
みなさんこんにちは。この記事は ACRi ブログの Deep Learning コースの第10回目です。
最終回となるこの回では、より大規模なネットワークに対して推論を行う際に問題となる計算量の増加をどのように解決すべきか、一般的に使用されている方針を述べていきます。
演算コストの低下手法
まずは演算コスト自体を低下する方法について述べていきます。
量子化
量子化は、通常 fp32 で構成される重みやアクティベーション (各層の入出力) のビットを減らすことです。ディープラーニングでは推論時において学習時よりも低いビット精度で処理が可能であることが知られており、モデルにもよりますが 8bit の固定小数やそれ以下のビット数の固定小数でも実用的な精度で処理が可能なことがあります。FPGA では1bit 付近の低精度ネットワークにおいて、畳み込み演算を LUT によるテーブル引きに置き換えられるため、特に相性が良いです。
枝刈り
枝刈りは、畳み込み層などで用いられる重み行列のうち、値が0に十分近いものを間引く (0にする) 処理です。係数が十分0に近いものは畳み込み演算で最終的な結果に与える影響が非常に小さくなるため、これを 0 としても推論結果に大きな影響は与えません。実際はどこまで枝刈りするかの閾値等のパラメータを設定し、テストパターンを与えて許容できる誤差範囲を検討していきます。
枝刈りは、主に2つの粒度で適用されます。
- 粗粒度: チャネル単位
- 細粒度: 係数単位
1 の 粗粒度な枝刈りを行うと、単純にチャネルの削除となるので計算するハードウェアとしては特に意識せずとも高速化が可能です。一方、2の細粒度な枝刈りを行っても行列のサイズはそのままで内部に0の要素が増えるだけなので、高速化をするためにはハードウェア側に0要素をスキップするような機構が必要となります。
ここではこの程度に留めますが、他にもモデルそのものの演算量が減るようなトポロジ調整など様々な方法で計算量を減らすことができます。
FPGA 上での最適化された DNN フレームワーク
GPU でディープラーニングを行う際には、フロントエンド側のフレームワークとしてどれを選ぼうとも、バックエンド側は NVIDIA により最適化された cuDNN ライブラリ が動いていることがほとんどです。cuDNN ライブラリは非常によく最適化されているため、GPU のピーク性能をほとんど引き出すことができます。このため、畳み込み関数などは自前で実装せず、裏でこれらのライブラリを使うことが一般的です。
FPGA においても同じことが言え、例えば Xilinx では Vitis-AI という推論フレームワークを提供していますし、Intel FPGA では OpenVINO ツールキット を提供しています。本節では、Vitis-AI でエッジデバイス向けに使用される DPU という IP のドキュメント内の公開情報から、前回の記事までで作成してきた推論コードと比べてどれくらい高速に推論処理が可能か見ていきたいと思います。
DPU
DPU は Deep Learning Processing Unit の略であり、名前の通りディープラーニング用のプロセッサとなります。これまで作成してきたような各層を処理する回路を並べるアーキテクチャとは異なり、DPU では一つの巨大な演算器ブロックを実装し、その演算器ブロック上で層毎の処理を連続で実行することで推論処理を行います。
DPU のハードウェアアーキテクチャは下図のようになります。この図に示すように、DPUでは命令スケジューラなど、通常のプロセッサに近いアーキテクチャとなります。
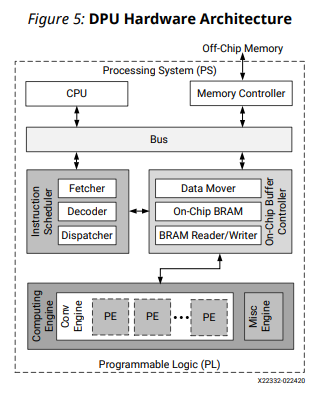
DPU は、8bit に量子化されたネットワークのみをサポートし、そのための量子化ツールは Vitis-AI (旧DNNDK) で提供されます。
以下に、DPU のアーキテクチャのうち、興味深い点をいくつかピックアップします。
データ並列性の抽出
前回の記事では、ピクセル間・出力チャネル間の2軸のデータ並列性を抽出して高速化を行いました。DPU ではそれに加え、入力チャネル間のデータ並列性を抽出しています。
