
みなさんこんにちは。ACRi ブログ第1期の4番目のコースを担当するティエムです。
このコースは、FPGA やアダプティブコンピューティングの研究論文をその著者が紹介するシリーズの第一弾です。科学技術の進歩のために、研究者は日々難題に取り組んでいます。 アダプティブコンピューティングの国際会議で発表された研究成果から、選りすぐりの研究論文を紹介します。
このコースでは、2017年5月に開催された FPGA の主要な国際会議 FCCM (The 25th IEEE International Symposium on Field-Programmable Custom Computing Machines) で発表した論文 High-Performance Hardware Merge Sorter (参考文献 [1]) を紹介します。
ソーティングとは?
たくさんのデータをある決まりにしたがって(例えば値が小さいものから大きいものの順番で)ならべ替える処理をソーティング (sorting) と呼びます。ソーティングはデータ処理の基本的なオペレーションです。普段の生活で、また検索エンジンやデータベースといった複雑なアプリケーションで用いられます。
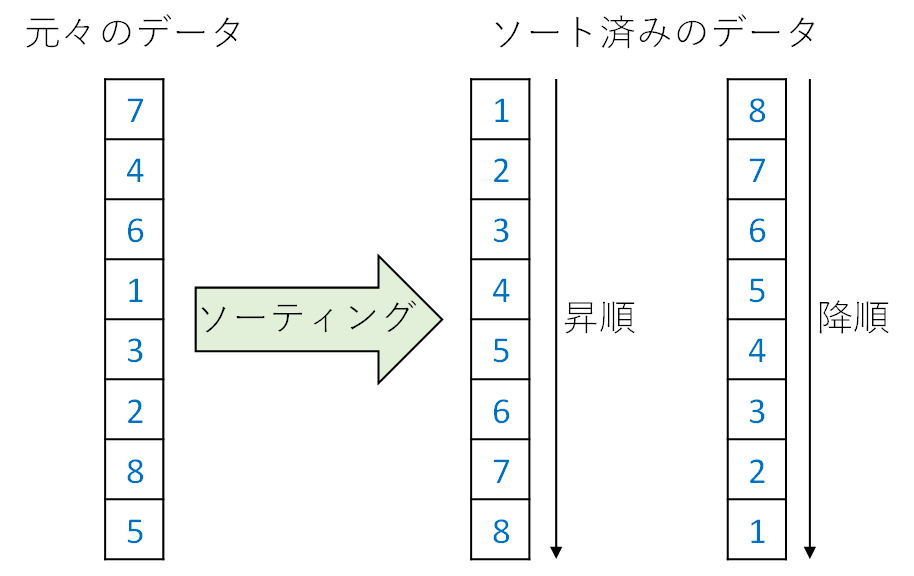
上図に示すように、7, 4, 6, 1, 3, 2, 8, 5 という入力は、ソーティングされて一定の順序で並ぶことになります。1, 2, 3, 4, 5, 6, 7, 8 という値の小さい方から大きい方へ順に並べることを昇順 (ascending order) と呼びます。逆に、8, 7, 6, 5, 4, 3, 2, 1 のように値の大きい方から小さい方へ順に並べることを降順 (descending order) と呼びます。このブログでは昇順のソーティングで説明していきます。また、データ型として整数のみに注目します。
ソーティングは複雑なアプリケーションの重要な要素としても利用されます。例えば、データをソートすることで、探索が簡単になります (二分探索アルゴリズム)。また、最近は様々な機械学習のアルゴリズムやグラフ解析のアルゴリズムのための主要な計算カーネルである疎行列積 (疎行列とは成分のほとんどが0である行列のことです) を効率的に処理するために、ソーティングを用いる方法が提案されています (参考文献 [2])。
このような基本的でよく用いられるソーティングの高速化は重要な課題で、コンピュータサイエンスの黎明期から盛んに研究されてきました。現在、 IoT (Internet of Things) 機器や SNS (Social Networking Service) の登場により、扱うデータ量が激増しており、ソーティング性能の向上は更に重要な課題になっています。
