっしゃるかも知れません。でも、小田急線に乗れば黒川から新百合ヶ丘まで7分、新宿でも最短で40分弱のロケーションです。
IBEX の事業内容が醸す雰囲気と所在地のそれが一致しない感じですが、筆者は田舎出身だし田舎好きなので、大崎に出勤する身としてはむしろ羨ましいくらいです。電車もラッシュ時の方向が逆になるので、満員電車の中ですし詰めになっている人達とすれ違いに自分は座って通勤できるというのは、優越感が得られて気分も良さそうです。いろんな面でありきたりではないところが、筆者的には好印象です。
今お話しているような新しい分野に乗り出すために、企業としてどのような資質や投資活動 (人と時間) が求められるのか、具体的なイメージを持ってもらえることを期待して、一番成功に近い位置に着けている、企業組織としても非常に稀で貴重な存在である、IBEX の話を持ち出しましたが、学生の皆さんはどう思われたでしょうか?
以上のインプットが得られた上で、また最初の質問に戻り、以下の候補2が “実は IBEX だったとして”、あらためて、どちらの候補を選びますか?
候補1
・ 親が聞いて安心するような、誰もが知っている、一部上場企業
・ ベイエリアの超高層ビルの眺めのいいフロアに職場がある、オシャレで先進的な外見
候補2
・ 親に言っても通じない、業界の人しか知らない、非上場企業 “の子会社”
・ 首都圏でも近くに食事処が Big Boy しかない、片田舎に職場がある静謐な外見
データセンター向けのアクセラレータとして俺様アーキを開発し、World Wide に広めていきたいという気持ちが強ければ、ここは生存本能を抑えて候補2を選んだほうがいいんじゃないかな…、ということになろうかと思います。
要は、就職先の経営やビジネスついてよく知り、自分とも向き合ってよく考えた上で決めましょうということ。そしてその決断について、自分の周りに対する IR 活動も自分でちゃんとやるということです。
もう一声欲しいですか? CRO 部の前身から4年に及ぶ BD 活動の結果、現在の顧客は日本だけでなく、アジア・米国・ヨーロッパとの取引もすでにいくつか出てきています。
さらには、老若男女の誰もが知る世界的な超有名企業が、IBEX への仕事の依頼でクパチーノからわざわざ海を渡ってぞろぞろと黒川詣でにやって来たこともあります。クパチーノでは今、IBEX のいる黒川は “Black River” で通っているらしいです (IBEX といえば Black River、Black River といえば IBEX)。
まだ足りない? そういえば一つ言い忘れていましたが、昨年の夏、黒川駅近くにローソンがオープンしましたwww。
コンビニだけでなく、中にカフェやコ・ワーキング・スペースを含むキャビン風の複合施設になっています。なかなかいい感じですよ♪
ネスティングパーク黒川の HP:http://nestingpark.jp/
いやいや、そういうことではなくて、近くに商業施設があることよりも、空気が美味しくて、都心から離れてるところが、逆にいいんですよ。ナンダカ、独り善がりな主張で締まらない感じですが、Coffee Break としては以上です。
あとは、IBEX の CRO 部の皆さんに相談してみてください:cro@ibextech.jp
参考情報
「はじめに」で断りましたように、この3章分の記事はアクセラレータ開発の心構えや考え方の話がメインで、チュートリアル的な内容を執筆することは致しませんでした。それに、他で公開されている素晴らしいコンテンツがすでにありますので、本連載と関わるものをここでいくつかご紹介させていただきたいと思います。
[ACRi ブログ] 4ビットカウンタでわかる FPGA のための論理回路 入門 (全5回)

本連載の「はじめに」でも触れましたが、論理回路/RTL 設計と FPGA 実装フローが初めての学生の方は、最低限この内容を前提としてしっかりと押さえておきましょう。
FPGA の部屋

日本中で誰よりも早く新しいツール機能や作業フローを試され、ここでその内容を惜しみなく公開されています。多くの方々がまず参考にされるブログサイトです。関心のある内容のキーワード (複数並べて絞込みも可) をページ右上の [検索] に入れてリターンすると、たくさんのお役立ち情報がリストアップされます。
このブログを始められて今年で15年。9月に記事5,000本を突破されました (驚異的な偉業です)。筆者を含め、これまでにどれだけ多くの方々がお世話になってきたかを思うと、頭が下がります。
[ACRi ブログ] AWS F1 で始めるサーバーサイド FPGA (全5回)
本連載のところどころで補足情報として部分的に参照していましたが、全5回分を通しでも読まれることをお勧めします。Alveo や F1をターゲットとするアクセラレータ開発のうち、カーネルの (そのものの説明もありますが主にその) 外側の話を全てカバーしています。この連載と併せて読めば全体像がよりクリアになると思います。執筆したのは Xilinx Japan が誇るスーパーエンジニアであり、ACRi ルームの副室長でもある「安藤 潤」さんです。以後、お見知りおきを。
あとがき
今年の8月20日に、「スバルの新型アイサイト X の心臓部にザイリンクスの FPGA を採用、新型レヴォーグを支える Zynq UltraScale+MPSoC」と発表が出ていましたが (こちらはエンベデッド向けの話)、このブログの1章の執筆に入ったちょうど10月9日に「AMD、ザイリンクス買収で交渉が進んだ段階に」とのニュースが飛び込んできました (こちらはサーバー向けの話)。このブログでも触れたヘテロへのトレンドの話に同期するイベントだと思い、そのニュースのタイミングにはちょっと驚きました。
AMD といえば、将棋の藤井聡太さん (王位・棋聖) が自作 PC の CPU に、Ryzen Threadripper 3990X を使っているという記事が出ていましたね。

それはさておき、この度は Xilinx からの第3期連載 (全5回) にお付き合いいただきありがとうございました。その中で特に全3章の3回分については、筆者の言いたい放題の内容に (そして余計な一言が多過ぎる長文に) 呆れ果てて、最後まで読み通された読者がどのくらいいるのか、考えてみると今さら寒気がしますが、それでも何か新しい理解が得られ、さらに学んで/行動を起こしてみようと思い始める方がいらっしゃるようでしたら、幸いです。
FPGA を含むヘテロデバイスの話がこれから本格化していきそうな、その直前の過渡期のような今、ノイマン・アーキに代わる “俺様アーキ” を志す方々、組織変革を志す方々が増え、両者のコミュニケーションが活発になることを、そしてその成果物としての高性能 HW/SW が世の中のニーズに応え、より多くのソフトウェアアプリケーションの中に適材適所で利用される時代が早く訪れることを願いつつ、本連載の最後とさせていただきます。
(おしまい)
ザイリンクス株式会社 黒田成一