DPU では実装するチップの規模に合わせていくつかのコンフィグレーションを変更可能であり、それらは以下の表で示されます。
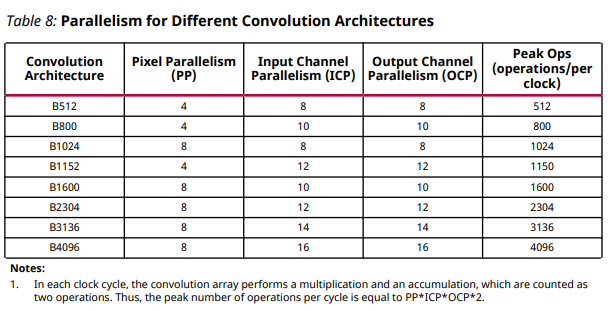
最も性能が高い B4096 アーキテクチャでは、ピクセル方向に8、入力チャネル方向に16、出力チャネル方向に16 で計2048個の演算器が並びます。演算器が2048個なのにトータルで 4096 operations/clock となっているのは、一つの演算器あたり乗算・加算の両方を同時に行うためとなります。
前回作成したアーキテクチャだと最も演算数の多い畳み込み層で 4*8 = 32 個までしか演算器を並べず、2つの畳み込み層合わせて 32 + 16 = 48 個だったので、単純に40倍近い性能差があることになります。
DSP の DDR (Double Data Rate) 化
DPU では 下図のようにDSP のみ2倍の動作周波数として動かすことで性能を向上しています。1サイクルあたりに可能な演算数が倍となるため、DSP の使用数が半減します。
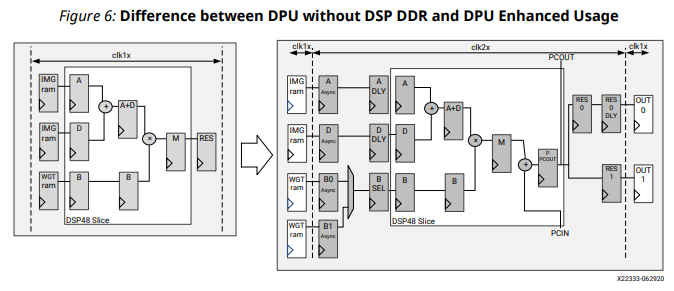
DPU では Zynq Ultrascale+ を主に対象とし、動作周波数が 300~400 MHz となります。
このため DSP は 600~800 MHz のレンジで動き、非常に高速なことが分かります。
特にこのクロックを分ける最適化は今回のように HLS で開発した場合では再現が難しく、RTL でのチューニングが必要となってきます。
他にも、DPU のようなアーキテクチャでは毎サイクル演算器にデータを供給し続けることが課題となるのですが、このあたりもうまく最適化できている印象です。これは筆者の経験談となりますが、1K 画像の 3×3 畳み込みを行った際には、90% 以上のサイクルで演算器が動作できていました (チャネル数が並列数の倍数の場合)。
ここまで最適化された実装を作るのは非常に大変なため、実際にディープラーニングを FPGA 上で行うときには何らかのフレームワーク上で推論を行うと効率が良いでしょう。ただし、レイヤー毎に量子化のビット数を切り替えるようなより最適化されたアーキテクチャを使う場合など、既存のフレームワーク上ではうまく処理できないパターンもあると思います。その際は自分でネットワークを処理するハードウェアを作る必要があるかもしれません。
まとめ
ここまで読んでいただきありがとうございました。
このコースでは、前半6回でディープラーニングの内部ではどのような計算を行っているのか、それを FPGA でどのように実装していくのかを実際のコードと共に解説しました。また、後半4回では実際に高速化を行い、より高速に処理を行うための計算コストの削減手法やアーキテクチャの紹介を行ってきました。
このコースでは実際にコードを書き FPGA 上で処理を行うことを主題に説明してきました。FPGA の開発というと RTL を書くのが大変だったり、ハードウェアを分かっていないといけないイメージがあるかもしれません。ただ最初に作成した推論回路のように、性能さえ気にしなければ通常の C コードに高位合成をかけるだけでも動きました。またその後の高速化では、作成する回路のアーキテクチャこそイメージは必要なものの、主に #pragma を追加するだけで400倍という大幅な速度向上が達成できました。DPU のような最適化されたライブラリを作る場合では依然として RTL で書く必要はあるかと思いますが、ほどほどに最適化されたものを短時間で作ることを目的とすれば、今回のように HLS を使えば大分楽に開発できます。このコースで開発したソースコードは ACRi Room のサーバー上で動作するので、興味がある方はぜひ動かしていただければと思います。
このブログに記載しているコードは https://github.com/fixstars/dnn-kernel-fpga で公開しています。コードの権利、ライセンスに関してはライセンスファイルを参照して下さい。
株式会社フィックスターズ シニアエンジニア 松田裕貴