これまでの多くの研究は、汎用 CPU と GPU でのソートアルゴリズムの改善に焦点を当ててきました。しかし、ムーアの法則 (単一チップに集積できるトランジスタ数の指数関数的な増加、すなわちトランジスタの微細化) とデナード則 (微細化が進むにつれて、 トランジスタはより速くなり、消費電力が少なくなること) の終焉により、 CPU と GPU の性能向上はゆるやかになっています。近年の CPU の年間の平均性能向上は約 3.5% と低いことが知られています。
そのため、ソーティング処理のためだけのハードウェアアクセラレータが研究されています。近年の研究成果は、 CPU と GPU 用に最適化された方式と比較して、FPGA を用いたソーティングアクセラレータの高い性能を明らかにしています。
ハードウェア・マージソータ (Hardware Merge Sorter, HMS)
これまでの数十年で、CPU におけるソーティングの方式は大幅に改良されています。バブルソート、挿入ソート、マージソート、クイックソートなどの様々なアルゴリズムが提案されました。この中で、ハードウェアの実装に相性が良いのがマージソートです。そのため、提案された FPGA ソーティングアクセラレータのほとんどはマージソートの考え方を採用しています。
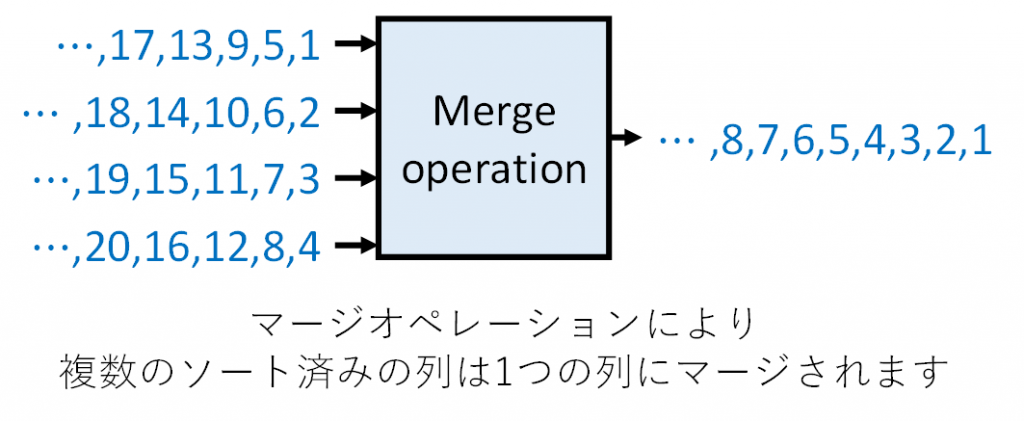
具体的には、これらのアクセラレータは上図のマージオペレーションに基づきます。この例では、1, 5, 9, 13, 17, … というソートされた系列と、2, 6, 10, 14, 18, … というソートされた系列と、同様に他の2つのソートされた系列との合計で4つの系列をマージ(結合)して、1つのソートされた系列 1, 2, 3, 4, 5, 6, … を作ります。このようにいくつかのソートされた系列を結合して1つのソートされた系列を生成する処理をマージオペレーションと呼び、これに基づくソーティングアクセラレータをハードウェア・マージソータ (Hardware Merge Sorter, HMS) と呼びます。
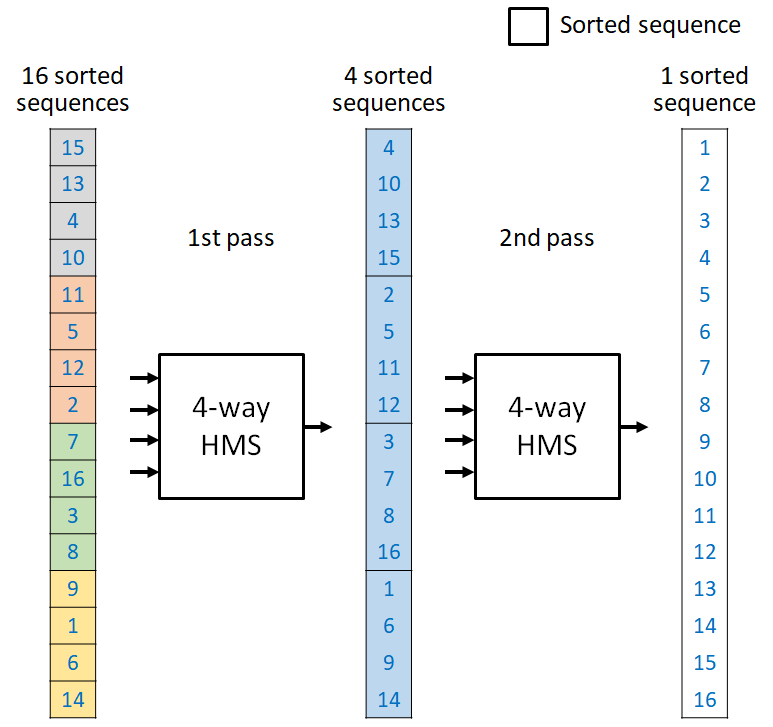
上図は HMS により16個のデータをソートする例を示しています。ここでは HMS が4つのソート済みの系列をマージできるとしましょう。これを 4-way HMS と呼びます。
ソートで扱うそれぞれのデータのことをレコードと呼びます。1個のレコードは長さ1のソート済みの系列と見なすことができます。すべてのレコードを HMS に入力することで、上図の中央に示す4つのソート済みの系列 (それぞれの系列は4個のレコードを持ちます) が得られます。例えば、最初の系列はソートされた 4, 10, 13, 15 のレコードを、次の系列はソートされた 2, 5, 11, 12 のレコードを持ちます。
これらの 4つの系列をもう一度 HMS に入れることで、16個のレコードは完全にソートされた1つの系列を出力します。この系列が上図の右に示すソートされた系列です。
ここで、HMS の性能について考えましょう。HMS の性能を向上させるためには次の2つの要素に注目する必要があります。
- 同時にマージできる系列の数
- マージスループット
上図の 4-way HMS は同時に4つの系列をマージできるため、すべてのレコードをこの HMS に2回だけ入力する必要があります。一方、同様の 16-way HMS (同時に16列をマージできる HMS) を用いると、入力する回数を1回に減らすことができます。すなわち、ソーティングの性能は2倍になります。一般に、同時にマージできる系列の数を増やすことで性能を2倍に向上させるためには、 K-way HMS を K x K -way HMS に変更する必要があります。(つまり K-way HMS のソーティングの性能はほぼ log2K に比例します。)
2番目の要素の「マージスループット」は回路の動作周波数と1クロックサイクルあたりに出力されるレコード数に比例します。そのため、高い動作周波数を達成しながら各クロックサイクルに多くのレコードを出力できる HMS が良いものとなります。一般に、マージスループットが N 倍に増えると、ソーティング性能は N 倍に高速化されます。
HMS の最も簡単な形は2つのソートされた系列を1つの系列にマージする回路です。これをマージロジック回路と呼びます。幾つかのマージロジック回路を用いて一般の HMS を構築できます。例えば、下図の右に示すように、4-way HMS は3つのマージロジック回路で構築できます。

つまり、HMS の性能を向上するためにマージロジック回路がとても重要な役割を果たしています。 FCCM 2017論文で、私たちは高性能なマージロジックアーキテクチャを提案しました。これにより、当時の最速の FPGA ソーティングアクセラレータと比較して、3倍を超える高い性能を達成しました。
まとめ
今回は FPGA ソーティングアクセラレータの背景と基本的な考え方を説明しました。特にマージロジック回路の性能が重要になることに注意してください。
次回は、私たちがベースラインとして用いた方式と FPGA でソーティングを高速化するための鍵となるアイデアを解説していきます。
東工大 Thiem Van Chu
参考文献
- Susumu Mashimo, Thiem Van Chu, and Kenji Kise, “High-Performance Hardware Merge Sorter,” The 25th IEEE International Symposium on Field-Programmable Custom Computing Machines (FCCM), May 2017.
- Zhekai Zhang, Hanrui Wang, Song Han, and William J. Dally, “SpArch: Efficient Architecture for Sparse Matrix Multiplication,” The 26th IEEE International Symposium on High Performance Computer Architecture (HPCA), Feb. 2020.